




“前端埋点数据的采集系列,一共5次分享来实现这个需求交付解决方案。
一、Kafka搭建、配置及生产数据
1、Kafka集群搭建和配置
2、启动kafka集群
kafka_cluster.sh start
使用kafka_cluster.sh脚本,来启动和关闭3台Kafka集群。
#function:kafka集群启动、关闭#!/bin/bashcase $1 in"start"){for node in node01 node02 node03doecho =============== kafka $node 启动 ===============ssh $node "/opt/module/kafka/bin/kafka-server-start.sh -daemon opt/module/kafka/config/server.properties"done};;"stop"){for node in node01 node02 node03doecho =============== kafka $node 停止 ===============ssh $node "/opt/module/kafka/bin/kafka-server-stop.sh -daemon opt/module/kafka/config/server.properties"done};;esac
3、查看Kafka集群topic

查看topic_log已经启动。这是为什么呢?我们并没有启动topic。
因为Kafka集群启动,默认会启动一个名字叫做topic_log的topic。
4、查看Kafka集群是否消费到数据
bin/kafka-console-consumer.sh \--bootstrap-server node01:9092 --topic topic_log
二、消费Flume选型
我们先看一下日志采集流程,现在数据已经在3台Kafka集群里面存储了,Flume组件即Node03对3台Kafka数据做消费。需要配置消费Flume组件。
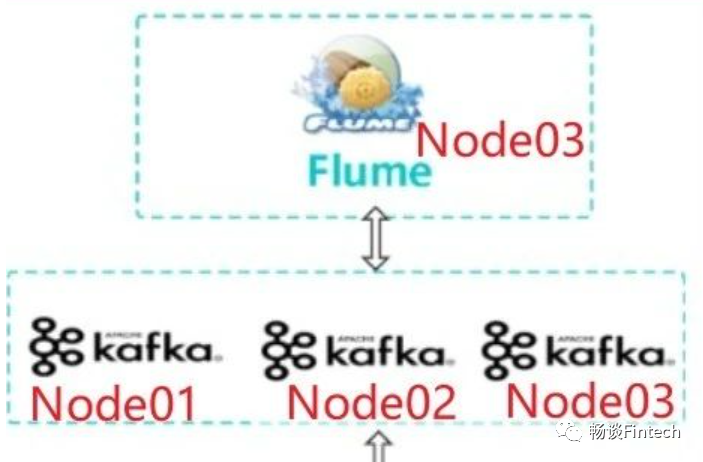
1、消费Flume 的Source选型
2、消费Flume 的Channel选型
Channel:我们选择的是FileChannel,因为Channel 数据会到下一级HDFS上,保证了数据的安全性,不会丢失。Agent进程挂掉也可以从失败中恢复数据。
3、消费Flume 的Sink选型
Sink:我们选择HDFS Sink,因为我们消费的数据采集最终到HDFS上。
三、消费Flume拦截器实现
我们先来看一下Kafka-Flume-HDFS配置架构图:
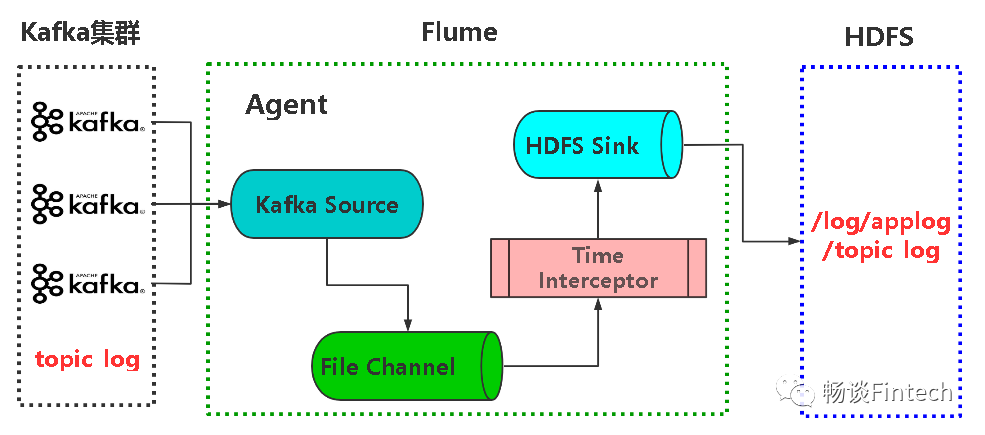
我们从架构图里面看到多了一个TimeInterceptor时间拦截器:因为Flume->HDFS,FLume默认使用的是Linux系统集群的时间,消费Kafka数据后很有可能是第二天了(如果数据是23点59分产生的log,那输出到HDFS很有可能是第二天了),这样HDFS统计这个时间是从第二天才开始,这样不满足需求统计 T + 1的时间。所以这里到FLume组件之前,必须要加上时间拦截器把日志产生的实际时间取出来,然后写入到HDFS。
2、Maven工程编写TimeStampInterceptor类
我们查看Flume官网http://flume.apache.org/FlumeUserGuide.html
找到Flume Sinks、HDFS Sink关于timestamp的内容。
(1)定义TimeStampInterceptor类实现Interceptor接口
主要在单event里面Intercept方法处理把时间替换掉。
publicEvent intercept(Event event){Map<String,String> headers = event.getHeaders();byte[] body = event.getBody();String log = new String(body, StandardCharsets.UTF_8);//把日志转为JSON对象JSONObject jsonObject = JSONObject.parseObject(log);//获取到keyString ts = jsonObject.getString("ts");//把key,value放到timastamp里面headers.put("timestamp",ts);return event;}
在List event数组里面,调用单event清除时间
public List<Event> intercept(List<Event> list){eventArrayList.clear();for(Event event:list){//调用单个event把时间替换掉eventArrayList.add(intercept(event));}return eventArrayList;}
(2)定义静态内部类创建TimeStampInterceptor
public
static
class Builder implements Interceptor.Builder{@Overridepublic Interceptor build(){return new TimeStampInterceptor();}@Overridepublic void configure(Context context){}}
四、消费Flume配置
完成了Flume组件Source、Channel、Sink以及TimeInterceptor拦截器,我们开始配置flume的conf文件。
#新建kafka-file-hdfs.conf文件vim kafka-file-hdfs.conf
#消费flume配置信息a1.sources = r1a1.channels = c1a1.sinks = k1#Source:kafka sourcea1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource#一次拉取10000个a1.sources.r1.batchSize = 10000#配置时间是2000a1.sources.r1.batchDurationMillis = 2000#Kafka集群a1.sources.r1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092#topica1.sources.r1.kafka.topics = topic_log#配置时间拦截器a1.sources.r1.interceptors = i1a1.sources.r1.interceptors.i1.type = com.wqs.flume.interceptor.TimeStampInterceptor$Builder
2、配置Channel
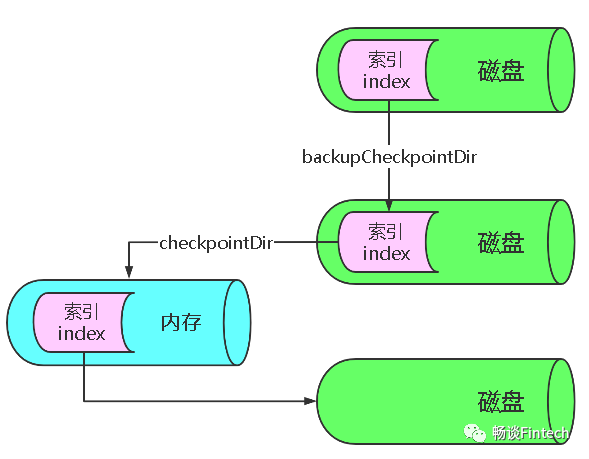
#配置channel:file channela1.channels.c1.type = file#配置磁盘索引,它备份内存索引a1.channels.c1.checkpointDir = opt/module/flume-1.9.0/checkpoint/behavior1#存在存盘的位置a1.channels.c1.dataDirs = opt/module/flume-1.9.0/data/behavior1/a1.channels.c1.maxFileSize = 2146435071#100W个eventa1.channels.c1.capacity = 1000000#timeout in seconds for adding or removing eventa1.channels.c1.keep-alive = 3a1.channels.c1.parseAsFlumeEvent = false
3、配置Sink以及HDFS压缩
#配置 sinka1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = /log/topic_log/%Y-%m-%da1.sinks.k1.hdfs.filePrefix = log-a1.sinks.k1.hdfs.round = falsea1.sinks.k1.hdfs.rollInterval = 10a1.sinks.k1.hdfs.rollSize = 134217728a1.sinks.k1.hdfs.rollCount = 0# 控制输出文件是原生文件,lzop压缩a1.sinks.k1.hdfs.fileType = CompressedStreama1.sinks.k1.hdfs.codeC = lzop#配置source和channel的关系a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
五、启动Flume观察HDFS
1、启动Flume消费节点
由于我们Flume消费这台节点是单节点Node03,所以启动的话直接通过命令行完成,当然也能使用脚本封装一下。脚本在上一节“前端埋点数据采集(三)Flume采集数据
”一样。
nohup opt/module/flume-1.9.0/bin/flume-ng agent --name a1 --conf-file opt/module/flume-1.9.0/conf/kafka-file-hdfs.conf --name a1 Dflume.root.logger=INFO,LOGFILE 1>/opt/module/flume-1.9.0/log2.txt 2>&1 &
这个时候已经万事俱备只欠东风了!我们启动整个集群,我们这里使用1个脚本运行启动整个集群。
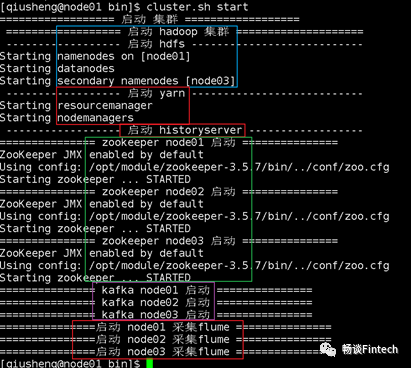
并且观察进程查看Flume是否启动成功?
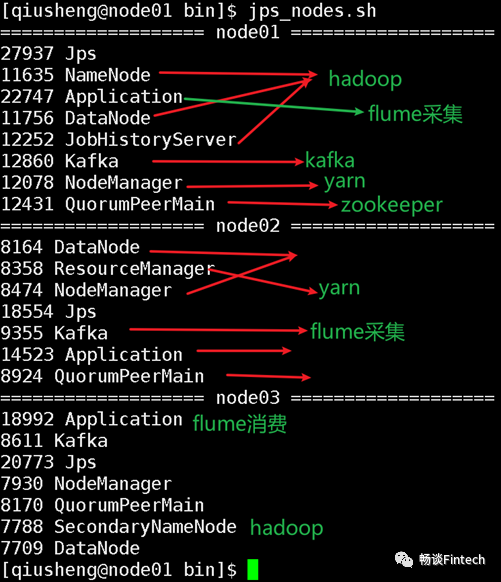
有了Application说明Flume启动成功。
注意:其他进程这里也标出来了,可以自检一下。

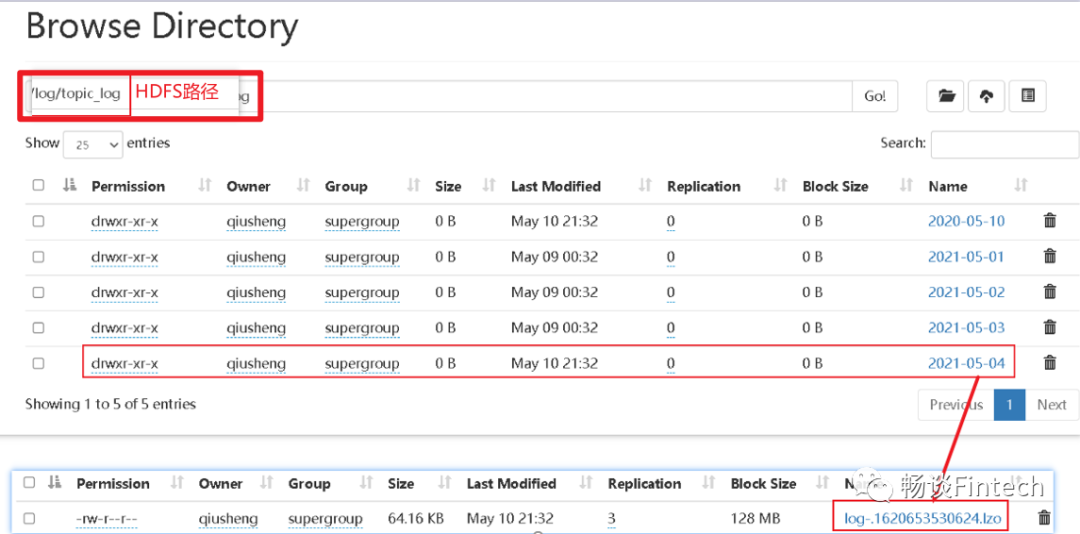
发现HDFS目录生成和我们配置的一月,并且按天一个日期。
观察HDFS生成的文件指出lzo压缩
3台Kafka集群搭建、配置以及是否能否生产数据; 消费Flume选型、拦截器实现、配置; 启动FLume、启动整个集群; 观察WebUI查看HDFS目录; 是否生成日志数据、日志数据时间是否正常、是否支持lzo压缩。
>>>>
Q&A
Q1:为什么启动Kafka集群的时候,没有设置和指定topic,然后查看Kafka --list_consumer_offsets有一个叫topic_log?
A1: 因为我们Flume组件配置Kafka Channel的时候,定义了一个叫topic_log的主题,Kafka默认启动会创建这个topic_log,等等后面的Flume来消费。
Q3:为什么启动启动消费Flume抛出如下异常:
ERROR hdfs.HDFSEventSink: process failedjava.lang.OutOfMemoryError: GC overhead limitexceeded
A3:在conf/flume-env.sh文件中增加如下配置:
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
-Xms:表示JVM Heap(堆内存)最小尺寸,初始启动时候的分配;
-Xmx :表示JVM Heap(堆内存)最大允许的尺寸,按需分配。如果不设置一致,容易在初始化时,由于内存不够,频繁触发fullgc。
