




一、K-means类聚算法简介
K-means类聚算法(K-means clustering)是一种原理简单、功能强大且应用广泛的无监督机器学习技术。无监督机器学习技术是指无需标签即可从数据集中做推理,得到推理结果。
K-means类聚算法的目标是将数据集中的数据根据相似性分类,类别数为k,每类会有一个聚类中心(centroid)。数据间的相似性通常用“欧几里得距离(Euclidean Distance)”来定义,当然也可以设计其它的度量方式。
二、K-means类聚算法步骤
定义目标聚类数K,例如,k=3
随机初始化的 k 个聚类中心(controids)
计算每个数据点到K个聚类中心的Euclidean Distance,然后将数据点分到Euclidean Distance最小的对应类聚中心的那类
针对每个类别,重新计算它的聚类中心
重复上面 3-4 两步操作,直到达到某个中止条件(迭代次数、最小误差变化等)
三、K-means类聚算法可视化
参考链接:https://stanford.edu/class/engr108/visualizations/kmeans/kmeans.html

四、K-means类聚算法实现代码
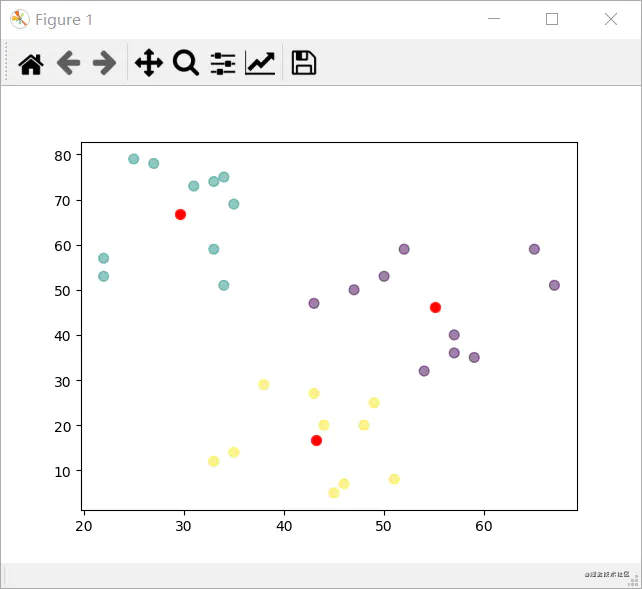
import pandas as pdimport matplotlib.pyplot as pltfrom sklearn.cluster import KMeansdf = pd.DataFrame({"x": [25, 34, 22, 27, 33, 33, 31, 22, 35, 34, 67, 54, 57, 43, 50, 57, 59, 52, 65, 47, 49, 48, 35, 33, 44, 45, 38, 43, 51, 46],"y": [79, 51, 53, 78, 59, 74, 73, 57, 69, 75, 51, 32, 40, 47, 53, 36, 35, 59, 59, 50, 25, 20, 14, 12, 20, 5, 29, 27, 8, 7]})kmeans = KMeans(n_clusters=3).fit(df)centroids = kmeans.cluster_centers_# 打印类聚中心print(type(centroids), centroids)# 可视化类聚结果fig, ax = plt.subplots()ax.scatter(df['x'],df['y'],c=kmeans.labels_.astype(float),s=50, alpha=0.5)ax.scatter(centroids[:, 0], centroids[:, 1], c='red', s=50)plt.show()
五、运行结果
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓




点分享

点点赞

点在看
文章转载自做一个柔情的程序猿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
