




data.table 包数据处理
data.table 包数据处理前言基础介绍基本格式i j by 使用读取数据行筛选列筛选总结j 常规计算by 分组新增或删除更新列排序行筛选data.table包中特殊符号常用函数排序函数 frank判断函数交集 差集 合并连接透视表功能运用自定义函数计算带汇总的聚合运算行列转变
前言
官方关于data.table
包的介绍请参阅:
https://cran.r-project.org/web/packages/data.table/vignettes/datatable-intro.html
data.table
包是我用了较长一段时间tidyverse系列后发现的“数据处理包”。现在已经忘记是什么吸引了我,我猜测可能是"大数据处理利器"之类的标签吸引了我,因为我喜欢“快”。但是,初次接触时,语法的“怪异”并没有给我带来多少麻烦,因为我本来就没有编程基础以及R语言基础,那就只好死记硬背一些常用的用法,尤其喜欢拿Excle的一些用法参照,去实现Excle上面的部分操作,从读取、增、改、删除、筛选、计算列等常规操作入手。
习惯语法之后,将会享受data.table
带来的便利,其简洁的语法以及高效的计算速度(相比tidyverse系列)。
另外,Python中也有该包,目前正在积极开发中,期待ing。
基础介绍
基本格式
DT[i, j, by]
## R: i j by
## SQL: where | order by select | update group by
data.table个人理解主要有三大类参数,i 参数做筛选,j参数做计算,by参数做分组.拿Excel透视表类别,i位置参数当作『筛选』,by位置用来做汇总字段『行』,j位置当作『值』,如下所示:
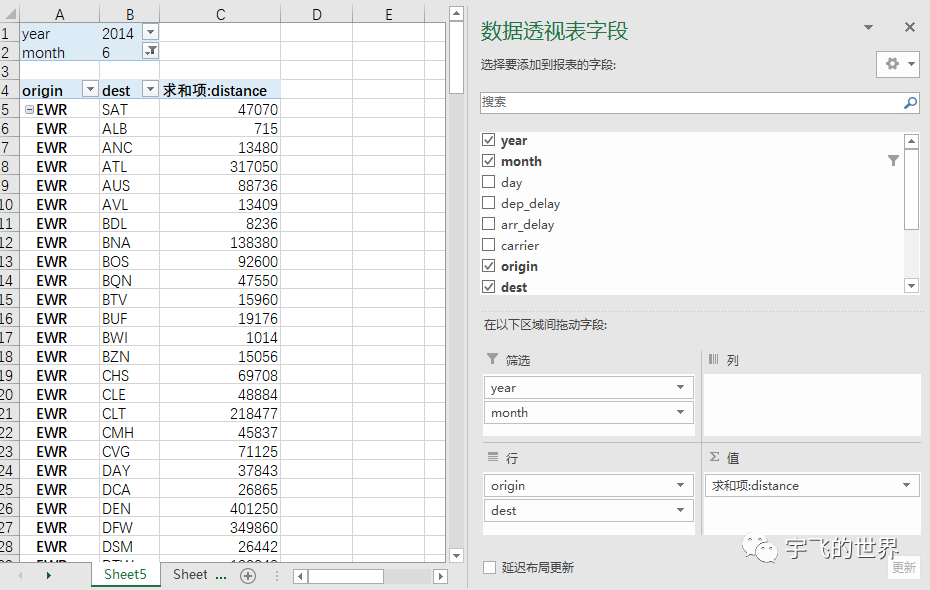
1.代码实例
代码求2014年6月,从各始发机场到各目的机场的飞行距离求和.
library(data.table)
flights <- fread("./data/flights.csv")
flights[year==2014 & month==6,.(求和项distance=sum(distance)),by=.(origin,dest)]
2.代码解释
i 的部分:year==2014 & month==6 ;
j 的部分:求和项distance=sum(distance),写在.()中或者list()中;
by 的部分.(origin,dest),重点是写在.()中,和Excel透视表一一对应。
至于为什么要用.()
包裹起来,先默认为格式强制要求。就这个问题我想说:大部分人可能觉得是比较“怪异”的用法,并且不理解,从而可能留下data.table
不好用,很古怪的印象,但是我觉得任何东西存在即合理,你学一个东西总得接受一些你可能不认可的东西,这样可能才是真正的学习,就像拿Python
来做数据分析,我刚开始觉得pandas
很难用,很反人类,但是后来知道python
代码可以直接打包封装成exe
后,觉得真香,说这么多核心思想是我们学会挑选合适的工具用,适应它,用好它。
i j by 使用
读取数据
data.table 包读取数据主要用fread 函数,在我实际工作中接触的数据大部分以数据库,csv,Excel形式存在.fread 函数可以直接读取CSV格式文件,无论是本地文件或者在线文件.
本文会照搬很多官方关于data.table的demo.
library(data.table)
input <- if (file.exists("./data/flights.csv")) {
"./data/flights.csv" #本地文件
} else {
"https://raw.githubusercontent.com/Rdatatable/data.table/master/vignettes/flights.csv" #在线文件需翻墙
}
flights <- fread(input) #具体参数请参照文档 实际工作中可能会用到的encoding参数,编码 encoding='UTF-8'
head(flights)
本文读取本地文件,如果该数据集下载失败,可更改地址为(http://www.zhongyufei.com/datatable/data/flights.csv)
flights <- fread("http://www.zhongyufei.com/datatable/data/flights.csv")数据集记录的是 2014 年,纽约市3大机场(分别为:JFK 肯尼迪国际机场、 LGA 拉瓜迪亚机场,和 EWR 纽瓦克自由国际机场)起飞的航班信息。
具体的记录信息(特征列),包括起飞时间、到达时间、延误时长、航空公司、始发机场、目的机场、飞行时长,和飞行距离等。
行筛选
#单条件筛选
filghts[year == 2014] #筛选year==2014
#多条件筛选 用 & 链接
flights[ year == 2014 & month == 6]
# | 相当于中文条件或
flights[ month == 5 | month == 6]
# %in% 类似sql中in用法
flights[month %in% c(1,3,5,7,9)]
# %between% 类似sql中between and 用法
flights[month %between% c(1,7)]
列筛选
flights[,.(year,month,day,dep_delay,carrier,origin)] #注意前面的,
#data.table包自带函数列排序
# not run
# setcolorder(x = flights,neworder = c( "month","day","dep_delay" ,"arr_delay","carrier" )) #按照指定列顺序排序 其余字段保持不变,不是建立副本,是直接修改了flights 数据的列顺序
总结
行筛选在 i 的位置上进行, 列筛选在 j 的位置上进行;
dt <- flights[ year == 2014 & month == 6 & day >=15,.(year,month,day,dep_delay,carrier,origin)]
head(dt)
j 常规计算
flights[year==2014 & month==6,.(求和项distance=sum(distance),平均距离=mean(distance)),by=.(origin,dest)]
by 分组
1.按月分组
flights[,.(sum(distance)),by=.(month)]2.多条件分组
dt <- flights[,.(sum(distance)),by=.(carrier,origin)]
head(dt)
#可直接重新命名
dt <- flights[,.(sum(distance)),by=.(newcol1 = carrier,newcol2 = origin)]
head(dt)
3.按月份是否大于6分组
即得到是否大于6的两类分组
dt <- flights[,.(sum(distance)),by=.(month>6)] #by里面可以做计算
head(dt)
新增或删除更新列
#data.table()函数创建data.table数据框
dt <- data.table(col1=1:10,col2=letters[1:10],col3=LETTERS[1:10],col4=1:10)
# 新增列 :=
dt[,addcol:=rep('新列',10)][] #最后的[]是为了显示新增列的数据框,可不增加
#dt[,addcol:=rep('新列',10)] 不会显示返回结果,加上[]会显示返回
#更新列
dt[,col1:=11:20][]
# 新增多列
dt[,`:=`(newcol1=rep('newcol1',10),newcol2=rep('newcol2',10))][]
#not run
#两列间计算
#dt[,newcol:=col1/col4]
#删除列
dt[,col1:=NULL][]
dt[,c('newcol1','newcol2'):=NULL][]
排序
# setorder data.table package 里面的函数
set.seed(45L)
DT = data.table(A=sample(3, 10, TRUE),
B=sample(letters[1:3], 10, TRUE), C=sample(10))
setorder(DT, A, -B) #将DT按照A、B排序 A 升序,-B降序
# 和上面同样的销售 但是函数变成 setorderv
setorderv(DT, c("A", "B"), c(1, -1))
行筛选
# 筛选 %in%
flights[ hour %in% seq(1,24,2) ]
# 字符筛选
flights[ origin %chin% c('JFK','LGA')]
# not run 同上 %chin% 对字符速度筛选速度更快
#flights[ origin %in% c('JFK','LGA')]
#between
#between(x, lower, upper, incbounds=TRUE, NAbounds=TRUE, check=FALSE)
X <- data.table(a=1:5, b=6:10, c=c(5:1))
X[b %between% c(7,9)]
X[between(b, 7, 9)] #效果同上
X[c %between% list(a,b)] # 矢量化
# %like% 用法与SQL中 like 类似
DT = data.table(Name=c("Mary","George","Martha"), Salary=c(2,3,4))
DT[Name %like% "^Mar"]
data.table包中特殊符号
.SD,.BY,.N,.i 和.GRP 等,只能用在 j 的位置,.N 可以用在 i 的位置.
DT = data.table(x=rep(c("b","a","c"),each=3), v=c(1,1,1,2,2,1,1,2,2), y=c(1,3,6), a=1:9, b=9:1)
DT
X = data.table(x=c("c","b"), v=8:7, foo=c(4,2))
X
# 用在i的位置
DT[.N] #取DT最后一行,.N 计数函数
DT[,.N] #DT 共有多少行记录 返回一个整数
DT[, .N, by=x] #分组计数
DT[, .SD, .SDcols=x:y] # 选择x 到y 列
#DT[, .SD, .SDcols=c("x","y")] 与上面不一样
DT[, .SD[1]] #去第一行
DT[, .SD[1], by=x] #按x列分组后
DT[, c(.N, lapply(.SD, sum)), by=x] #按照x分组后 行数计数和每列求
常用函数
排序函数 frank
官方案例,如下所示:
frankv(x, cols=seq_along(x), order=1L, na.last=TRUE,
ties.method=c("average", "first", "random",
"max", "min", "dense"))
frankv在排序时,NA被认为是一样的,基础base R 中认为不一样.
x <- c(4, 1, 4, NA, 1, NA, 4)
frankv(x)
rank(x)
升序降序选择
order参数只能为1或者-1.默认为1代表升序
frankv(x,order = 1L)
frankv(x,order = -1L)
排序方式选择,默认 average
x <- c(1,1,1,2,3)
frankv(x) #大小相同 排名相同,下一位排名除以2
frankv(x,na.last = 'min') #大小相同 排名相同,取最小排名
frankv(x,na.last = 'max') #大小相同 排名相同,取最大排名
frankv(x,ties.method = 'first') #相同大小排名以后往后递增 实际工作中如商品销售排名会采用这种,根据实际情况决定
#还有 dense 紧凑排名\random,两种选择.
判断函数
fifelse() 类似dplyr::if_else() 函数,相比base::ifelse() 更快.
x <- c(1:4, 3:2, 1:4)
fifelse(x > 2L, x, x - 1L)
交集 差集 合并
相当于base R 中 union(),intersect(),setdiff() 和setequal() 功能.all参数控制如何处理重复的行,和SQL中不同的是,data.table将保留行顺序.
fintersect(x, y, all = FALSE)
fsetdiff(x, y, all = FALSE)
funion(x, y, all = FALSE)
fsetequal(x, y, all = TRUE)
x <- data.table(c(1,2,2,2,3,4,4))
x2 <- data.table(c(1,2,3,4)) # same set of rows as x
y <- data.table(c(2,3,4,4,4,5))
fintersect(x, y) # intersect
fintersect(x, y, all=TRUE) # intersect all
fsetdiff(x, y) # except
fsetdiff(x, y, all=TRUE) # except all
funion(x, y) # union
funion(x, y, all=TRUE) # union all
fsetequal(x, x2, all=FALSE) # setequal
fsetequal(x, x2) # setequal all
连接
两个数据框之间左连,右连等操作,类似数据库中的left_join right_join,inner_join 等函数.
键入?merge()查看函数帮助,data.table 包中和base R 中都有merge 函数,当第一个数据框是data.table格式时启用data.table::merge().
?merge()
merge(x, y, by = NULL, by.x = NULL, by.y = NULL, all = FALSE,
all.x = all, all.y = all, sort = TRUE, suffixes = c(".x", ".y"), no.dups = TRUE,
allow.cartesian=getOption("datatable.allow.cartesian"), # default FALSE
...)
x.y为连个数据框,当两个数据框连接字段相同时,用by=c('','')连接,不同时采用,by.x=,by.y= ,all,all.x,all.y等参数决定连接方式,sort 默认为排序,当不需要排序时更改参数,allow.cartesian=是否允许笛卡尔,默认不允许,当需要时设置为TURE.
透视表功能
dcast函数能实现长转宽,可实现Excel中透视表功能.
dcast(data, formula, fun.aggregate = NULL, sep = "_",
..., margins = NULL, subset = NULL, fill = NULL,
drop = TRUE, value.var = guess(data),
verbose = getOption("datatable.verbose"))
示例如下:
dt <- data.table(分公司=rep(c('华东','华南','华西','华北'),1000),
季度=rep(c('一季度','二季度','三季度','四季度'),1000),
销售额=sample(100:200,4000,replace = TRUE))
dcast(dt,分公司~季度,value.var = "销售额",fun.aggregate = sum)
从版本V1.9.6起可以同时对多个值实现不同聚合后的长转宽. fun参数可以是自定义的函数.
dt <- data.table(x=sample(5,20,TRUE), y=sample(2,20,TRUE),
z=sample(letters[1:2], 20,TRUE), d1 = runif(20), d2=1L)
dcast(dt, x + y ~ z, fun=list(sum,mean), value.var=c("d1","d2"))
dcast(dt, x + y ~ z, fun=list(sum,mean), value.var=list("d1","d2")) #注意value.var是向量和列表时的区别
melt函数实现宽转长
melt(data, id.vars, measure.vars,
variable.name = "variable", value.name = "value",
..., na.rm = FALSE, variable.factor = TRUE,
value.factor = FALSE,
verbose = getOption("datatable.verbose"))
示例如下:
ChickWeight = as.data.table(ChickWeight)
setnames(ChickWeight, tolower(names(ChickWeight)))
DT <- melt(as.data.table(ChickWeight), id=2:4) # calls melt.data.table
运用
自定义函数计算
1.自定义函数处理列
按照自定义函数计算修改单列或多列
# 测试函数
fun <- function(x){
x <- x^2+1
}
DT <- data.table(x=rep(c("b","a","c"),each=3), v=c(1,1,1,2,2,1,1,2,2), y=c(1,3,6), a=1:9, b=9:1)
DT[,.(newcol=fun(y)),by=.(x)]
#Not run
#DT[,lapply(.SD,fun),.SDcols=c('y','a'),by=.(x)] #多列参与计算
# 批量修改列
#Not run
# myfun <- function(x){
# return(x)
# }
#
# dt <- dt[,colnames(dt):=lapply(.SD[,1:ncol(dt)],myfun)] #很重要的用法
带汇总的聚合运算
按照by的字段级别汇总.
rollup
分组聚合后设置id=TRUE将各个级别的汇总显示清晰,当by字段只有一个是和正常聚合计算没有区别.以下是官方案例.
#Usage
#rollup(x, j, by, .SDcols, id = FALSE, ...)
n = 24L
set.seed(25)
DT <- data.table(
color = sample(c("green","yellow","red"), n, TRUE),
year = as.Date(sample(paste0(2011:2015,"-01-01"), n, TRUE)),
status = as.factor(sample(c("removed","active","inactive","archived"), n, TRUE)),
amount = sample(1:5, n, TRUE),
value = sample(c(3, 3.5, 2.5, 2), n, TRUE)
)
rollup(DT, j = sum(value), by = c("color","year","status")) # default id=FALSE
#rollup(DT, j = sum(value), by = c("color","year","status"), id=TRUE)
个人运用,实际工作中常常需要汇总项,汇总项在Excel透视表中很简单,在R中我之前是构造重复的数据源聚合汇总出现汇总项,极大浪费内存,运算速度减慢.
新方法 rollup
set.seed(25)
N <- 1000
dt <- data.table(col1=sample(LETTERS[1:5],N,replace = T),col2=sample(letters[1:5],N,replace = T),num=1:N)
rollup(dt,j=c(list(sum(num))),by=c('col1','col2'))
#同上 添加汇总项名称 total
#rollup(dt,j=c(list(total=sum(num))),by=c('col1','col2'))
#添加id=TRUE参数,多出的grouping 列显示聚合级别
#rollup(dt,j=c(list(total=sum(num))),by=c('col1','col2'),id=TRUE)
2.groupingsets
按照指定字段聚合.包作者说相同与SQL中的 GROUPING SETS 操作.详情参照postgresql
res <- groupingsets(DT, j = c(list(count=.N), lapply(.SD, sum)), by = c("color","year","status"),
sets = list("color", c("year","status"), character()), id=TRUE)
head(res)
注意groupingsets函数中sets参数,用list()包裹想要聚合的字段组合,最后还有一个character(),加上该部分相当于全部聚合.当by只有一个字段时,相当于汇总.用法类似sql中"()".
library(DBI)
con <- dbConnect(odbc::odbc(), .connection_string = "Driver={SQL Server};server=Vega;database=ghzy;uid=zhongyf;pwd=Zyf123456;", timeout = 10)
上述语句结果等同于下面sql.
select color ,year, status,count(*) count,sum(amount) amount,sum(value) value
FROM dbo.DT
GROUP BY
GROUPING SETS(
(color),
(year,status),
() ---- 类似 character()
)
最后还有cube()函数,可?cube查看用法
行列转变
一列变多行
用tstrsplit()函数实现
n <- 10
dt <- data.table(name=LETTERS[1:n],char=rep('我-爱-R-语-言'),n)
res <- dt[,.(newcol=tstrsplit(char,'-')),by=.(name)]
head(res)
多行变一列
res[,.(char=paste0(newcol,collapse = '-')),by=.(name)]
#同上
#res[,.(char=stringr::str_c(newcol,collapse = '-')),by=.(name)]
# A 我-爱-R-语-言
# B 我-爱-R-语-言
# C 我-爱-R-语-言
# D 我-爱-R-语-言
# E 我-爱-R-语-言
# F 我-爱-R-语-言
# G 我-爱-R-语-言
# H 我-爱-R-语-言
# I 我-爱-R-语-言
# J我-爱-R-语-言
本文为原创文章,转载请标明出处
