




“ 心灵纯洁的人,生活充满甜蜜和喜悦。——列夫·托尔斯泰”
本周闲暇之余产生对编译spark源码(去除hive相关jar包)的浓厚兴趣,于是在经过一番测试之后,成功编译。本文会将编译过程所需的框架版本和参考思路记录下来。
01
—
版本匹配问题
首先编译源码,需要参照官网给予的推荐版本
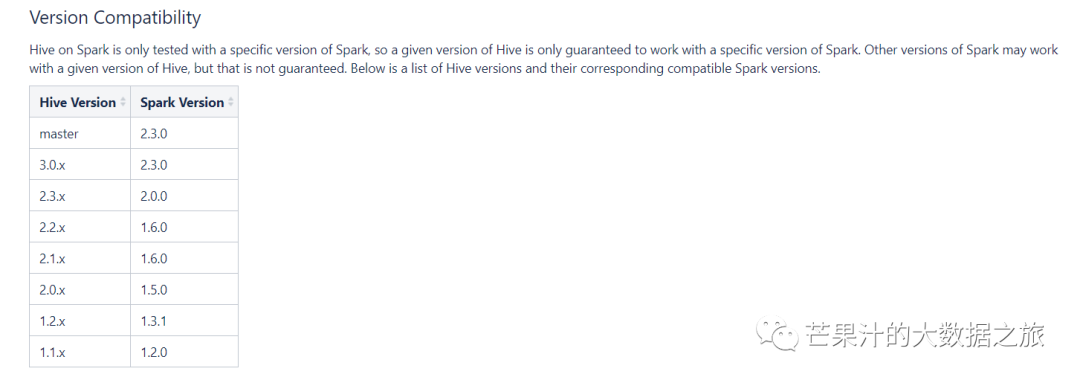
从提示中可以看出我们需要下载hive-3.0.x对应spark-2.3.0
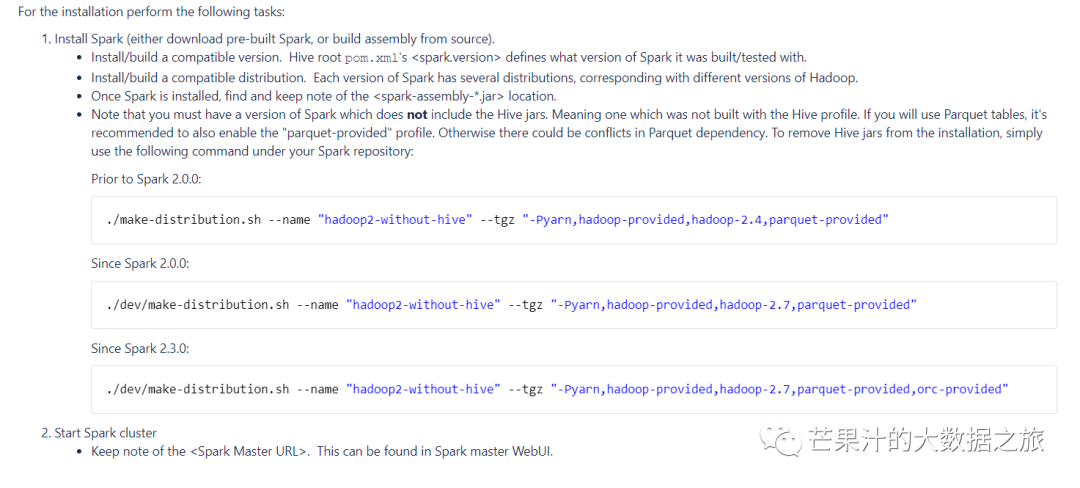
官方提示spark各版本编译指令
Prior to Spark 2.0.0:#spark2.0.0之前./make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.4,parquet-provided"Since Spark 2.0.0:#spark2.0.0以后./dev/make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.7,parquet-provided"Since Spark 2.3.0:#spark2.3.0之后./dev/make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.7,parquet-provided,orc-provided"
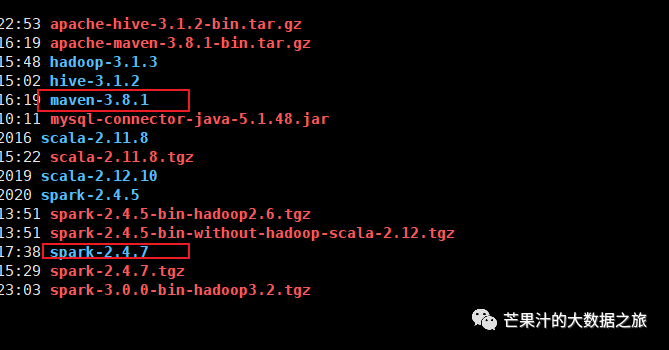
我们这里使用spark2.3.0,并选择scala 2.11.8 maven3.8.1 jdk8_202
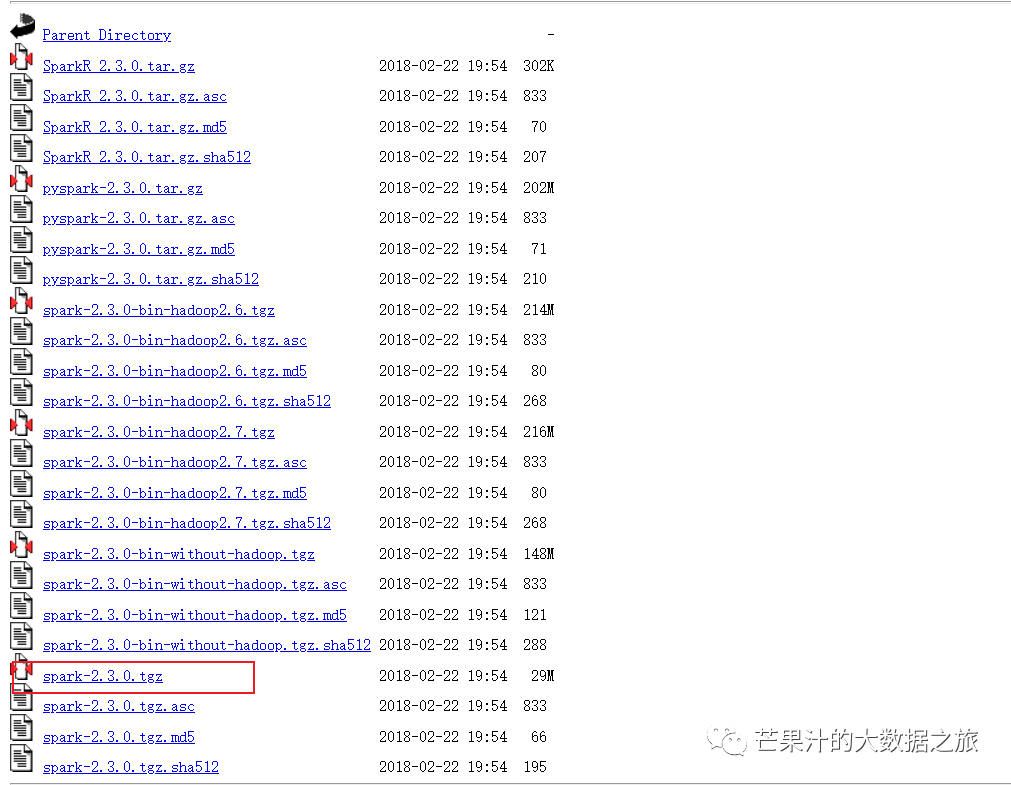


需要指出的是,笔者原本是使用jdk8_181,maven3.5.4,spark2.4.5,
Scala2.12.x版本做的编译,但是编译中途会报jdk181重大bug,因此升级
了jdk版本,maven版本一并从3.5.4升级为3.8.1,spark 2.4.5 降级2.3.0
与官方推荐保持一致,Scala降级为2.11.8。
02
—
开始编译
首先确保maven,jdk,spark。Scala环境变量已妥善配置
解压spark包至目标目录


# cd 进入spark所在目录./build/mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.3 -DskipTests clean package## 等待编译
这一步骤完成之后,进入spark/dev目录执行命令
./dev/make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.7,parquet-provided,orc-provided"
这一步骤完成之后,退出dev,在spark主目录会有一个without-hive的tar包,解压至主目录,修改名称与环境变量保持一致
此时尝试进行spark local模式提交代码
此时会报一个lof4j日志错误

笔者在Google时,有人反馈是Hadoop相关jar包没有引入,但是我在spark-env.sh配置hadoop classpath之后,并没有解决该问题。
于是想到引入相关jar包以解决相关问题。
一开始根据提示往spark/jars/ 引入了第一个slf4j的jar包,但是会报新的错误。
于是把图中第二个和第三个日志jar包均引入spark/jars/
最终我们俩次求spark Pi成功

本次spark源码编译到此初步完成。
参考链接
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
https://maven.apache.org/download.cgi
https://mirrors.bfsu.edu.cn/apache/hive/
https://archive.apache.org/dist/spark/spark-2.3.0/
https://www.scala-lang.org/download/2.11.8.html
http://java.sousou88.com/article/15129.html

