




点击蓝字关注我们

大家好,我是杰哥
上篇Spring Cloud(十二):消息中心篇-RocketMq与Kafka选型(一)中,主要对两者的部署架构、工作流程以及可靠性三个方面分别进行了分析对比,带领大家了解了两者在这三个方面的不同之处。今天,我们再一起看看它们的其他不同点
搞清楚消息中心的日志存储方式,即数据的存储方式,对于研究一个消息中心来说,也比较重要
因此,本次推送,我们主要来对两者的日志存储方式一探究竟
01.两者的相同点
02.部署架构不同
03.工作流程不同
04.日志存储方式不同
05.保证消息顺序消息的方法是否相同
06.消息重复机制不同
07.是否支持延时消息
08.消息过滤方式不同
09.消息失败支持重试吗?
10.事务不同
11.是否支持回溯消费?
12.高可用机制不同
13.性能不同?
14.社区活跃度
15.其他方面不同
首先,Kafka与RocketMq都是将消息存储在磁盘中的,并且均是通过顺序写的方式进行存储的,只是具体的存储方式存在区别:
首先,我们先来看看Kafka的存储机制
1 Kafka的存储方式
1)存储结构总览
总得来说,Kafka中每个topic包含多个分区partition,而每个partition则是由一部分大小相同的segment文件组成(segment的大小也可以进行配置,默认log.segment.bytes = 1024 * 1024 * 1024)。如下图所示
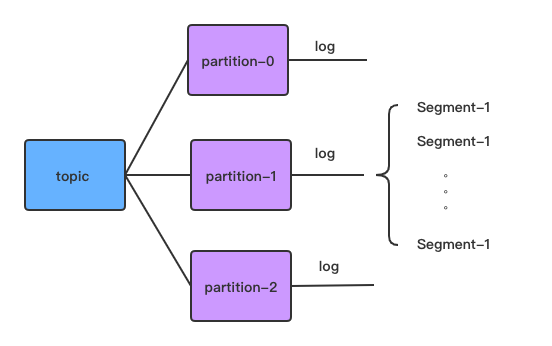
而每个segment则包含索引文件和数据文件两个部分
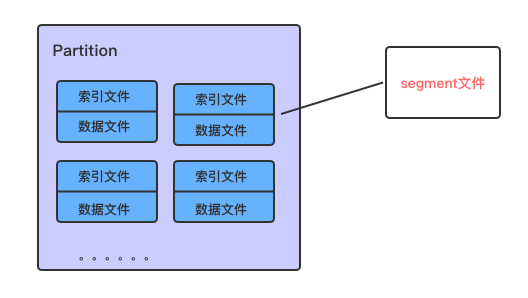
大致认识了kafka日志文件的存储模式以后,接下来我们一起进入我本地搭建的kafka的真实的存储目录,进一步了解
2)进一步探索
a 进入kafka的日志目录(该目录为kafka安装目录/config/server.properties文件中log.dirs项配置的目录),我们可以看到,每个partition被分为一个文件夹,其命名规则为topic名称+“-”+分区id
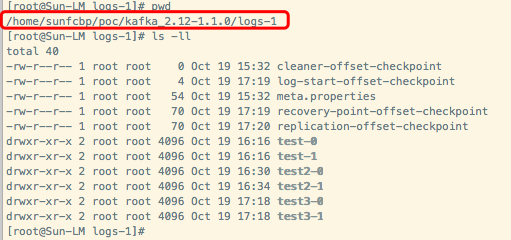
b 初次创建的topic(如test3),它的分区中包含.index,.log,.timeindex以及leader-epoch-checkpoint这4个文件,其中log文件和leader-epoch-checkpoint文件的初始大小均为0

c 向topic发送一段时间消息后(测试时可将配置文件server.propertis中的log.segment.bytes的值设置小一点),会看到此时会多出4个文件:名称均为00000000000000005986,后缀分别为index、log、timeindex以及snapshot
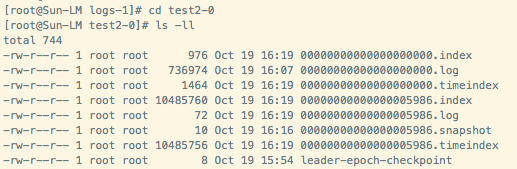
实际上,index、log、timeindex以及snapshot文件,均是以当前segment的第一条消息的偏移量offset命名。偏移量offset是一个64位的长整形数,固定是20位数字,长度未达到,左边以0填充
到目前为止,我们看到,Kafka对于日志的存储,相当于将一个巨型文件被平均分配到多个大小相等(消息数量不一定相等)的segment文件中,这种特性方便最老的segment文件被快速被删除,有效提高磁盘利用率。每个partiton只需要支持顺序读写就行了。其中,segment文件生命周期由服务端配置参数(默认log.retention.hours=168)决定
3) 文件说明
*.index文件 offset索引文件,文件名是segment的起始offset
*.log文件 实际存储数据的的segment文件,文件名是segment的起始offset
*.timeindex文件,时间戳索引文件,文件名是segment的起始offset
*.snapshot文件,记录了producer的事务信息
leader-epoch-checkpoint:保存了每一任leader开始写入消息时的offset, 会定时更新
a)进入bin目录,使用Kafka自带的命令查看index文件
sh kafka-run-class.sh kafka.tools.DumpLogSegments --files /home/test/tools/kafka_2.12-1.1.0/logs-1/test2-0/00000000000000000000.index --print-data-log
结果显示如下:
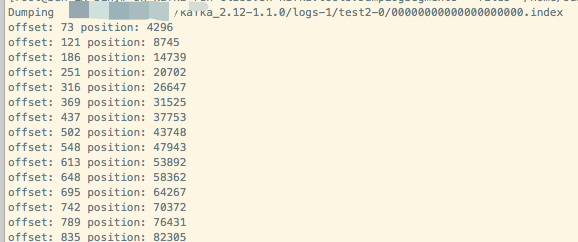
可以看到index文件中分别存储每条消息的offset值以及该消息的位置,有多少个offset,就说明有多少条消息
b) 查看timeindex文件
sh kafka-run-class.sh kafka.tools.DumpLogSegments --files home/test/tools/kafka_2.12-1.1.0/logs-1/test2-0/00000000000000000000.timeindex --print-data-log
结果显示如下:
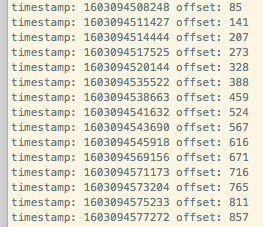
可以看到index文件中分别存储,每条消息产生时间的时间戳和offset值,当然,同样地,有多少个offset,就有多少条消息
c)查看log文件
sh kafka-run-class.sh kafka.tools.DumpLogSegments --files home/test/tools/kafka_2.12-1.1.0/logs-1/test2-0/00000000000000000000.log --print-data-log
结果显示如下:
offset: 5975 position: 734733 CreateTime: 1603094839226 isvalid: true keysize: -1 valuesize: 164 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: "hello,jiege~"offset: 5976 position: 734733 CreateTime: 1603094839246 isvalid: true keysize: -1 valuesize: 308 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: "hello,jiege~"offset: 5977 position: 734733 CreateTime: 1603094839282 isvalid: true keysize: -1 valuesize: 0 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: "hello,jiege~今天是个好日子"
我们看到,log数据文件中由许多message组成,message包含了实际的消息数据,其中message包含了offset、position、CreateTime以及payload等主要信息
4)读取文件的步骤
从上面我们可以知道,每个索引文件和日志文件均是以当前segment的第一条消息的偏移量offset命名文件,其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0
第二个文件00000000000000005986.index的消息量起始偏移量为5986,其他后续文件依次类推。
假如还有第三个文件:00000000000000010012.index,
则该文件中的消息起始偏移量为10012
以起始偏移量命名并排序这些文件,只要根据offset二分查找文件列表,就可以快速定位到具体文件
例如,读取offset=6000的message,需要通过下面2个步骤查找
第一步,查找segment文件
当offset=6000时,
定位到00000000000000005986.index|log文件
第二步,通过segment文件查找message
通过顺序查找00000000000000005986.log,直到offset=6000为止
2 RocketMq的存储方式
如图所示,消息生产者发送消息到broker,都是会按照顺序存储在CommitLog文件中,每个commitLog文件的大小为1G
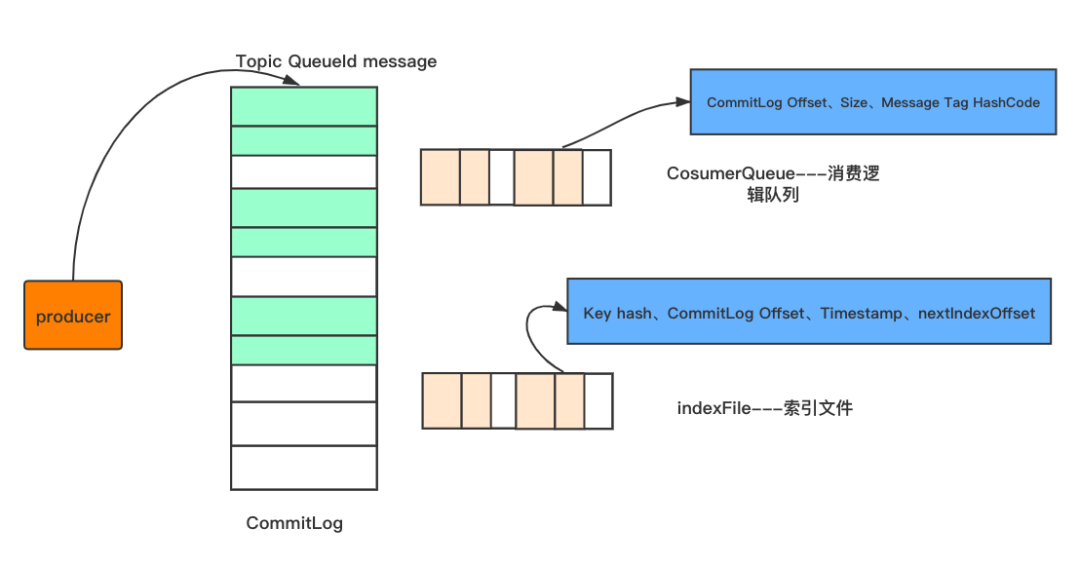
CommitLog-存储所有的消息元数据,包括Topic、QueueId以及message
CosumerQueue-消费逻辑队列:存储消息在CommitLog的offset
IndexFile-索引文件:存储消息的key和时间戳等信息,使得RocketMq可以采用key和时间区间来查询消息
也就是说,rocketMq将消息均存储在CommitLog中,并分别提供了CosumerQueue和IndexFile两个索引,来快速检索消息
来简单看看我本地的存储情况:
1) 进入store目录
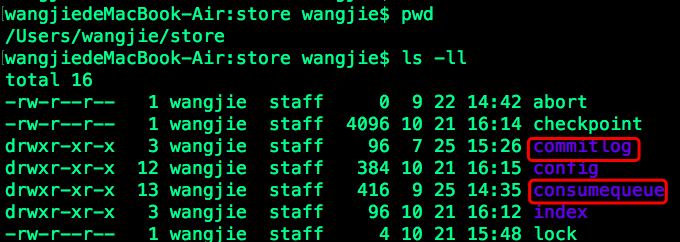
会发现该目录下分别包含CommitLog、CosumerQueue和IndexFile三个文件夹
2)进入consumerqueue
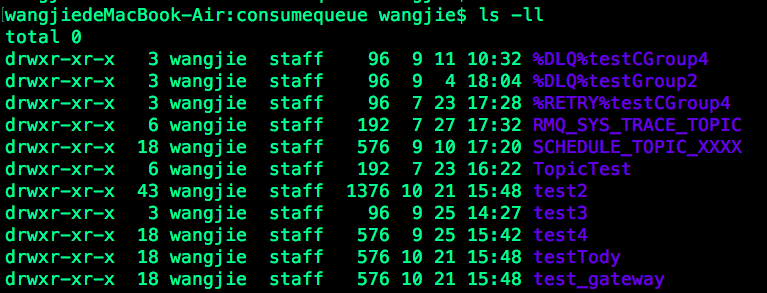
该目录除了包含几个我自己建的主题外,还包含了重试队列(如
%RETRY%testCGroup4)和死信队列(如%DLQ%testGroup2)
其中,当消息发送失败后,将被发往重试队列进行重新发送,而当发送了指定次数之后,依旧失败的话,则会被发送到死信队列中
3)接着进入主题(test4)目录

test4有14个队列0,因此会显示14个 consumerQueue:1,2,……,14。也就是说主题test4和QueueId=0组成一个ConsumeQueue,主题test4和QueueId=1组成另一个ConsumeQueue,依次类推
进入其中一个文件夹,可以看到一个或多个具体的文件

该文件包含了当前topic下的队列(test4主题在序号为0的队列)消息在CommitLog中的起始物理位置偏移量offset,消息实体内容的大小和Message Tag的哈希值
那么基本的查询步骤为:
首先,通过主题名称,定位到具体的主题文件夹;
然后,根据消息队列ID找到具体的队列文件;
根据文件内容,找到具体的offset的值
最后,再根据offset,去commitlog中定位到消息
4)进入index目录

可以看到索引文件:indexFile由“年月日时分秒”联合组成文件名。IndexFile(索引文件)为rocketmq的消息查询提供了一种除根据offset查询消息外,还可以通过key或时间区间来定位消息的方法
二 总结
总而言之

往期精彩回顾
你有没有想过,旅行的意义是什么?

