




最初发明计算机程序的时候,主要是为了算数。最早出现的高级语言Fortran就是Formula Translation(公式翻译)的缩写。但是现在的程序除了要算数以外,还要处理文本、图片、音频、视频等等数据。网络上的各种文章、微博、微信公众号以及其他社交媒体上每天都在产生大量的无结构数据。公司可以通过分析电商平台的客户文字点评,了解客户对产品的意见,从而进一步迭代产品。因此,文本分析(Text analysis)和自然语言处理(Natural Language Processing,简称NLP)在近些年“进化”很快。
1. 文本分析和NLP
人类最爱干的事情就是坐在一起闲谈。根据说话的形式,可以被称为交流、讨论、辩论等等。由于技术的进步,现在即使人们不在一起,也可以通过短信、电子邮件、QQ、微信等工具交流。这就产生了大量没有任何结构的文本。我们通过分析这些文本,就可以了解人们的观点。
NLP通过计算机技术分析人类语言,从中获取有价值的信息。NLP的用途广泛,它可以发现一段讲话的中心思想,也可以把一种文字翻译成另一种文字。NLP应用的经典案例是通过分析电影评论,了解观众对电影的评价。
2. 文本分析、NLP和文本挖掘(Text Mining)的比较
文本挖掘也是一种文本分析的方法,它通过分析大量的文本数据,找到其中的结构。文本挖掘分析文本,而NLP处理大量的数据。文本挖掘可以要找到关键词、分析句子的长短以及找出哪些词汇经常出现。NLP是文本挖掘的一种方法,它可以发现文章的感情色彩,找到句子的主谓宾语等。文本挖掘是文本分析的准备工作。文本分析利用统计学和机器学习算法对信息分类。
3. 利用NLTK进行文本分析
NLTK(Natural Language Toolkit)是Python自然语言算法库。它不仅功能强大,而且免费易学。我们通过案例,介绍NLTK分析、处理和理解文本的过程。
3.1 标记化(Tokenization)
标记化是文本分析的第一步。所谓标记化,是把一段文字拆分成句子和词汇的过程。标记(Token)是组成句子和段落的单元。
3.2 句子标记化
要使用NLTK,首先要在Python中引用它
import nltk
下载punkt包
nltk.download('punkt')
调用函数sent_tokenize
from nltk.tokenize import sent_tokenize
写一段文字
text="""Hello Mr. Smith, how are you doing today? The weather is great, and city is awesome.The sky is pinkish-blue. You shouldn't eat cardboard"""
标记化并打印结果
tokenized_text=sent_tokenize(text)
print(tokenized_text)
['Hello Mr. Smith, how are you doing today?', 'The weather is great, and city is awesome.The sky is pinkish-blue.', "You shouldn't eat cardboard"]
这样我们就把一段话,变成了几句话。
3.3 单词标记化
我们再来看单词标记化。它可以把一段话编成一串单词。
from nltk.tokenize import word_tokenize
tokenized_word=word_tokenize(text)
print(tokenized_word)
['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'city', 'is', 'awesome.The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard']
这样,一段话就被分割为若干单词。
3.4统计分析
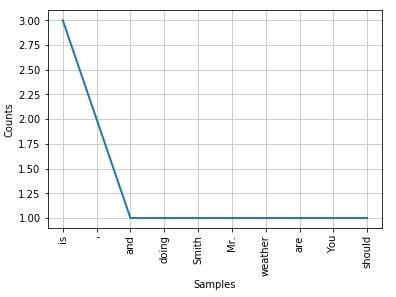
最常见的功能就是看那个词汇出现的频率最高。我们可以看出,在这段文字中,出现频率最高的单词是‘is’,它出现了3次。然后是逗号‘,’,它出现了2次。
from nltk.probability import FreqDist
fdist = FreqDist(tokenized_word)
fdist.most_common(2)
[('is', 3), (',', 2)]
我们可以把出现排名前十的单词画出来,如图1所示。
import matplotlib.pyplot as plt
fdist.plot(10,cumulative=False)
plt.show()
图1. 出现排名前十的单词
3.5 停顿词(Stopwords)
人类的语言中有很多出现频率很高,但不是很重要的词。比方说‘is’,‘am’,‘are’等等。我们可以过滤掉这些词汇。NLTK中有停顿词库,我们可以下载看到。
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words=set(stopwords.words("english"))
print(stop_words)
set([u'all', u'just', u"don't", u'being', u'over', u'both', u'through', u'yourselves', u'its', u'before', u'o', u'don', u'hadn', u'herself', u'll', u'had', u'should', u'to', u'only', u'won', u'under', u'ours', u'has', u"should've", u"haven't", u'do', u'them', u'his', u'very', u"you've", u'they', u'not', u'during', u'now', u'him', u'nor', u'd', u'did', u'didn', u'this', u'she', u'each', u'further', u"won't", u'where', u"mustn't", u"isn't", u'few', u'because', u"you'd", u'doing', u'some', u'hasn', u"hasn't", u'are', u'our', u'ourselves', u'out', u'what', u'for', u"needn't", u'below', u're', u'does', u"shouldn't", u'above', u'between', u'mustn', u't', u'be', u'we', u'who', u"mightn't", u"doesn't", u'were', u'here', u'shouldn', u'hers', u"aren't", u'by', u'on', u'about', u'couldn', u'of', u"wouldn't", u'against', u's', u'isn', u'or', u'own', u'into', u'yourself', u'down', u"hadn't", u'mightn', u"couldn't", u'wasn', u'your', u"you're", u'from', u'her', u'their', u'aren', u"it's", u'there', u'been', u'whom', u'too', u'wouldn', u'themselves', u'weren', u'was', u'until', u'more', u'himself', u'that', u"didn't", u'but', u"that'll", u'with', u'than', u'those', u'he', u'me', u"wasn't", u'myself', u'ma', u"weren't", u'these', u'up', u'will', u'while', u'ain', u'can', u'theirs', u'my', u'and', u've', u'then', u'is', u'am', u'it', u'doesn', u'an', u'as', u'itself', u'at', u'have', u'in', u'any', u'if', u'again', u'no', u'when', u'same', u'how', u'other', u'which', u'you', u"shan't", u'shan', u'needn', u'haven', u'after', u'most', u'such', u'why', u'a', u'off', u'i', u'm', u'yours', u"you'll", u'so', u'y', u"she's", u'the', u'having', u'once'])
接下来,我们就可以删除这些停顿词。
filtered_sent=[]
for w in tokenized_word:
if w not in stop_words:
filtered_sent.append(w)
以下是原来标记化的单词
print("Tokenized Sentence:",tokenized_word)
('Tokenized Sentence:', ['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'city', 'is', 'awesome.The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard'])
经过过滤后,停顿词不见了。
print("Filterd Sentence:",filtered_sent)
('Filterd Sentence:', ['Hello', 'Mr.', 'Smith', ',', 'today', '?', 'The', 'weather', 'great', ',', 'city', 'awesome.The', 'sky', 'pinkish-blue', '.', 'You', "n't", 'eat', 'cardboard'])
3.6词汇的统一
在英语中,有些词汇虽然形式不同,但其实是同一个单词。比方说translation,translating, translated都是单词translate的变形。我们需要把这些词汇统一。
我们可以通过封堵(stemming)的办法找到不同单词的词根。比方说,translation,translating, translated都可以变成translate。
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
ps = PorterStemmer()
stemmed_words=[]
for w in filtered_sent:
stemmed_words.append(ps.stem(w))
以下是过滤后的句子。
print("Filtered Sentence:",filtered_sent)
('Filtered Sentence:', ['Hello', 'Mr.', 'Smith', ',', 'today', '?', 'The', 'weather', 'great', ',', 'city', 'awesome.The', 'sky', 'pinkish-blue', '.', 'You', "n't", 'eat', 'cardboard'])
对比一下封堵后的句子
print("Stemmed Sentence:",stemmed_words)
('Stemmed Sentence:', ['hello', 'mr.', 'smith', ',', 'today', '?', 'the', 'weather', 'great', ',', u'citi', u'awesome.th', u'sky', u'pinkish-blu', '.', 'you', "n't", 'eat', 'cardboard'])
还有一些单词的问题更加复杂。比方说‘good’,‘better’和‘best’其实是一个单词。但是它们看起来一点也不像。这就需要用到词形还原(Lemmatization)。
from nltk.stem.wordnet import WordNetLemmatizer
nltk.download('wordnet')
lem = WordNetLemmatizer()
from nltk.stem.porter import PorterStemmer
stem = PorterStemmer()
比方说‘flying’这个单词,用词形还原可以得到fly。但是如果用封堵的办法,就会得到fli。
word = "flying"
print("Lemmatized Word:",lem.lemmatize(word,"v"))
print("Stemmed Word:",stem.stem(word))
('Lemmatized Word:', u'fly')
('Stemmed Word:', u'fli')
3.7 POS标记
词语可以分为名词、动词、形容词等。部分讲话(Part-of-Speach,简称POS)的目标是从语法上判断某个单词的词性。
nltk.download('averaged_perceptron_tagger')
有一句话“Albert Einstein was born in Ulm, Germany in 1879.”
sent = "Albert Einstein was born in Ulm, Germany in 1879."
标记化以后变成
tokens=nltk.word_tokenize(sent)
print(tokens)
['Albert', 'Einstein', 'was', 'born', 'in', 'Ulm', ',', 'Germany', 'in', '1879', '.']
用到POS标记后,就可以看到每个词的词性。
nltk.pos_tag(tokens)
[('Albert', 'NNP'),
('Einstein', 'NNP'),
('was', 'VBD'),
('born', 'VBN'),
('in', 'IN'),
('Ulm', 'NNP'),
(',', ','),
('Germany', 'NNP'),
('in', 'IN'),
('1879', 'CD'),
('.', '.')]
当然需要注明一下:
NNP:专有名词
VBD:动词过去式
VBN:动词过去分词
CD:基数词
IN:介词
(未完待续!)
