





B Tree和B+Tree
而系统一个磁盘块的存储空间往往没有这么大,因此InnoDB每次申请磁盘空间时都会是若干地址连续磁盘块来达到页的大小16KB。InnoDB在把磁盘数据读入到磁盘时会以页为基本单位,在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘I/O次数,提高查询效率。
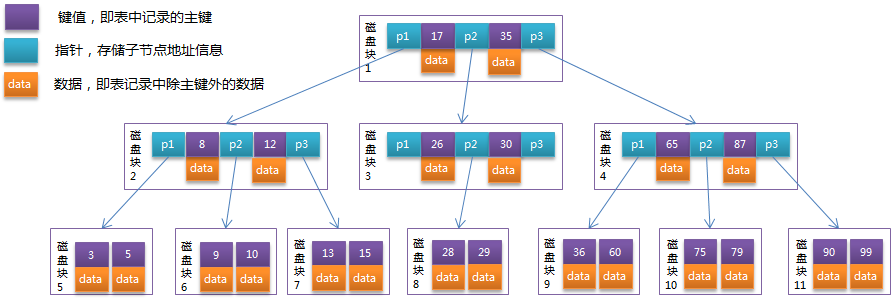
从B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
由于B+Tree的非叶子节点只存储键值信息,假设每个磁盘块能存储4个键值及指针信息,则变成B+Tree后其结构如下图所示:
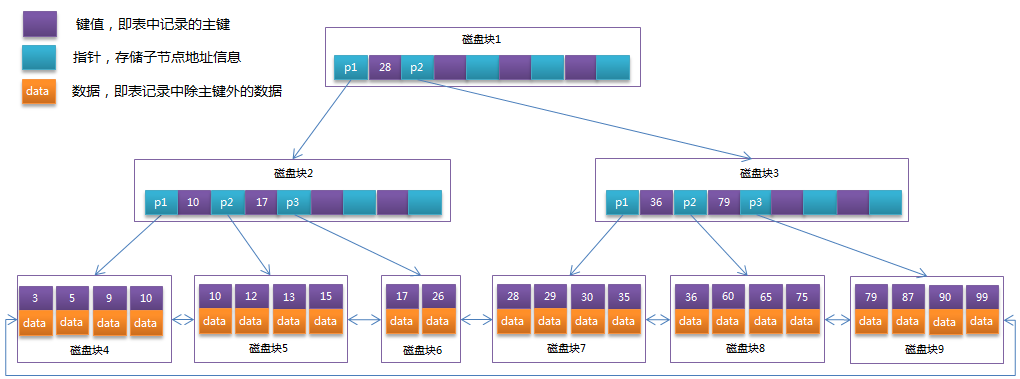
通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
B+Tree相对于B-Tree有的不同可以通过如下几点进行归纳:
非叶子节点只存储键值信息
所有叶子节点之间都有一个链指针
数据记录都存放在叶子节点中

B-Link Tree的核心主张
第一,在中间节点增加字段link pointer,指向右兄弟节点,B-link Tree的名字也由此而来。
第二,在每个节点内增加一个字段high key,在查询时如果目标值超过该节点的high key,就需要循着link pointer继续往后继节点查找。
一棵典型的B-link Tree如下:
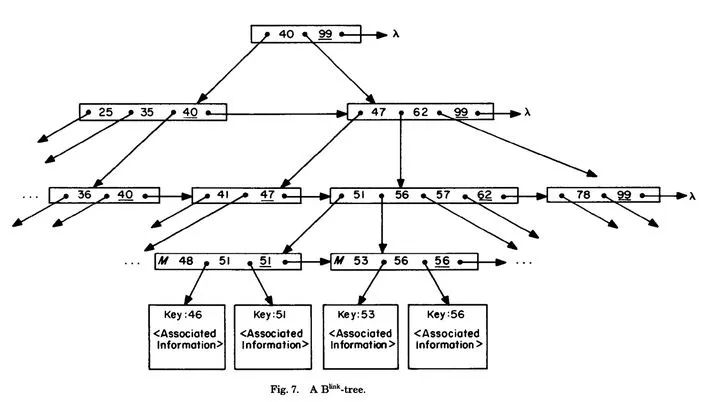
图中我们看到,每个中间节点也增加了一个后继指针指向其右兄弟节点,如果要查询的值超过该节点内的high key,那么还需要查询其后继节点。
我们举例说明B-link Tree的优势。假设有下面这样一颗B+ Tree且叶子节点y已满:
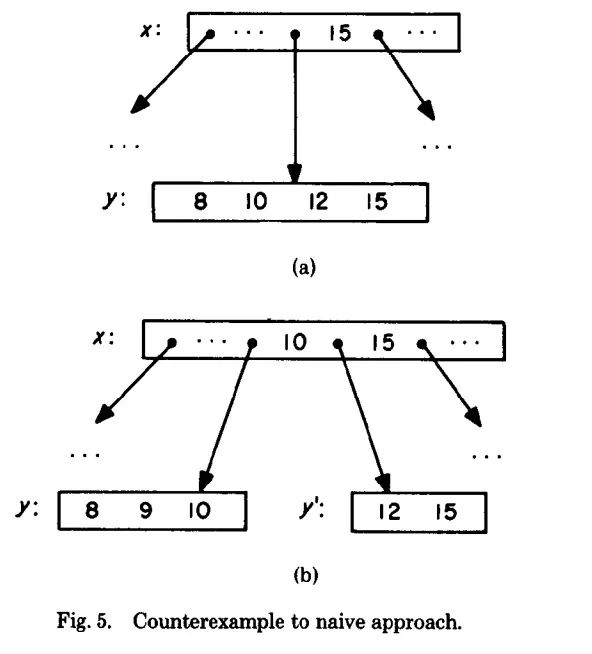
假如此时线程A要查询15,而线程B要在节点y内插入值9,我们看下面的执行序列:

如果不作任何的并发保护,就会出现由于节点分裂而导致访问了错误叶子节点进而查找的目标值不存在问题,很明显这与实际情况不符。
最简单的方案是在树结构调整时使用全局锁住整棵B+ Tree,阻止一切并发访问直到树结构调整完毕,InnoDB早期也是采取了该做法,当然这会导致性能特别差。
而B-link Tree则拒绝全局锁这一做法。它执行一种自底向上的调整方法,每次只对当前调整节点加锁,当子节点调整完毕后再向上回溯调整父节点,直到所有调整完毕。
下图演示了插入新记录引发的节点分裂过程:首先创建新节点,将原节点上的部分数据拷贝至新节点,建立这两个节点的连接关系(这个步骤最为关键),最后再向其父节点插入新的索引节点(图中d和e)。
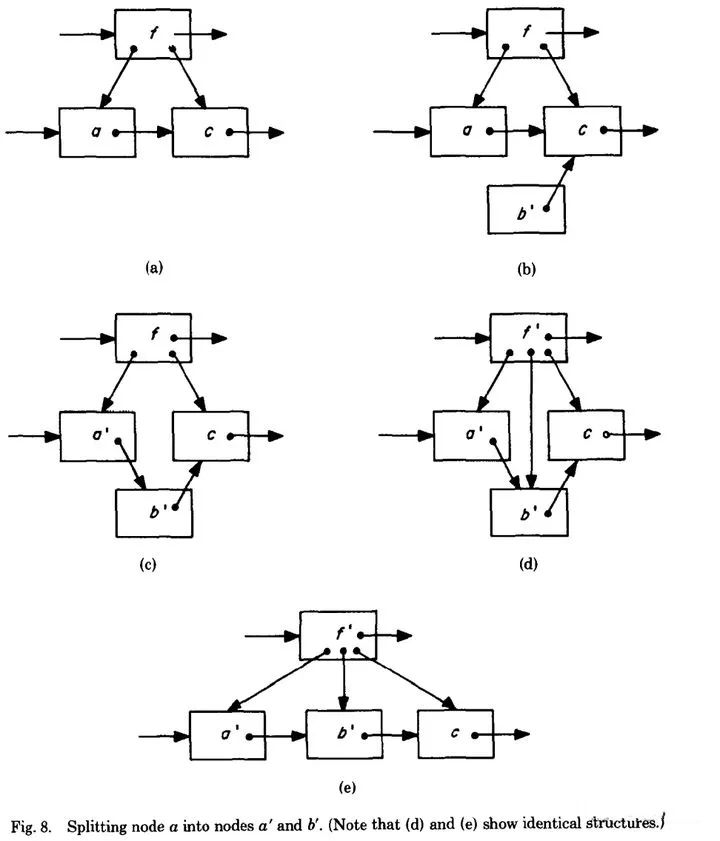
B-link Tree这种无需加锁的设计可能导致的问题是父节点视图(尚未插入新索引)和已经分裂的子节点不一致,那它是如何解决上面提出的问题呢?
这时候link pointer便显示出了价值。如果其他线程在子节点修改完成后但父节点修改前访问,顺着父节点查询到旧的子节点时可能查不到已有数据,此时就需要沿着该子节点通过其link pointer找到正确的访问路径。
同样还是上面的例子:
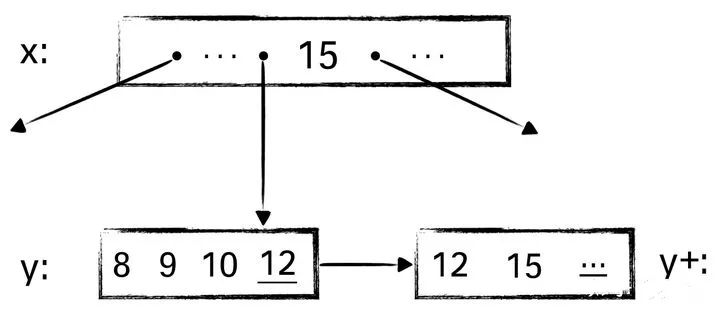
当节点y分裂成为y和y+两个节点后,而父节点x中尚未体现出这种分裂,此时查找15,顺着x找到节点y,在y中未能找到15,但判断15大于其中记录的high key,于是顺着指针找到其后继节点y+,最终找到该值,因而能确保正确性。
在B-link Tree的分裂方案中并没有对涉及分裂的子树加全局锁,但通过节点的右连接指针也可以正确地进行查找。

B-link Tree优劣势总结
B-link Tree的优势在于树结构调整时无需对全局或者局部子树加锁,进而有利于高并发下的性能稳定性。
而B-link Tree的劣势则主要集中在以下两个方面:
第一,每个节点增加额外字段,link pointer和high key,但代价不大;
第二,查询时需要额外判断,如果查询找超过high key,需要额外通过link pointer查询其后继节点,在数据库应用中可能会产生一次额外的IO,从而造成单次查找性能的下降,但由于树结构调整是一个频率较低的动作,而且查询后继节点的操作也只会发生在子节点调整和父节点调整过程之间,一旦父节点调整完毕,就可以通过父节点的指针直接查询了而无需再通过子节点的后继指针查找。
总结来看,B-link Tree通过空间换时间,在每个中间节点也增加后继指针来避免在树结构调整时全局加锁而带来性能衰退,这是一种很优秀的方案,在GreenPlum中就使用了B-link Tree来作为其存储引擎的索引。

