




索引:一种数据结构。目的在于提高数据的查找效率。
mysql的默认索引结构是b+树。
b+树的索引的结构:
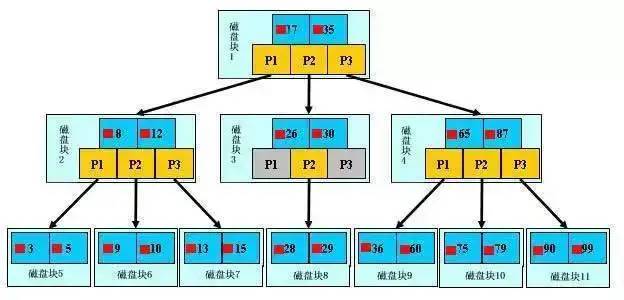
b+树的查找数据过程:
要查找数据28:先将磁盘中的磁盘块1加载到内存中,进行一次i/o,通过二分查找获取到p2指针,然后p2指针指向磁盘块3,将磁盘块3加载到内存中,28介于26-30之间,获取到磁盘块3的p2指针,然后再加载磁盘块8的数据,二分查找获取到28数据。总共3次磁盘io。
索引是存储引擎级别的概念,不同的存储引擎对索引的实现是不同的。
myisam引擎对索引的实现:
1. myisam使用b+树作为索引结构,它的data域存放的是数据记录的地址。
2. 数据文件和索引文件是分离的,单独存在。
3.在myisam中,主索引和辅助索引本身数据结构上没有任何区别,只是主索引要求key是唯一的,辅助索引可以是重复的。
innodb引擎对索引的实现:
1.innodb也是使用b+树作为索引结构。但是最大的不同点首先是innodb的数据文件本身就是索引文件。它的data域存放的就是完整的数据记录,它的key就是数据表的主键。
2.这种包含了完整数据记录的索引叫做聚簇索引(默认每个表的主键就是聚簇索引)。这种索引本身需要按照主键排序的,所以文件本身必须有一个主键,如果没有指定的话,则会默认指定一个可以作为数据唯一标志的列作为主键。如果没有满足条件的列,mysql则会为innodb新增一个隐含字段作为主键,这个主键默认6字节的长整形。
3.它的主索引和辅助索引的不同点在于,主索引的data域存放的是数据记录本身,而辅助索引的data域存放的则是主键值。
4.所以使用主键查询时,会直接返回数据,而使用非主键索引查询则先查找辅助索引,查找到对应的主键,然后再使用主键,去主索引那里获取数据。也就是所谓的回表。
注:
1.不建议使用过长的字段作为主键,因为辅助索引需要引用主键索引的值,过长的话,则会使辅助索引变的过大。
2.不建议使用非自增的字段作为主键,因为非自增的字段作为主键,为了维持b+树的特性,每次的插入数据都需要重新对数据进行分裂和排序,非常的低效。
建立索引的注意点:
1.满足最左匹配原则。例如建立一个(a,b,c)的联合索引,就相当于建立了(a), (a,b), (a,b,c)3个索引, 它会一次查找a,b,c,当遇到范围查询(<,>,
between,like)的时候,就会停止查询。
比如: (a,b,c3个字段顺序可以打乱)
where a=1 and b=2 and c=3 可以使用索引(a,b,c)
where a=1 and b>2 and c=3. 只能使用索引(a,b)
where a>1 and b=2 and c=3. 只能使用索引(a)
2.尽量选择区分度高的列作为索引,这样搜索的时候可以一次筛掉更多的数据。
3.索引列不要做计算。做计算的话,无法使用索引
4.索引不要新建过多。因为索引需要占用空间,每次更新数据的时候都需要更新对应的索引,消耗时间和资源。
注:为什么不使用hash索引?
1.哈希索引不支持范围查询,只能等值查询
2.哈希索引无法进行排序
3.不支持最左匹配原则
4.字段值大量重复,会产生哈希碰撞,效率比较低
