




前言
今天早上在测试一个SQL的时候,性能很慢。这个SQL是统计类的SQL,不是很适合在OLTP这样的数据库里面跑,但是总有这种类型的要求。所以我思考是不是可以用列式存储来解决一下这类的需求。
列式存储
首先我们还是按照惯例来科普一下列式存储的概念。我们以Appace Arrow的图来说明一下。

这是一张典型的用户资料表,左边是行存,传统的关系型数据库都是这样存储方式。而右边的是列存,每一个列都单独进行存放,数据既是索引。如果我们只查询涉及到的列,将大大的减少读取I/O。如下面这个语句:
select max(age) from users;
而列存还有一个好处就是数据类型一致、数据特征相似,它可以进行高效的压缩。
PostgreSQL列式存储引擎
针对PostgreSQL数据库来说,我了解了一下,目前有这么几种列式存储引擎。
cstore_fdw 由Citus Data公司开发的一款列存插件,Cstore_fdw 采用 Optimized Row Columnar (ORC) 格式作为它的物理存储格式。ORC改进了Facebook的RCFile格式。(https://github.com/citusdata/cstore_fdw) vops 这个主要思想是通过使用向量化操作与现有的执行器和堆管理器来实现加速。(https://github.com/postgrespro/vops) Zedstore 来源于greenplum。https://github.com/greenplum-db/postgres/tree/zedstore) IMCS 也叫In-Memory Columnar Store。这个类似于Oracle的In-Memory Column Store,就是在专门分配出一块内存把行在内存中转换成列。(https://github.com/knizhnik/imcs) Swarm64 DA,能免费使用一年。提供Columnstore Index的功能。 Fujitsu VCI,创造了一个新的思路,添加了新的索引方法 (VCI),在表上创建列式索引。
cstore_fdw
Cstore_fdw 依赖 protobuf-c 包来实现序列化和反序列化表的元数据信息,因此需要先安装 protobuf-c
yum install protobuf-c-develwget -c https://github.com/citusdata/cstore_fdw/archive/refs/tags/v1.7.0.zipunzip v1.7.0.zip cd cstore_fdw-1.7.0/
如果你没有外网,centos 7系统需要安装下面5个软件包。
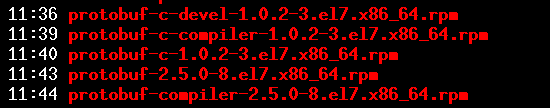
USE_PGXS=1 makemake install
安装好插件,设置参数shared_preload_libraries
create extension cstore_fdw;alter system set shared_preload_libraries=pg_stat_statements,cstore_fdw
然后重启数据库。
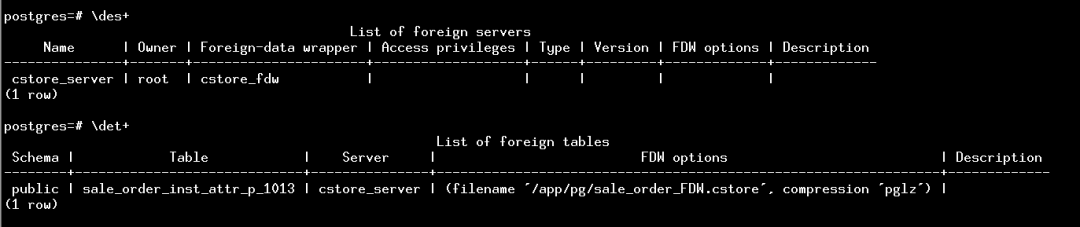
接下来需要创建外部服务器和外部表。
CREATE SERVER cstore_server FOREIGN DATA WRAPPER cstore_fdw;create foreign table sale_order_inst_attr_p_1013 ( order_inst_attr_id numeric(12,0), attr_id numeric(12,0), attr_name character varying(100), attr_value character varying(2000), create_date timestamp(0) without time zone, status_date timestamp(0) without time zone, eff_date timestamp(0) without time zone, exp_date timestamp(0) without time zone, latn_id numeric(4,0), sale_order_id numeric(12,0), link_inst_id numeric(12,0), link_id numeric(12,0), eff_state numeric(2,0), last_sale_order_id numeric(12,0))server cstore_serverOPTIONS(filename '/app/pg/sale_order_FDW.cstore',compression 'pglz');
这里有几个参数需要我们设置一下:
filename 文件名,存储表数据的位置的绝对路径。如果不指定文件名选项,cstore_fdw将自动选择$PGDATA/cstore_fdw目录来存储文件。像我这里的设置为/app/pg/sale_order_FDW.cstore,这个文件将存储表的数据,而/app/pg/sale_order_FDW.cstore.footer则用来存储表的元数据信息。 compression ,压缩算法。有效选项是 none
和pglz
。默认值为none
。stripe_row_count ,每个条带的行数。默认值为 150000
,这个值越小,用于加载数据和查询的内存量就越少,但是会降低性能。block_row_count,每个列数据块中的行记录数,默认为 10000
,压缩数据、创建跳跃索引以及磁盘读取时都是以块 (block) 为最小单元。这个值越大,压缩的越小,从而可以减少磁盘的读取次数。当然也会降低跳过不相关行块的可能性。
建完表后,我们使用pg_dump把数据表从生产环境导进来。
postgres=# select count(1) from sale_order_inst_attr_p_1013; count ---------- 13754836(1 row)
我们先来看看传说中的压缩比例。
ycl=# SELECT pg_size_pretty( pg_total_relation_size('sale_order_inst_attr_p_1013')); pg_size_pretty ---------------- 2633 MB(1 row)[pg@test-pg-01 ~]$ ls -lsh /app/pg/sale_order_FDW.cstore370M -rw-------. 1 postgres postgres 370M Jul 1 14:44 /app/pg/sale_order_FDW.cstore
在测试数据库,是2633MB大小,而使用cstore_fdw的情况下是370MB,压缩还是很明显的。
继续搞个OLAP型的SQL进行测试。
在oltp数据库中执行:
ycl=# explain analyze select attr_name,count(1) from sale_portal.sale_order_inst_attr_p_1013 group by attr_name order by 2; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Sort (cost=370943.14..370943.28 rows=55 width=20) (actual time=1985.707..1985.710 rows=66 loops=1) Sort Key: (count(1)) Sort Method: quicksort Memory: 29kB -> Finalize GroupAggregate (cost=370927.61..370941.55 rows=55 width=20) (actual time=1985.529..1985.686 rows=66 loops=1) Group Key: attr_name -> Gather Merge (cost=370927.61..370940.45 rows=110 width=20) (actual time=1985.517..2043.982 rows=183 loops=1) Workers Planned: 2 Workers Launched: 2 -> Sort (cost=369927.59..369927.73 rows=55 width=20) (actual time=1981.154..1981.157 rows=61 loops=3) Sort Key: attr_name Sort Method: quicksort Memory: 29kB Worker 0: Sort Method: quicksort Memory: 29kB Worker 1: Sort Method: quicksort Memory: 29kB -> Partial HashAggregate (cost=369925.45..369926.00 rows=55 width=20) (actual time=1979.754..1979.763 rows=61 loops=3) Group Key: attr_name -> Parallel Seq Scan on sale_order_inst_attr_p_1013 (cost=0.00..341268.30 rows=5731430 width=12) (actual time=0.017..827.021 rows=4585001 loops=3) Planning Time: 0.102 ms Execution Time: 2044.139 ms(18 rows)
在cstore_fdw中执行
postgres=# explain analyze select attr_name,count(1) from sale_order_inst_attr_p_1013 group by attr_name order by 2; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------------------------ Sort (cost=209705.58..209705.72 rows=56 width=20) (actual time=4129.375..4129.380 rows=66 loops=1) Sort Key: (count(1)) Sort Method: quicksort Memory: 29kB -> HashAggregate (cost=209703.40..209703.96 rows=56 width=20) (actual time=4129.338..4129.348 rows=66 loops=1) Group Key: attr_name -> Foreign Scan on sale_order_inst_attr_p_1013 (cost=0.00..140929.22 rows=13754836 width=12) (actual time=0.753..1411.814 rows=13754836 loops=1) CStore File: /app/pg/sale_order_FDW.cstore CStore File Size: 387740844 Planning Time: 0.169 ms Execution Time: 4129.663 ms(10 rows)
居然列存执行的速度还不如行的。这个打击有点大啊,不过这也算正常,我这个表的数据量毕竟还是太小了,不能凸显出它的威力,我们需要制造更大的表,才能体现列式数据库的真正的效果。
我在制造了一个表,插入10亿数据。
ycl=# create table "test_table" (id1 integer);CREATE TABLEycl=# insert into "test_table" select generate_series(1,1000000000);INSERT 0 1000000000ycl=# explain analyze SELECT sum(id1) from test_table WHERE id1 between 100 and 8000; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=10675779.10..10675779.11 rows=1 width=8) (actual time=27376.421..27376.422 rows=1 loops=1) -> Gather (cost=1000.00..10675779.10 rows=1 width=4) (actual time=19827.248..27852.700 rows=7901 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Seq Scan on test_table (cost=0.00..10674779.00 rows=1 width=4) (actual time=19821.366..27363.476 rows=2634 loops=3) Filter: ((id1 >= 100) AND (id1 <= 8000)) Rows Removed by Filter: 333330700 Planning Time: 0.127 ms Execution Time: 27853.346 ms
直接查询sum统计需要27秒左右,那么我们用cstore_fdw执行同样的查询,只需要265ms,是一个巨大的性能提升。
postgres=# explain analyze SELECT sum(id1) FROM test_table WHERE id1 between 1000 and 8000; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=15516467.00..15516467.01 rows=1 width=8) (actual time=265.199..265.201 rows=1 loops=1) -> Foreign Scan on test_table (cost=0.00..15503967.00 rows=5000000 width=4) (actual time=2.243..264.612 rows=7001 loops=1) Filter: ((id1 >= 1000) AND (id1 <= 8000)) Rows Removed by Filter: 2999 CStore File: /app/pg/test_table.cstore CStore File Size: 4128490480 Planning Time: 155.547 ms Execution Time: 265.411 ms(8 rows)
这里条件使用了一个范围查询。具体的原理就是cstore_fdw 将每一列分成多个块,每一块都会有存储最大值和最小值,就类似于Brin Index一样。所以我们在执行扫描的时候,它就会根据你where条件的值去跳过块进行扫描,这样查询的数据就更少,IO也就更少,速度也就越快。

如果我们在行式数据库上创建Brin索引,使用这样的SQL执行速度也是可以的。
ycl=# create index idx_brin on test_table USING brin(somedata);CREATE INDEXycl=# explain analyze SELECT sum(somedata) from "test_table" WHERE somedata between 100 and 8000; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=109160.10..109160.11 rows=1 width=8) (actual time=24.950..24.950 rows=1 loops=1) -> Bitmap Heap Scan on test_table (cost=373.03..109160.10 rows=1 width=4) (actual time=16.676..23.760 rows=7901 loops=1) Recheck Cond: ((somedata >= 100) AND (somedata <= 8000)) Rows Removed by Index Recheck: 21027 Heap Blocks: lossy=128 -> Bitmap Index Scan on idx_brin (cost=0.00..373.03 rows=28928 width=0) (actual time=16.632..16.632 rows=1280 loops=1) Index Cond: ((somedata >= 100) AND (somedata <= 8000)) Planning Time: 0.114 ms Execution Time: 25.004 ms(9 rows)
对于统计型SQL这一块测试的文章,可以参考国外Mark Litwintschik写的https://tech.marksblogg.com/billion-nyc-taxi-rides-postgresql.html
它导入了一张281GB大小的表,11亿条记录。
SELECT cab_type,count(*) FROM trips GROUP BY cab_type
在不使用并行的情况是3.5个小时,在使用4个并行的情况下,执行时间是1小时1分。如果换成cstore_fdw来进行存储,这个SQL执行只需要2分32秒。所以性能提升还是巨大的。
限制
最后来说说这个插件的限制吧,限制主要有以下几点:
不支持使用 DELETE 和 UPDATE 命令更新表 不支持单行插入
后记
经过简单的试用之后,我个人觉得cstore_fdw插件比较适合将历史静态数据进行归档处理。依靠它的压缩技术,可以节省足够更多的存储出来。
参考文档:
1.https://github.com/citusdata/cstore_fdw2.https://tech.marksblogg.com/billion-nyc-taxi-rides-postgresql.html3.https://info.citusdata.com/rs/235-CNE-301/images/Columnar_Store_for_PostgreSQL_Using_cstore_fdw_Webinar_Slides_0915.pdf
