日志采集常见错误总结:
采集日志过程中简单错误
1.自定义拦截器 使用了第三方jar包
需要在pom中加入打包的工具依赖 否则打包的jar包弄到集群上会没有依赖 比如fastjson
<build>
<plugins>
<!-- 打jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.采集数据 .* 不是以.结尾的所有的文件 这是一个正则表达式 比如event.* 会匹配以event开头的所有的文件
3.如果需要选择器 type=multiplexing 是负载均衡 a拿了b就不会拿
4.拦截器的type 里面有内部类 内部类需要用$连接 且代码中内部类 需要用static 否则报错,因为需要先实例化
5.采集过来的数据需要后缀名需要加上.gz 且下游sink要使用压缩的形式压缩数据
a1.sinks.k1.hdfs.codeC = gzip
a1.sinks.k1.hdfs.fileType = CompressedStream 否则 hdfs不能将不能识别出这种压缩数据
6.多次采集失败 每次重新采集需要 删掉上游source的偏移量和下游channel的记录的偏移量
具体在 rm -rf
/opt/data/flumedata /root/.flume 不过以后采集正常了就不要再删了,否则将从最开始采集数据,会积压很多数据
其他是一些不细心的小问题,配置文件用的时候 参考实战日志采集
高级错误
1. flume的agent的堆内存大小
默认只有20M,在生产中是肯定不够的
一般需要给到1G
vi bin/flume-ng
搜索 Xmx ,并修改
2.channel阻塞
启动flume之前,积压的数据过多,所以,source读得很快,而sink写hdfs速度有限,会导致反压
反压从下游传递到上游,上游的flume的运行日志中会不断报:channel已满,source重试
这里就涉及到flume的运行监控
如果通过监控,发现channel频繁处于阻塞状态,可以通过如下措施予以改善(优化):
a. 如果资源允许,可以增加写入hdfs的agent机器数,通过负载均衡来提高整体吞吐量
b. 如果资源不允许,可以适当增大batchSize,来提高写入hdfs的效率
c. 如果资源不允许,可以配置数据压缩,来降低写入hdfs的数据流量
d. 如果source的数据流量不是恒定大于sink的写出速度,可以提高channel的缓存容量,来削峰
3.如果agent进程宕机,如何处理?
下游宕机:问题不大,我们配置高可用模式,会自动切换;当然,还是要告警,通知运维尽快修复;
上游宕机:问题较大,通过脚本监控进程状态,发现异常则重新拉起agent进程;并告警通知运维尽快查明原因予以修复;
agent进程监控:
FLUME在运行时,状态是否正常,吞吐量是否正常,需要监控
Flume自身具有向外提交状态数据的功能;但是它本身没有一个完善的监控平台;
开启内置监控功能
-Dflume.monitoring.type=http -Dflume.monitoring.port=34545

将监控数据发往ganglia进行展现
-Dflume.monitoring.type=ganglia -Dflume.monitoring.port=34890
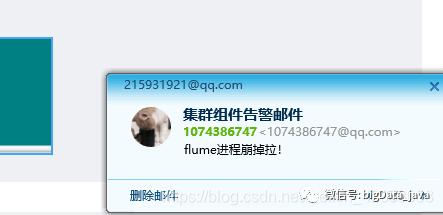
脚本监控并唤醒进程,且发送邮件通知相关人员,尽快修复:
#!/bin/bash
export JAVA_HOME=/opt/apps/jdk1.8.0_191/
export HADOOP_HOME=/opt/apps/hadoop-3.1.1/
export HBASE_HOME=/opt/apps/hbase-2.0.6/
查看所有的"....application"的详细 进程 -e 显示所有进程 -f 全格式
反选 选择不带有grep的进程 并统计行数
num=`ps -ef | grep "org.apache.flume.node.Application" | grep -v "grep" | wc -l`
定义一个方法,以启动flume进程
start(){
/opt/apps/flume-1.9.0/bin/flume-ng agent -c /opt/apps/flume-1.9.0/conf -f /opt/apps/flume-1.9.0/agentsconf/doit19-xiayou.conf -n a1
}
if [ $num -eq 1 ]
then
echo "ok"
else
echo "flume进程崩掉拉!"
echo "flume进程崩掉拉!" | mail -s "集群组件告警邮件" 215931921@qq.com
start
fi
脚本写好了
1)接下来,现在集群中装邮件的服务
yum install mailx -y
2)配置邮件账号、服务器等
vi /etc/mail.rc
set bsdcompat
set smtp=smtp.qq.com # 这里填入smtp地址
set smtp-auth=login # 认证方式
set smtp-auth-user=1074386747@qq.com # 这里输入邮箱账号
set smtp-auth-password=xxxxxxx # 这里填入密码,这里是授权码而不是邮箱密码
set ssl-verify=ignore # 忽略证书警告
#set nss-config-dir=/etc/pki/nssdb # 证书所在目录
set from=1074386747@qq.com 周星星 # 设置发信人邮箱和昵称