本文主要介绍如何在 IDEA 中实现 Flink 的 Checkpoint Restore。完整代码参考:github:https://github.com/1996fanrui/fanrui-learning/tree/master/module-flink/src/main/java/com/dream/flink/state/restore/ide
1、IDEA 中直接运行 Flink 代码
Flink 代码很容易在 IDEA 中运行,方便用户调试、定位问题。如下图所示,点击绿色的 Run 按钮,即在 IDEA 中开始运行 Flink Job。
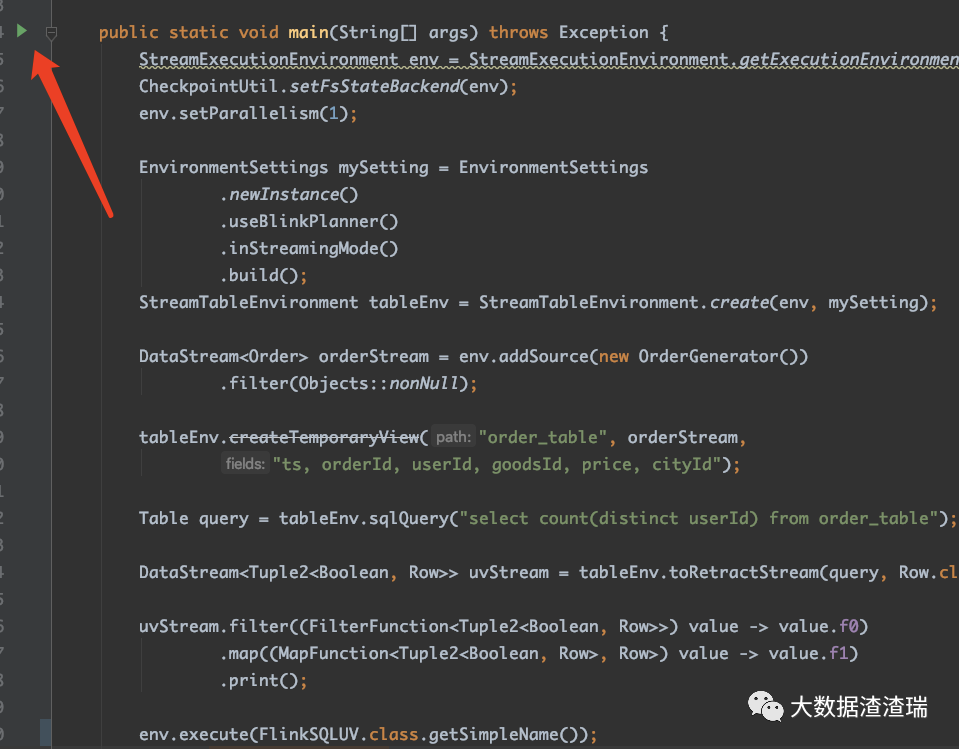
IDEA 中运行 Flink Job,就是在 env.execute() 中将任务提交到 MiniCluster 中。
有些用户可能会说:我在本地 IDEA 中直接运行会报错,类似于 ClassNotFound 的错误。一般这种错误是因为有些 Maven 依赖在运行时依赖不到。
简单的方法:直接下载渣渣瑞的 flink 项目,都是配置好的,链接:https://github.com/1996fanrui/fanrui-learning
IDEA 中直接运行 Flink Job 简单方便,但是存在一些痛点。例如,渣渣瑞创建的《大数据技术交流群》里前几天有群友问:有人试过本地 IDEA 运行任务从 Savepoint 处启动吗?
其实渣渣瑞之前也有类似的需求,有时候想本地调试 Checkpoint 恢复的流程,但 IDEA 运行 Job 一般都是直接启动的方式,根本不会运行 restore 相关的流程。
基于上述的需求背景,渣渣瑞开始研究一波骚操作可以在 IDEA 中指定 Checkpoint 或 Savepoint 目录进行 restore。最后封装的代码非常简单。
2、IDEA 中实现 Restore
其实 Flink 源码中有很多的测试案例,用来验证 Flink Job 的 Checkpoint 和 Restore。渣渣瑞就模拟源码中的实现去设计,具体源码参考 ResumeCheckpointManuallyITCase 类。
这里多唠两句,阅读源码的单元测试也是一个熟悉源码的过程。通过测试案例可以了解被测试类的功能,是了解源码的一些途径。一般单元测试中会考虑到边界条件、异常条件,通过阅读单测可以学习大佬们严谨的思想。
借鉴源码中的思想设计完以后,封装了 CheckpointRestoreByIDEUtils 工具类。如果想让 Flink Job 从 Checkpoint 目录 Restore,代码改动非常小 ,只需要改两行代码即可。
正常的 Flink DataStream 的代码最后一行执行 env.execute(),现在只需要替换成 CheckpointRestoreByIDEUtils.run(env.getStreamGraph(), externalCheckpoint) 即可。如下图所示,注释掉 env.execute(),新增了两行代码。

重点在于 CheckpointRestoreByIDEUtils 类 run 方法的实现,参考注释:
public static void run(
@Nonnull StreamGraph streamGraph,
@Nullable String externalCheckpoint) throws Exception {
// 根据 StreamGraph 生成 JobGraph
JobGraph jobGraph = streamGraph.getJobGraph();
if (externalCheckpoint != null) {
// 将 Checkpoint 目录设置到 JobGraph 中
jobGraph.setSavepointRestoreSettings(SavepointRestoreSettings.forPath(externalCheckpoint));
}
// 计算 jobGraph 需要的 slot 个数
int slotNum = getSlotNum(jobGraph);
// 初始化 MiniCluster
ClusterClient<?> clusterClient = initCluster(slotNum);
// 提交任务到 MiniCluster
clusterClient.submitJob(jobGraph).get();
}复制
run 方法实现很简单,有一个操作比较有意思,即:如何计算 jobGraph 需要的 slot 个数。感兴趣的同学可以看一下代码实现。完整代码在 github:https://github.com/1996fanrui/fanrui-learning/tree/master/module-flink/src/main/java/com/dream/flink/state/restore/ide
这里涉及到 Flink slotSharingGroup 的概念。默认情况下,Flink 只有一个 slotSharingGroup,即:default。概念比较生硬,举个例子:假设 Flink Job 中有三个算子 A 和 B,没有单独指定 slotSharingGroup,算子 A 的并行度为 10,算子 B 的并行度为 15,算子 C 的并行度为 20。那么任务总共只需要申请 20 个 slot。