





在数据时代,过多耗内存的大查询都有可能压垮整个集群,所以其内存管理模块在整个系统中扮演着非常重要的角色。
而PolarDB-X 作为一款分布式数据库,其面对的数据可能从TB到GB字节不等,同时又要支持TP和AP Workload,要是在计算过程中内存使用不当,不仅会造成TP和AP相互影响,严重拖慢响应时间,甚至会出现内存雪崩、OOM问题,导致数据库服务不可用。
CPU和MEMORY相对于网络带宽比较昂贵,所以PolarDB-X 代价模型中,一般不会将涉及到大量数据又比较耗内存的计算下推到存储DN,DN层一般不会有比较耗内存的计算。这样还有一个好处,当查询性能不给力的时候,无状态的CN节点做弹性扩容代价相对于DN也低。
鉴于此,所以本文主要对PolarDB-X计算层的内存管理进行分析,这有助于大家有PolarDB-X有更深入的理解。
PolarDB-X内存管理机制的设计,主要为了几类问题:
让用户更容易控制每个查询的内存限制;
预防内存使用不当,导致内存溢出进而引发OOM;
避免查询间由于内存争抢出现相互饿死现象;
避免AP Workload使用过多内存,严重拖慢TP Workload
业界解决方案
在计算层遇到的内存问题,业界其他产品也会遇到。这里我们先看下业界对此类问题是如何解决的。
PostgreSQL
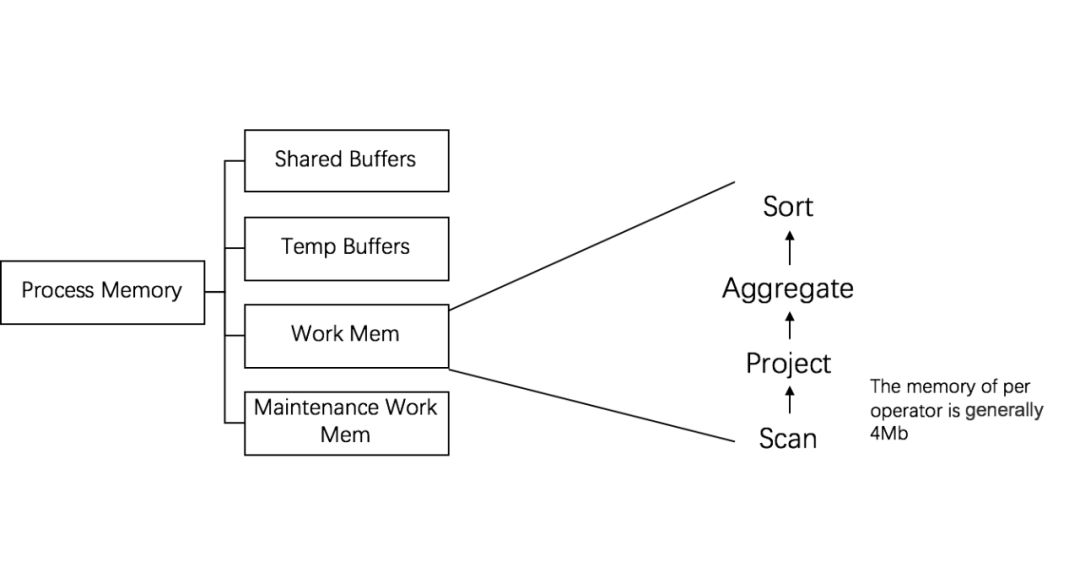
内存按照一定的比例,分为四大区域(Shared Buffers、Temp Buffers、Work Mem、Maintenance Work Mem);
在查询过程算子主要使用Work Mem区域内存,且每个算子都是预先分配固定内存的,但内存不够时,需要与硬盘进行swap;
Flink
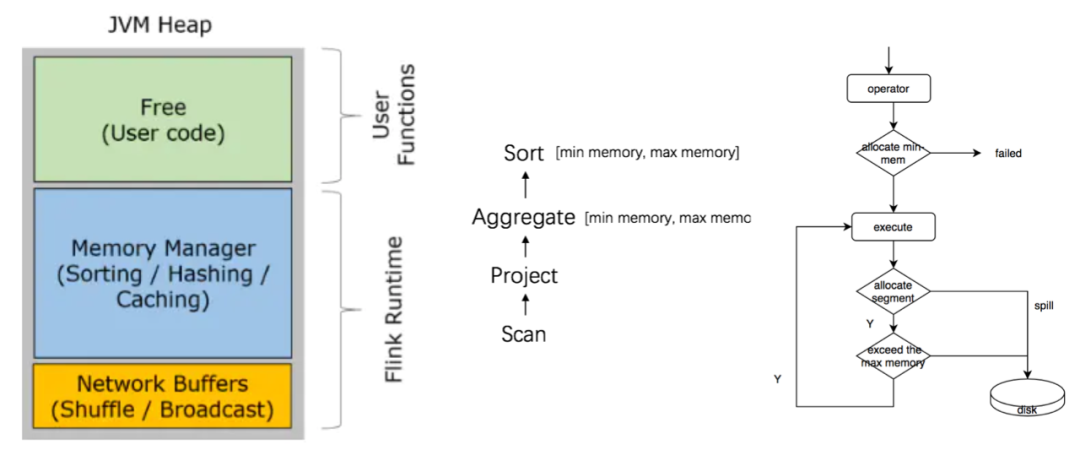
引入了一套基于字节流的数据结构,在JVM虚拟机上实现了类似C申请和释放内存的池化管理;
内存主要分为三块: 网络内存池、系统预留的内存池、计算内存池。
为每个算子设置一个[min-memory, max-meory] 调度上可以保证每个算子初始化的时候预先分配min memory,在计算过程中不断从计算内存池申请内存,当申请失败或者内存使用超过算子预先定义max memory的时候,主动触发数据落盘。
整个计算是动态的,其实是很难权衡哪个算子抢占权重高,如果任意放开,肯定会影响性能;
Flink是流水线计算模型,类似PartialAgg算子一定不落盘,所以一旦PartialAgg占用过多内存,导致下游没有内存可用,而PartialAgg又一定会往下游发送数据,这样必然会导致Dead Lock。
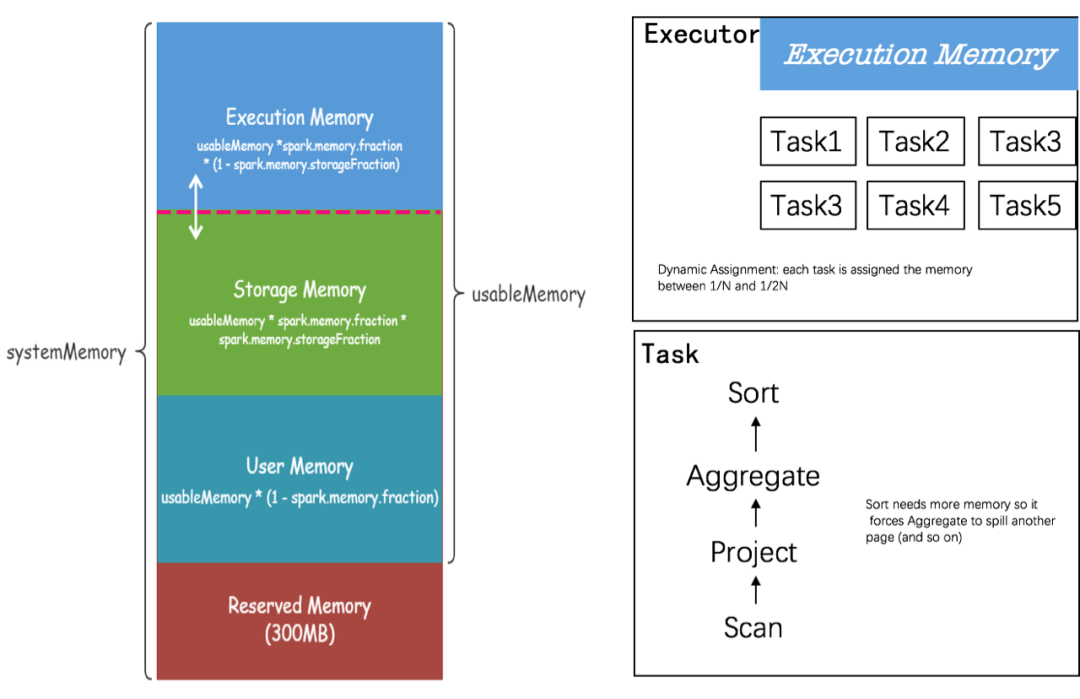
Spark
Presto
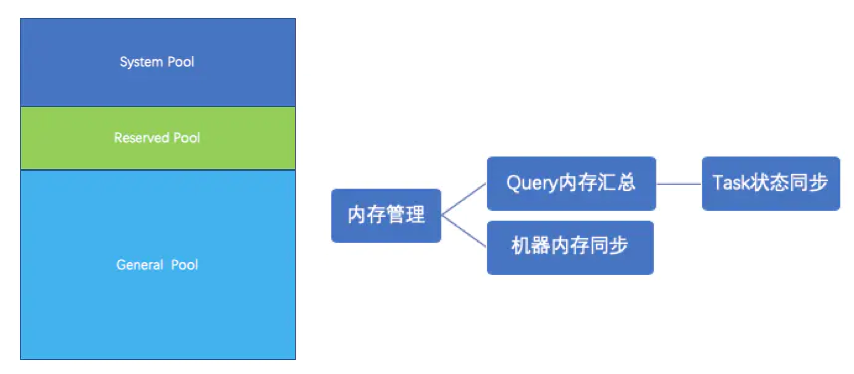
采用的是逻辑内存池,来管理不同类型的内存需求。
Presto整体将内存分为三块: System Pool、Reserved Pool、General Pool。
Presto内存申请其实是不预分配的,且抢占是完全随机的,理论上不设定Task抢占的上限,但为了出现某个大查询把内存耗尽的现象,所以后台会有定时轮训的机制,定时轮训和汇总Task使用内存,限制Query使用的最大内存;同时当内存不够用的时候,会对接下来提交的查询做限流,确保系统能够平稳运行。
PolarDB-X内存管理
统一的内存模型
结合HTAP特性,我们将内存池划分为:
System Memory Pool:系统预留的内存,主要用于分片元数据和数据结构、临时对象;
Cache Memory Pool:用于管理Plan Cache和其他LRU Cache的内存;
AP Memory Pool: 用于管理WorkLoad是AP的内存;
TP Memory Pool: 用于管理WorkLoad是TP的内存;
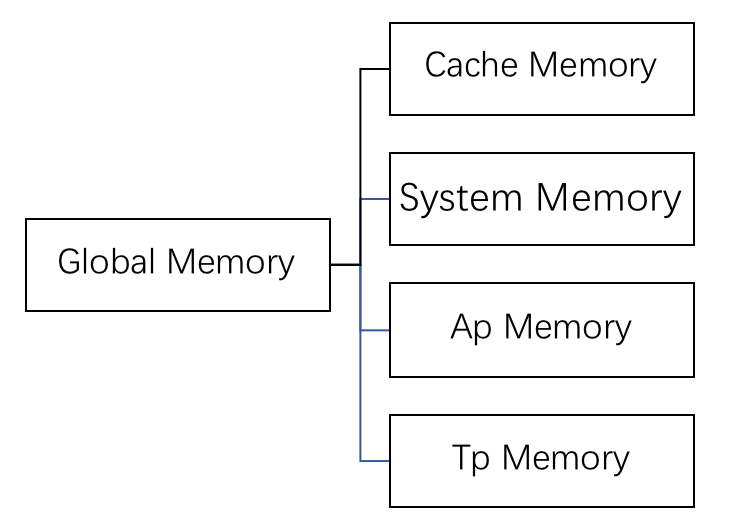
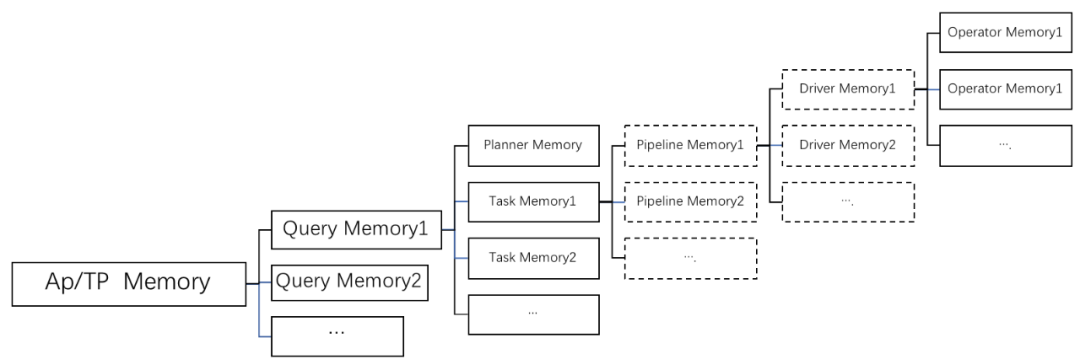
结合我们的计算层次结构,我们按照树形结构去管理内存:
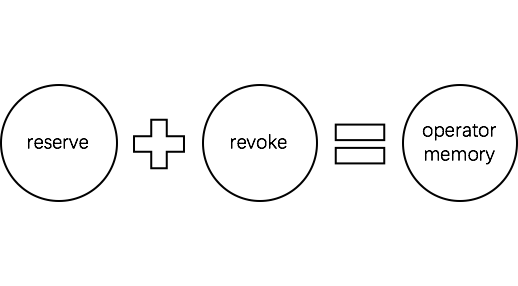
结合算子对内存申请和释放的行为,我们对一个Operator Memory划分为两个内存块: Reserve和Revoke。
内存对象
interface MemoryPool {//申请reserve 内存ListenableFuture<?> allocateReserveMemory(long size);//尝试着申请reserve 内存boolean tryAllocateReserveMemory(long size, ListenableFuture<?> allocFuture);//申请revoke 内存ListenableFuture<?> allocateRevocableMemory(long size);//释放reserve 内存void freeReserveMemory(long size);//释放revoke 内存void freeRevocableMemory(long size);}复制
动态抢占内存机制
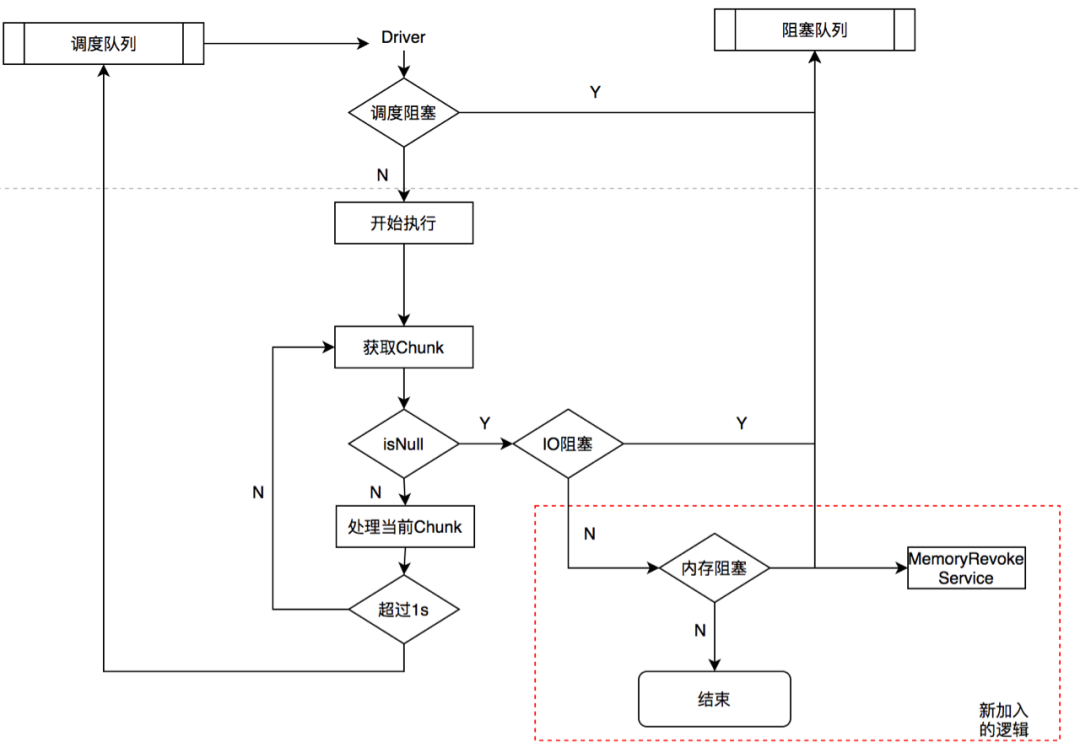
当内存池子(AP/TP Memory Pool)内存不足阈值的0.8之时,申请内存的算子会在下一刻会被暂停执行,等待被触发数据落盘,以到达释放内存的目的。
当前查询申请的总内存超过当前Max Query Memory阈值的0.8之后,申请的算子会被暂停执行等待被被触发数据落盘,以到达释放内存的目的。
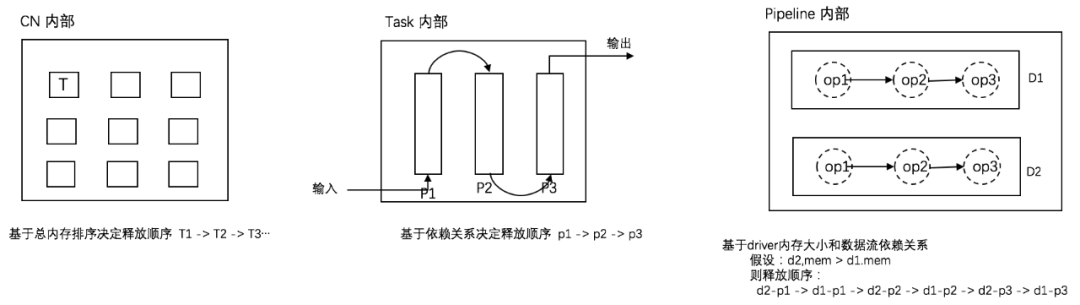
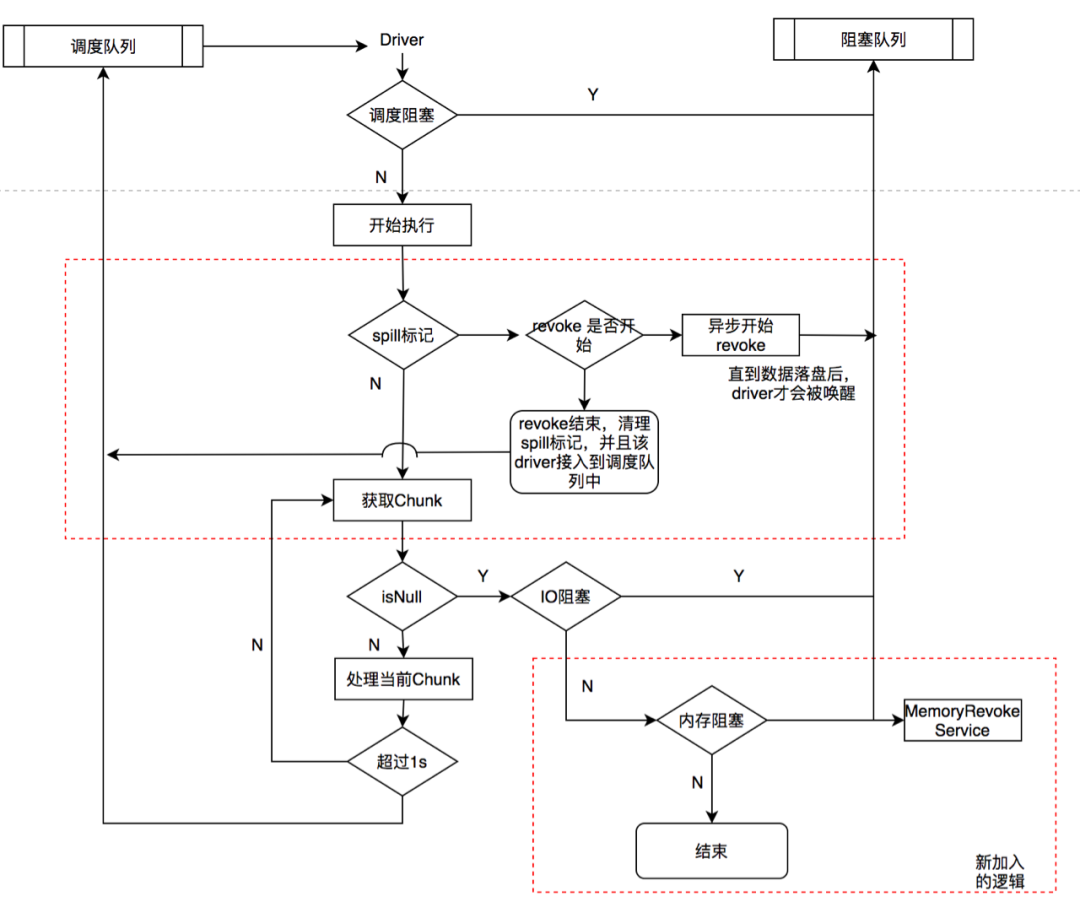
基于负载的内存隔离
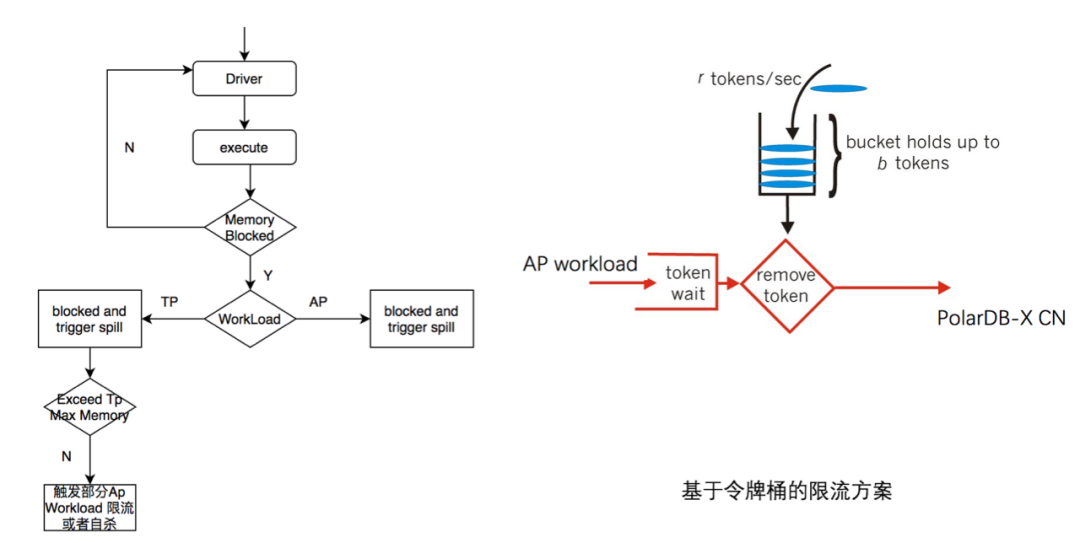
Driver 执行过程中,按需申请内存,如果内存足够,会反复被调度执行;
当Driver被内存阻塞时,判断其Workload;
如果是AP,则通过MemoryRevokeService服务触发数据落盘;如果是TP Workload,则在触发数据落盘的同时,会判断当前TP Memory是否超过TP Memory Pool,若不是,则说明AP Workload使用内存过多,则回调AP Workload做调整;
回调的方式有两种:触发部分AP Worload自杀,且触发Ap Worload 基于令牌桶的方式做滑动限流。
数据测试
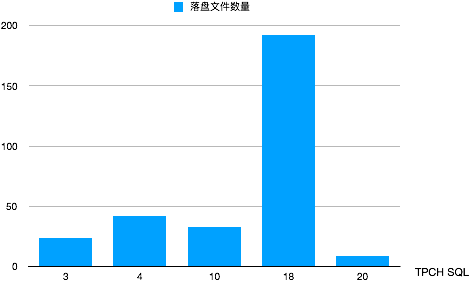
基于15MB的内存跑通1g TPCH,这里我们截取了几个比较耗内存的Query统计了落盘文件的数量。
测试了TPCC和TPCH混跑情况下,AP 对TP的影响。这部分测试也涵盖了CPU的资源隔离,后面我们会单独开一篇谈谈PolarDB-X基于负载的资源隔离技术。在不开启TPCH的情况下,tpmc保持在3.2w-3.4w之间; 再开启TPCH后,tpmc基本可以维持在3w以上,且有抖动10%左右。

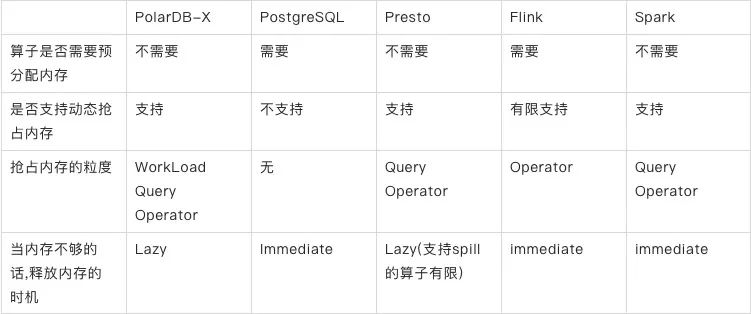
PolarDB-X算子不预分配内存,而是在计算过程中按需去申请内存,可以充分提高内存利用率;
支持Workload/Query/Operator维度的内存动态抢占,比较适合HTAP场景,可以通过设置不同维度的阈值,尽可能确保在内存上TP Workload不受AP的干扰;
相对于PostgreSQL/Flink/Spark来,PolarDB-X释放内存的时机是Lazy的。就是说当算子内存不够的时候,算子并不是立即落盘释放内存的,而是退出执行线程,由另外一个服务计算出更加耗内存的算子,这种方案可以挑选更加耗内存的查询或者算子做数据落盘,避免对小查询造成影响。但Lazy的方式存在一定的风险,可能在一瞬间内存未及时释放,而运行的查询申请内存过多,导致OOM,但好在PolarDB-X是计算存储分离的架构,计算层是无状态的;
PolarDB-X 相对于Presto 动态内存抢占的粒度更加细,将Workload也纳入考虑。但Presto在实现的细节上会考虑大查询间内存的相互影响。而在HTAP场景下,我们更加注重AP对TP的影响,AP内查询间并没有额外的机制去保证内存不受影响。
从业界产品来看,每个产品在内存管理上都有各自的特点,这和产品本身的定位是有一定关系。而PolarDB-X作为一款计算存储分离的HTAP数据库来说,其计算层目前采用的完全动态内存抢占方案,可以做到充分使用内存,避免AP对TP的影响。





