




起因
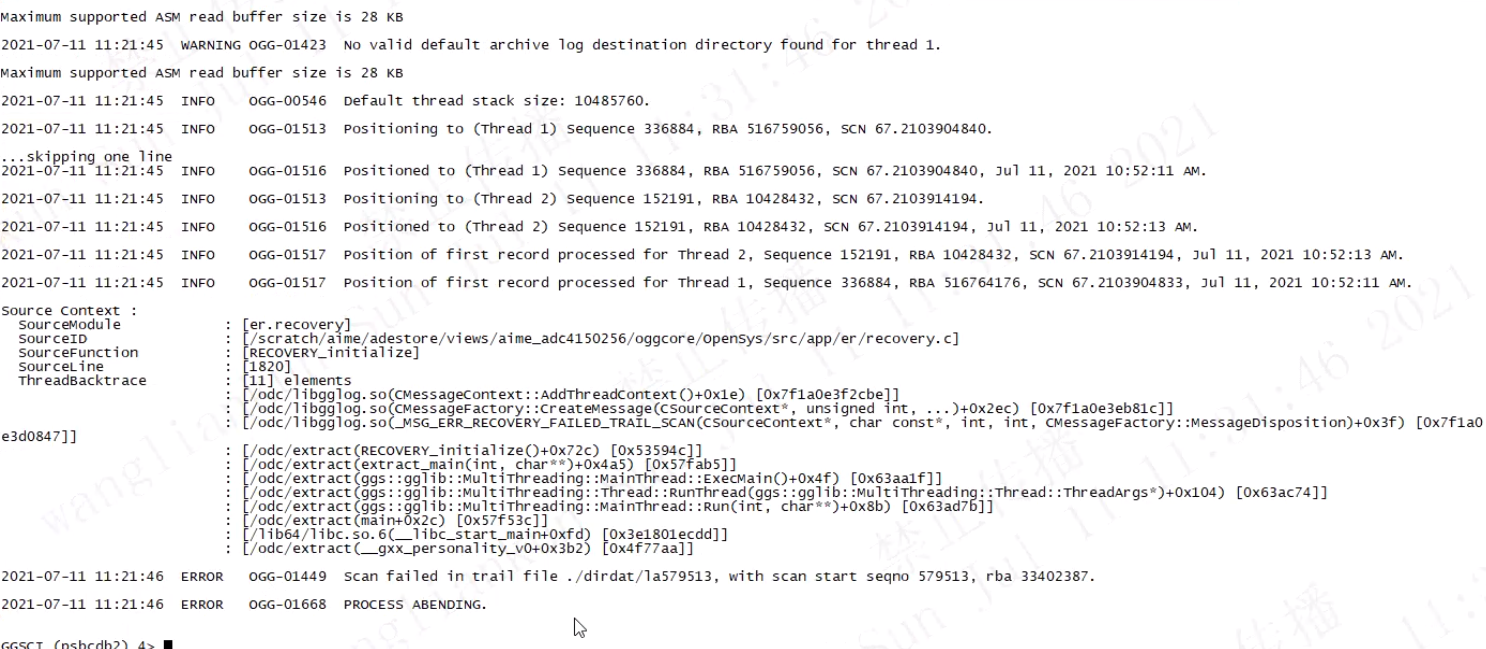
早晨值班人员给我打电话,说数据库宕机,我们这台机器有OGG同步,为源端。由于要快速恢复业务,尽量避免影响,但是OGG启动不起来,发现有OGG-01449的报错,该OGG是源端抽取进程。
这台数据库RAC集群节点一宕机时老问题了,打算替换掉,现在还没有替换掉。
注意4月14日也出现过,写了一篇文档
https://blog.51cto.com/blogger/publish/2706994
以下是处理步骤
源端出问题一般是数据块损坏的问题,该数据块损坏我们就暂时不深入研究了。直接上解决方法。
1. 检查目标端最后的tail文件,查找最后的scn传输到多少了。
1. cd /odc
2. ./ggsci
3. info repsp*
4. 查询到tail在哪里。我们这个路径为./dirdat/shenpi/ra591486
5. 再到dirdat/shenpi 排序看下,发现ra591485,ra591486 这两个是100来k,说明这两个文件并没有传输过来数据。我们只看数据比较大的。ra591484,这个是比较大,里面有数据。
6. 进行数据挖掘./logdump
7. open ./dirdat/shenpi/ra591484
8. ghdr on
9. ggstoken detail
10. pos last
11. n 后发现没有数据,进行反向查询
12. pos reverse
13. n 插线有数据了。
14. 我们记录下查询到的scn号码
15. scn号码为289866746258
16. 查询到已经同步到的时间为2021/07/11 10:52:17.087.348
到此目标端查询完毕。
11. 将目标端全部关闭 stop repsp*
2. 源端查询
对源端进行查询,然后进行操作,源端需要查询操作的步骤。
1. cd /odc
2. ./ggsci
3. info *
4. 停掉源端抽取投递进程
5. 查询到的保存下。
6. 抽取端进行
alter extract ext_psb etrollover,让他产生一个新的文件。这个过程中打开另外一个窗口,查看下是否真的产生了新的文件。
7. 由于10点51出现问题,我们指定时间10点抽取,这样可以保证数据的完整性,当然你也可以指定10点51,但是这样可能少数据。这是两个节点,我们需要写两个如下:
alter extract ext_psb begin 2021-07-21 10:00:00 thread 1;
alter extract ext_psb begin 2021-07-21 10:00:00 thread 2;
8. 指定csn ,再目标端查询到的scn号。csn查询到要+1,否则会有重复数据。打开抽取进程。
start ext_psb atcsn 289866746259
9. 查看状态为stoped,我们再进行start ext_psb,现在状态为running了。
3. 传输端修改seqno,并启动
由于抽取段已经产生了新的tail文件,我们需要对其进行指定。extseqno 这个就是新的seqno号码。
alter extract dmp-psb,extseqno xxxxxx,extrba 0
指定完毕以后,start dmp-psb就是running状态了。
4. 目标端启动
1. cd /odc
2. ./ggsci
3. info all
4. start repsp*
至此一次OGG数据库故障就已经解决了。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
