




Couchbase成功上线后,就需要对其运行状态进行监控,准确定位性能瓶颈,及时优化。
本文作为《Couchbase生产部署最佳实践》的第三部分列举了需要重点关注的Couchbase和OS层面的监控指标,Couchbase Web Console本身提供了对集群、节点状态以及容量等的监控告警。如下图。
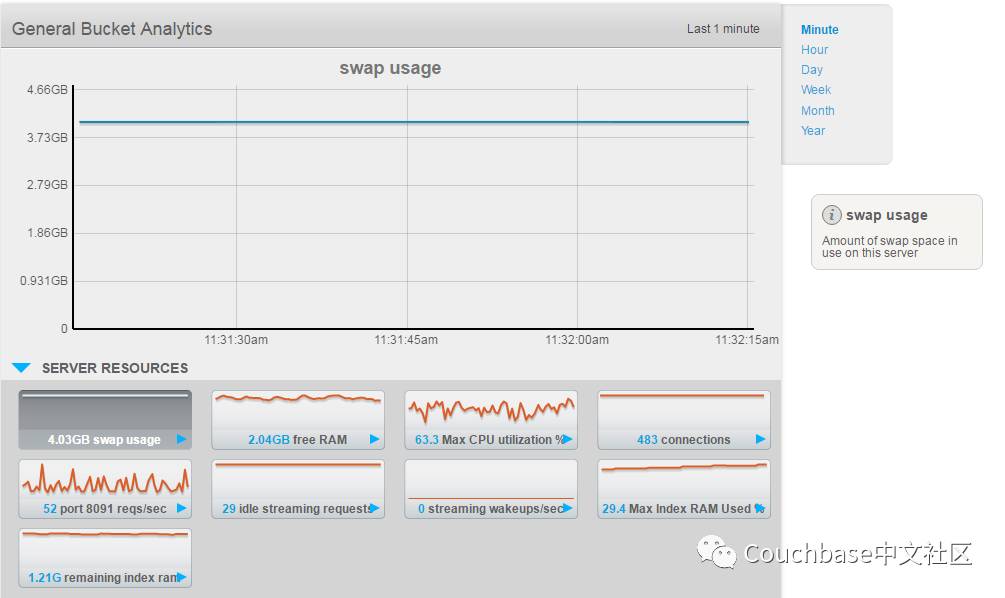
图一 General Bucket Analytics界面
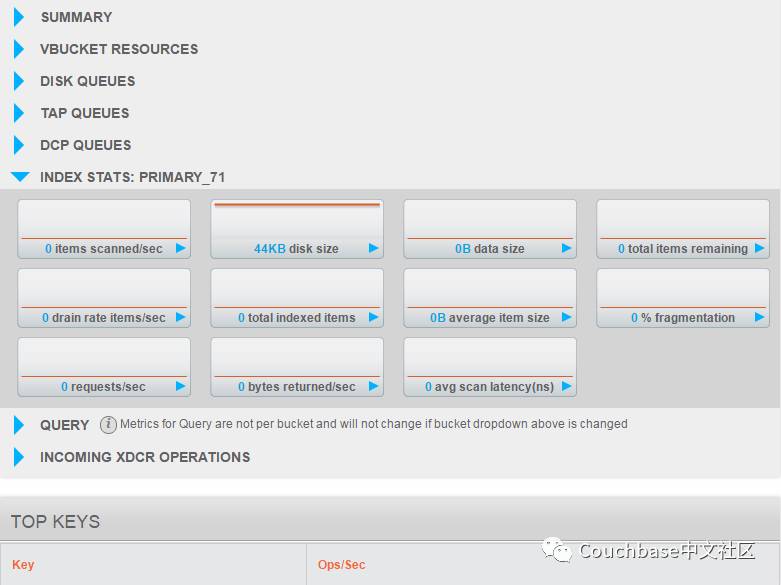
图二 GeneralBucket Analytics界面
大家也可以使用Couchbase提供的cbstats工具获取更细粒度的监控信息,进行二次加工丰富监控场景。
分类 | Couchbase 指标 | OS 指标 |
RAM | Items | Free RAM |
• curr_items | Swap Usage | |
Memory Used | Used File Descriptors | |
• mem_used | Memcached RAM Usage | |
High Watermark | Beam.smp RAM usage | |
• ep_mem_high_wat | ||
Cache Miss Ratio | ||
• ep_bg_fetched cmd_get | ||
Active Docs Resident Percentage | ||
• vb_active_perc_mem_resident | ||
• vb_replica_perc_mem_resident | ||
OOM Per Second | ||
• ep_tmp_oom_errors | ||
• ep_oom_errors | ||
• mem_used ep_kv_size | ||
磁盘IO | Disk Write Queue | IO Utilization (iostat) |
• ep_queue_size | ||
• ep_flusher_todo | ||
Disk Reads/Writes per Second | ||
• ep_io_num_read | ||
• ep_io_num_write | ||
磁盘空间 | Free Space | |
• Data Partition | ||
• Root Partition | ||
CPU | CPU Usage | |
• Overall | ||
• Memcached | ||
• Beam.smp | ||
网络 | Items within the DCP Queue | CLOSE_WAIT connection count |
• ep_dcp_total_queue | ||
数据分布 | Active and Replica vBucket Count | |
• vb_active_num | ||
• vb_replica_num | ||
运行进程状态 | beam.smp | |
memcached |
表一 Couchbase和OS监控指标
beam.smp进程负责监控管理底层服务进程如XDCR复制、集群操作、视图等。
memcached进程负责将项目(items)缓存到RAM中并持久化到磁盘上。
接下来再看看Couchbase内部哪些参数需要关注的。以及达到监控阈值后,我们应该如何响应。
Couchbase 指标 | 描述 | 响应 |
curr_items | 当前节点上活动项目数,在warmup期间该值一直为0。 | 先期确定好项目数的基线数量,一旦发现该值有明显变化就表明Couchbase有异常故障或者应用出现bug。 |
mem_used | 当前内存使用量,如果mem_used = ep_kv_size会得到OOM_ERROR。mem_used必须小于ep_mem_high_wat。ep_mem_high_wat是表示将数据驱逐到磁盘的内存使用量高水位线。 | 如果mem_used / ep_kv_size 或 mem_used / ep_mem_high_wat一直接近90%,表明需要给集群添加内存或者节点。 |
ep_bg_fetched | 从磁盘读取的项目数(缓存未命中)。 | 对于缓存应用场景,该值应该接近于0。对该指标建立基线值,如果变化率超过基线的100%就进行告警。 |
vb_active_perc_mem_resident | 常驻内存的vBucket活动数据百分比。 | 在缓存应用场景中,这个值应接近于100%,如果低于90%即告警。 |
vb_replica_perc_mem_resident | 常驻内存的vBucket副本数据百分比。 | 该值越高表明发生故障切换时的数据访问延时越低。请根据发生故障时的业务访问延时需求设定阈值。 |
ep_tmp_oom_errors | 发送给客户端的临时OOMs次数。表示系统内瞬时内存压力。 | 这个报错表明服务器达到ep_mem_high_wat后的临时内存压力,并且在驱逐最近不访问的数据。报错频繁表明需要扩展集群。 |
ep_oom_errors | 发送给客户端的稳定OOMs次数。表示系统内稳定的内存压力很高。 | 这个报错表明bucket已经超过总共分配的内存,需要立即添加内存或节点。 |
ep_queue_size | 等待写入磁盘的数据量。 | 取决于你的工作负载和可用的磁盘IO建立正常基线值,如果超过基线120%就告警。 |
ep_flusher_todo | 正在写入磁盘的项目数。 | 取决于你的工作负载和可用的磁盘IO建立正常基线值,如果超过基线120%就告警。 |
ep_io_num_read | 发送到磁盘的读操作数。 | 取决于你的工作负载和可用的磁盘IO建立正常基线值,如果超过基线120%就告警。 |
ep_io_num_write | 发送到磁盘的写操作数。 | 取决于你的工作负载和可用的磁盘IO建立正常基线值,如果超过基线120%就告警。 |
ep_dcp_total_queue | 当前所有DCP对列大小之和。表明等待复制的总字节数。 | 取决于你的工作负载和可用的磁盘IO建立正常基线值,如果超过基线120%就告警。 |
vb_replica_num | vBuckets的副本数。 | 如果该值低于(1024*副本数量)/节点数,表明需要做rebalance。 |
vb_active_num | 活动vBuckets数。 | 该值应一直等于1024/节点数,如果不等,表明有节点故障,需要进行failover和rebalance操作了。 |
表二 Couchbase监控指标详细解释
关于更详细的指标,请参考以下链接:
https://developer.couchbase.com/documentation/server/4.6/cli/cbstats-intro.html
我们可以使用`cbstats`命令获取上述表格中描述的各种指标项,例如:
#/opt/couchbase/bin/cbstats -b <bucket_name> -p<pass_word> localhost:11210 all | grep \ curr_items
curr_items: 36
#/opt/couchbase/bin/cbstats -b <bucket_name> -p<pass_word> localhost:11210 all | grep \ vb_active_perc_mem_resident:
vb_active_perc_mem_resident: 100
这里将<bucket_name>和<pass_word>换成你当前环境的bucket名和访问密码。
此外,我们还可以通过 /pools/default/buckets/bucket_name/stats 获取bucket的采样统计信息:
curl –X GET -u <username>:<passwd> http://<ip>:8091/pools/default/buckets/<bucket_name>/stats
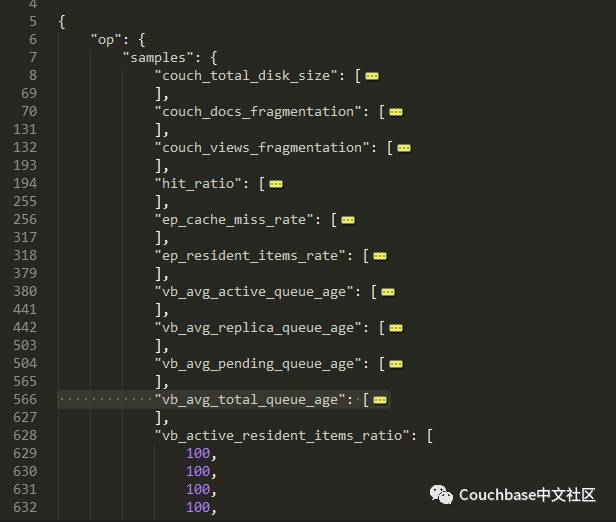 图三 Bucket统计信息
图三 Bucket统计信息
另外可以指定-d zoom={interval}参数指定采样时间,可选参数有minute,hour,day等。
curl –X GET -u <username>:<passwd>-d zoom=minute http://<ip>:8091/pools/default/buckets/<bucket_name>/stats
将<username>,<passwd>,<ip>,<bucket_name>根据自己环境的实际配置进行修改。
详细使用参考:
https://developer.couchbase.com/documentation/server/current/rest-api/rest-bucket-stats.html
