




数据库一致性和并发性详解
1数据的一致性和并发性概述
db2数据库通过事务和日志保证数据库的一致性(所谓数据库一致性,就是当崩溃恢复,或者前滚到某一个时间点时,该时间点所有已经提交的事务都会被写入磁盘,而所有未提交或者已经回滚的事务都被撤销)、通过锁和隔离级别保证数据库的并发性(所谓数据库并发性,就是当一个事务更新一条记录,另外一个事务不能更新相同的记录,只能等待),数据库的一致性和并发性,是程序开发和数据库维护过程中需要解决的重点、难点问题,为了有效解决数据库出现的一致性、并发性问题,就必须深入了解如下内容:
事务
日志
锁和隔离级别
2事务
本节内容如下:
事务的概念
设置事务非自动提交的方法
1、事务的概念
事务是由一条或多条SQL语句组成,所有语句构成一个工作单元(Unit Of Work,UOW),事务包含的SQL语句要么全部成功,要么全部失败,不允许一些语句成功,另一些语句失败。事务具有ACID4个特性:即原子性(Atomic)、一致性(Consistent)、隔离性(Isolation)、和持久性(durability)。
2、设置事务非自动提交的方法
(1)命令行处理程序(CLP)级:
A、实例级设置:db2set db2options=+c。
B、会话级设置:db2 update command options using c off,优先级高于实例级的设置。
C、语句级设置:db2 +c command or statement…,优先级高于实例级和会话级的设置。
例子一:实例级设置事务非自动提交
db2set DB2OPTIONS=+c
db2stop force
db2start
db2 connect to sample
db2pd -d sample –locks
db2 "insert into t1 values(1,'aa')"
db2pd -d sample –locks
返回加锁信息,表明插入语句还没有被提交
db2 commit
#清除实例级事务非自动提交
db2set DB2OPTIONS=
db2stop force
db2start
例子二:会话级设置事务非自动提交
db2 update command options using c off(注意:command options只在同一个进程起作用,如果用db2 update …,接着db2 “select …”,这是两个进程,command options的设置不起作用)
创建文件c.sql,内容为:
update command options using coff;
select * from t1 for update with rs;
然后执行db2 connect to sample
db2 -tvf c.sql
使用db2pd -d sample -locks能看到锁没有释放,说明事务没有提交。
db2 commit
例子三:语句级设置事务非自动提交(常用)
执行
db2 connect to sample
db2 +c "select * from t1 for update with rs"
再打开另一个db2cmd窗口,执行db2pd -d sample -locks能看到锁没有释放,说明事务没有提交。
db2 commit
(2)应用程序级:
对于JAVA数据库连接(Java Database Connectivity,JDBC),事务是否自动提交是在应用程序运行时通过调用db2的Connection接口中的setAutoCommit(false)方法设置的。
3日志
每个事务中包含的SQL语句执行信息,以及事务是否成功提交或回滚的信息,都将写到日志文件中。DB2通过对日志进行Redo和Undo来保证数据库的一致性。本节内容如下:
日志类型
日志参数
日志监控和演示
1、日志类型
DB2数据库中有两类日志:循环日志和归档日志。
(1)、循环日志(circular logging)
循环日志是以循环的方式使用日志,当一个日志文件中包含的所有事务都已经提交或回滚,并且变化的数据已经从缓冲池写到数据磁盘,这个日志文件才可以被重用
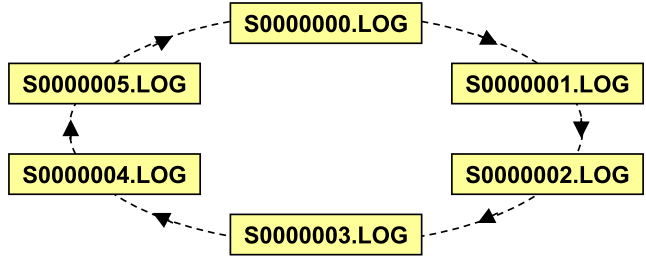
(2)、归档日志(archival logging)
归档日志是将所有日志保留,而不会重用。只要日志文件满,就可以归档(不管日志文件中包含的事务是否已经commit和数据库缓冲池中该日志对应的脏页是否写到磁盘),但不意味着日志就是非活动的。归档日志模式下,日志从活动变成非活动,需要日志文件中包含的所有事务都已经提交或回滚,并且变化的数据已经从数据库缓冲池写到磁盘。

(3)、无限日志记录
DB2会在一个日志被填满时立即归档这个日志,这样可以保证活动日志目录永远不会被填满。归档的日志都复制到归档目录。
要启用无限日志记录
(1)启用归档日志记录
(2)将LOGSECOND数据库配置参数设置为-1
不建议使用无限日志记录,因为它需要从归档站点检索活动日志,这样会延迟紧急事故恢复的时间。
一个数据库的日志记录的类型是由数据库参数LOGARCHMETH1决定的。当LOGARCHMETH1为OFF(默认值)时,归档日志记录被禁用,循环日志记录被启用。
归档日志方式不是默认的日志工作方式,但它是允许用户执行前滚(roll forward)恢复的唯一方法。
可以通过update db cfg 命令来更改这些参数,例如如果启用归档日志,可以执行:
db2 update db cfg for bitsdb using LOGARCHMETH1 DISK:/home/dbarchiveLog/
在第一次启用归档日志时,需要给数据库做一个离线全备份。
对于交易型系统,建议采用归档日志。尽管运维相对复杂,但能够确保当出现问题需要恢复的时候,可以利用日志进行数据前滚,避免数据丢失。
2、日志参数
2.1. logbufsz
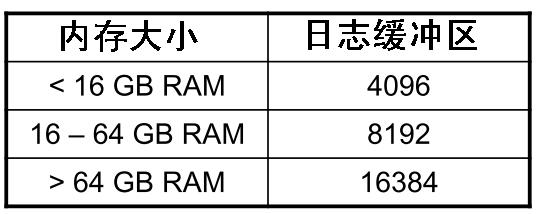
定义:为了提高性能,每一次日志的写入都是先写到日志缓冲区,再通过一定的机制写到日志文件。LOGBUFSZ参数指定将日志记录写到磁盘之前的缓冲区的大小。
默认值:64 位 256 [4 - 131070 ][16k-512M]
是否可以联机配置:否
设置指引:建议的日志缓冲区大小为
当下列事件之一发生时会将日志记录写到磁盘:
(1)交易提交。
(2)日志缓冲区满。
(3)当mincommit被设置为非1时,每秒钟刷新一次。V10.1已删除该参数
(4)其余的一些DB2内部事件,比如在线备份。
第(3)种情况,设置mincommit为非1的值,执行commit的时候如果没有达到mincommit指定的次数,commit将会被挂起,直到到达mincommit次数、过了1秒或日志缓冲池满,日志缓冲池中的数据才会被写入日志文件。如果在这之间数据库崩溃,那这些挂起commit的事务因为没有任何信息记录入物理日志文件,所以这些事务就像没有存在一样将被忽略(这是一个BUG,所以在V10.1的时候,mincommit参数不再存在)。
第(4)种情况,主要是一些DB2内部事件需要明确地将日志缓冲区刷入磁盘,确保没有任何未写入磁盘的日志,保证数据库的一致性。比如online backup include logs时,在备份结束时,DB2会刷新日志缓冲池并把所有活动日志归档。
2.2. Logfilsiz
默认值:1000[4-1048572][16k-4G]
是否可以联机配置:否
建议值:100M
2.3.Logprimary
默认值:3[2-256]
是否可以联机配置:否
建议值:30
在10.1版本中,活动日志大小为(LOGPRIMARY+LOGSECOND)*LOGFILSIZ,其中日志个数的值必须小于或等于256,logfilsiz的最大为1048572,即4G,所以活动日志最大已经可以达到1024G。主日志在第一个连接到达数据库或者数据库被激活后立即分配,而辅助日志在主日志大小不够的时候动态分配。
2.4.Logsecond
默认值:2[-1;0-254]
是否可以联机配置:是
建议值:170
3、日志相关问题演示
3.1. 日志空间使用监控
db2 get snapshot for db on bitsdb|grep -i log

Log space available to the database (Bytes):数据库剩余的日志大小
Log space used by the database (Bytes):数据库已经使用的日志大小
Maximum secondary log space used (Bytes):历史上使用的最大辅助日志大小
Maximum total log space used (Bytes):历史上使用的最大日志大小
Secondary logs allocated currently:当前分配的辅助日志个数
3.2. 事务日志满的处理
(1)、事务太大。
解决方案:
1、长事务改成短事务
2、一次删除几百万条数据,改成每次删除1万条数据
db2 “delete from (select 1 from (select ROW_NUMBER() OVER() as rownumber from test) where rownumber<100)
3、修改数据库的日志配置,增大日志大小
4、不记日志的方式执行一个事务:activate not logged initially
5、删除表中所有数据时,用LOAD的方式:load from dev/null of del replace into tabname nonrecoverable,注意添加nonrecoverable,否则表空间处于备份挂起状态,不建议使用此方法。
6、truncate table tabname immediate。不记日志,直接清空回收数据页。
7、alter table tabname activate not logged initially with empty table,与truncate效果一样。
8、db2 "import from dev/null of del replace into test"。经测试,该清表操作不需要记录日志,能回收表占用空间,前滚恢复后表仍然可用。综上,清空表的最好方式为import relace。
(2)、操作数据量很小,但仍然出现事务日志满
A应用程序插入一行记录,但不提交;B应用程序每次插入10000条记录并提交,循环这种操作,会发现数据库报日志满的错误。
原因:A应用程序插入记录后,不提交,导致从这之后的日志文件都是活动日志,当B应用程序持续插入记录并提交,这种操作会产生大量的日志,这些日志使用完了剩下的主日志和辅助日志,当继续插入记录时,就会报日志满的错误。
演示:打开两个CLP窗口,第一个窗口以打开事务的方式插入一行记录到表T1 ,第二个窗口每次插入10000条记录并提交,如下:
第一个窗口:
db2 "create table t1(id int,name char(10))"
db2 +c “insert into t1 values (1,’aaa’)”

第二个窗口:
db2 "begin atomic declare i int default 0;
while(i<10000) do insert into t1 values(i,'name'||char(i));
set i=i+1;
end while;
end"
继续这种插入记录并提交的动作,直到报事务日志满的错误,如下:

此时通过db2 get snapshot for db on bitsdb|grep -i log获取当前数据库快照中的日志信息:
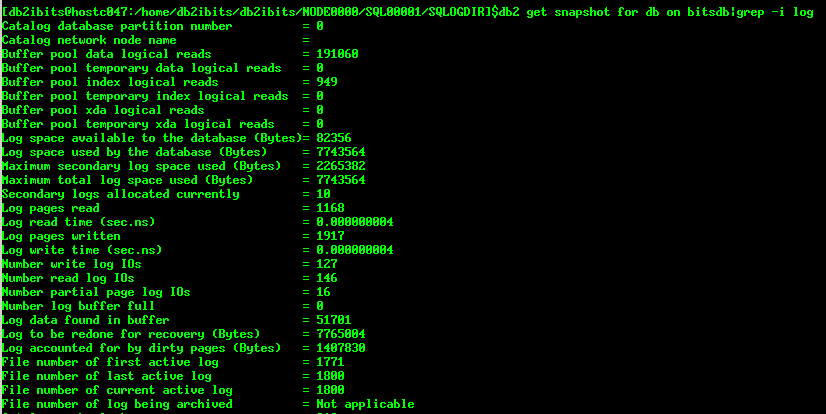
发现:
File number of first active log = 1771
File number of last active log = 1800
File number of current active log = 1800
接着通过db2 get db cfg|grep -i log获取数据库关于日志的配置信息,如下:
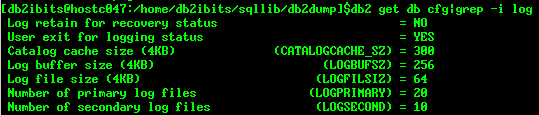
发现主日志个数为10,辅助日志个数为20,这样,最大可使用的日志大小为30个。通过数据库快照中关于日志的信息,知道日志文件已经使用完了30个(1800-1771+1=30),这样继续操作就会报日志满的错误。
上述现象说明,最久的未提交的事务也会造成事务日志满的报错。
要解决该问题,需要找出最久的未提交的事务所属的应用程序,进行commit或rollback操作,如果通过外界干预,可以强制force该应用程序。
通过获取数据库快照中的如下信息可以找到最久未提交事务的应用。

接下来,就可以通过commit、rollback、db2 “force application (2774)”来提交或回滚2774应用程序的事务。
4隔离级别和锁
本节内容如下:
隔离级别
锁的属性、模式和兼容性
锁转换、锁升级、锁等待、锁超时和死锁
锁监控工具
1、隔离级别
在说隔离级别之前,先说说数据库并发时容易出现的三种现象:
脏读:A事务更改了某张表的一条记录,B事务去读这条未提交的记录,随后A事务被回滚了,那么B读到的值就是错的
不可重复读:A事务根据某个过滤条件查询某张表,返回一个结果集。这时B事务更改了这个结果集的某些行,A事务再去读时会发现满足条件的结果集变小了
幻影读:A事务根据某个过滤条件查询某张表,返回一个结果集。这时B事务更改了这个结果集之外的某些行,而更改的这些行正好满足A的查询条件,这时A再去查询时会发现结果集变大了
通过锁和隔离级别,数据库并发时的三种现象能够得到解决,先看隔离级别,DB2的隔离级别分以下4种。
UR(Uncommitted Read):未提交读隔离级别,即读的时候不加锁,可以读到未提交的数据。
CS(Cursor Stability):游标稳定性隔离级别,即读到哪一行就在这一行加NS锁,读完就释放,类似游标一样。CS是默认的隔离级别。可以防止脏读。
RS(Read Stability):读稳定性隔离级别,即把查询的结果都加NS锁。可以防止脏读、不可重复读。
RR(Repeatable Stability):可重复读隔离级别,即把扫描过的行都加S锁。可以防止脏读、不可重复读、幻像读的情况。
可以看出,隔离级别的作用是在查询的时候用来通知DB2管理器,决定不加锁、加一行锁、在结果集上加锁还是把扫描过的行都加锁。
通过锁和隔离级别,数据库并发时的三种现象解决的方式如下:
对于脏读,当A事务更改这个表的记录时,DB2会在对应行上加排他锁,当B事务读取该行时,要申请读锁,在默认的隔离级别下,读锁和写锁是不兼容的,因此不会出现B读到未提交数据的问题
对于不可重复读:通过RS隔离级别,A事务对结果集的每一行记录加NS锁,B事务不能更新该结果集的任意一行,A事务再次执行该SELECT语句,返回的结果可能变多,但第一次选择得到的记录不会受任何影响。
对于幻像读:通过RR隔离级别,A事务对扫描到的每一行记录加S锁,B事务不能插入、更新、删除符合A事务条件的记录,A事务再次执行该SELECT语句,返回的结果不变。
总结,下表按不期望的结果概述了几个不同的隔离级别
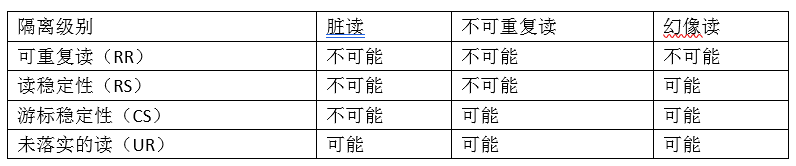
选择隔离级别的准则:
隔离级别越高,锁的粒度就越大,并发性就越低,因此,在目前的大多数系统中,都选择默认的隔离级别,即CS。
注意:隔离级别只适用于读,在查询的时候用来通知DB2管理器,决定不加锁、加一行锁、在结果集上加锁还是把扫描过的行都加锁。对于增、删、改操作,不管采用什么隔离级别,都要加写锁。
ORACLE的隔离级别:
已提交读模式:SET TRANSACTION ISOLATION LEVEL=READ COMMITTED;
串行模式:SET TRANSACTION ISOLATION LEVEL= SERIALIZABLE;
只读模式:SET TRANSACTION= READ ONLY; 不可以执行INSERT,UPDATE和DELETE操作
案例一:BITS系统数据库隔离级别为什么是RS?
针对DB2数据库编写的应用程序,数据库的隔离级别建议设置为CS,这样可以降低锁的个数,提高并发性。
对于BITS系统,通过xml配置文件已经声明事务管理的隔离级别为CS,但为什么BITS系统执行的SQL通过db2pd –d bitsdb –dyn查看的时候,都是运行在RS隔离级别呢?这给我们带来了不少DB2锁的问题。这是因为BITS应用部署在WAS上,WebSphere 6及之前的版本中数据库隔离级别默认为RS。
1 (READ UNCOMMITTED), 2 (READ COMMITTED), 4 (REPEATABLE READ), 8 (SERIALIZABLE)。
修改WAS中数据库隔离级别的方法如下:
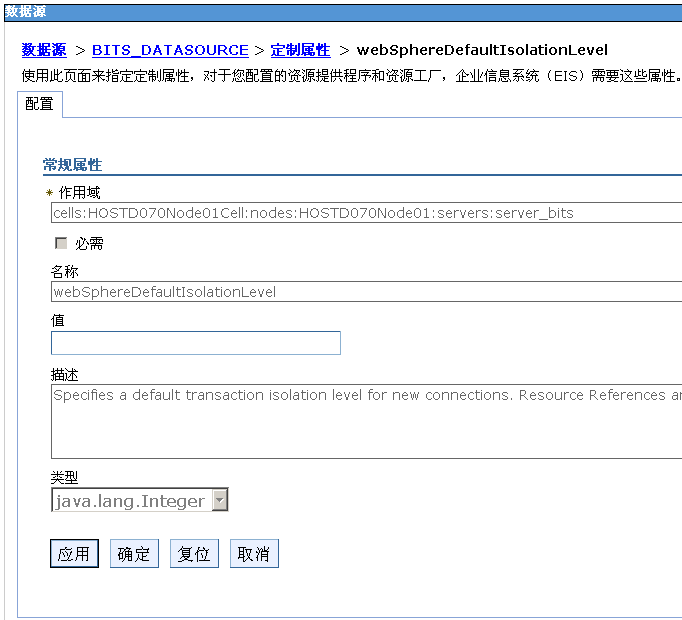
登陆WAS控制台进入:资源>JDBC>数据源> BITS_DATASOURCE>定制属性页面,设置数据库隔离级别webSphereDefaultIsolationLevel参数的值为2。
如下图:
案例二:需要提高隔离级别的特定场景
待办队列同时被多个柜员操作,需要保证只被一个柜员签出,其他签出操作都提示:”任务已经签出”
业务在待办队列被柜员签出的时候,在执行工作流代码前,插入如下代码:
“Select lockflag from wf_processlock where mpid=’16736NAGL001B6F30C132378477014EE’ for update with rs”
If(lockflag==’1’){
System.out.println(“任务已经签出”);
Conn.rollback();
Return;
}else{
“update wf_processlock set lockflag=’1’ where mpid=’ 16736NAGL001B6F30C132378477014EE’”;
Conn.commit();
//做后续的签出任务操作
}
隔离级别的设置方法:
可以在会话级,也可以在连接级,还可以在语句级,具体如下所示:
设置隔离级别的方法:
命令行处理程序(CLP)级:
隔离级别的会话级设置:db2 change isolation to cs
隔离级别的连接级设置:db2 set current isolation to cs
隔离级别的语句级设置:db2 select * from acctday with cs
设置完后,要查看当前隔离级别:
db2 values current isolation
或
Select current isolation from sysibm.sysdummy1
查询后的结果为数字,数字代表的意义如下:
1:UR
2:CS
4:RS
8:RR
应用程序级:
对于JAVA数据库连接(Java Database Connectivity,JDBC),隔离级别是在应用程序运行时通过调用connection接口中的setTransactionIsolation(conn.TRANSACTION_REPEATABLE_READ)方法设置的。
TRANSACTION_READ_UNCOMMITTED=1
TRANSACTION_READ_COMMITTED=2
TRANSACTION_REPEATABLE_READ=4
TRANSACTION_SERIALIZABLE=8
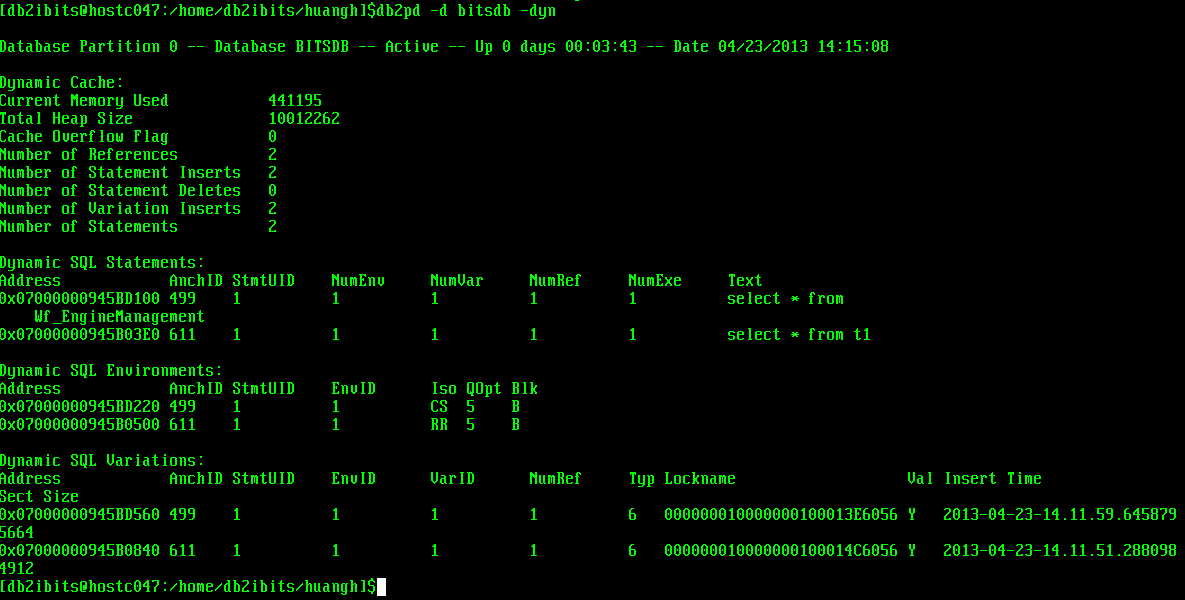
演示:通过db2pd查看SQL语句执行在哪个隔离级别
打开一个CLP窗口
执行db2 change isolation to rr
db2 connect to bitsdb
db2 +c “select * from t1”
然后通过db2pd –d bitsdb –dyn获取该SQL语句的隔离级别,结果如下:
2、锁的属性、模式和兼容性
2.1. 锁的属性
所有的锁都具有下列基本属性
Object:标识要锁定的数据资源。DB2数据库管理程序在需要时锁定数据资源。DB2支持对表空间、表、行和数据页加锁来保证数据库的并发完整性。在考虑用户应用程序的并发性的问题上,分析的焦点在表锁和行锁。
Size:对于DB2 64位平台,对象上第一个锁的大小为112字节,第二个锁的大小为56字节;对于DB2 32位平台,对象上第一个锁的大小为64字节第二个锁大小为32字节。
Duration:指定持有锁的时间长度。隔离级别通常控制着锁的持续时间。
Mode:指定允许锁的拥有者执行的访问类型。
2.2 表锁模式
表锁模式分两类:强类型表锁和弱类型表锁,强类型表锁适用于表里的所有行,主要包括S、U、X和Z锁四种;弱类型表锁又叫意向锁(intent),它的目的是配合行锁,在获得行锁之前必须先获得表锁,主要包括:IN、IS、IX和SIX。
默认情况下,DB2不会实施强类型表锁,只有通过lock table锁表或发生锁升级的时候才会在表上加强类型锁模式。
下表是DB2支持的表锁模式及其说明,将通过几个演示模拟强类型表锁。弱类型表锁,将在行锁模式中演示。
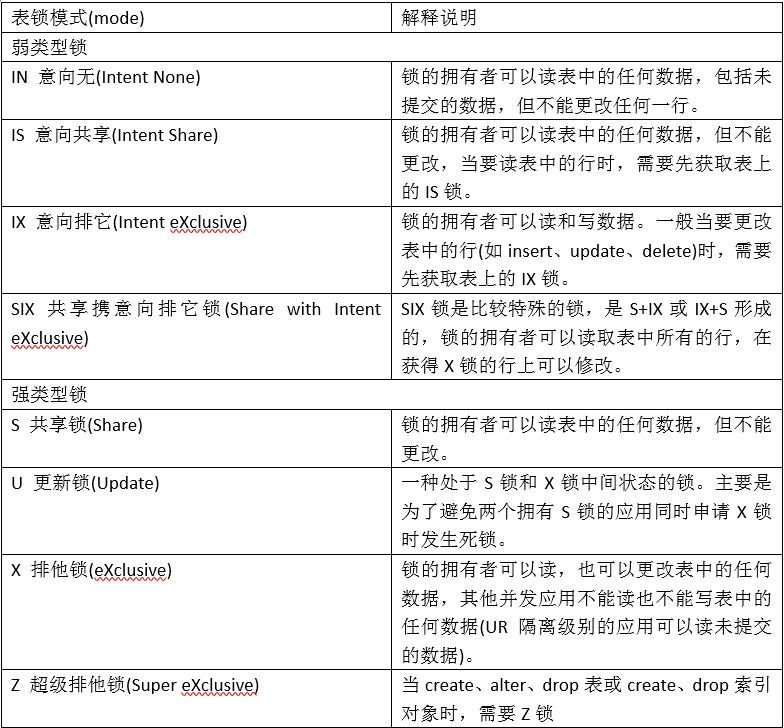
演示表的强类型锁:S、U、X、Z
例子1:S锁、U锁模式的模拟
db2 +c "select * from t1 with rr"
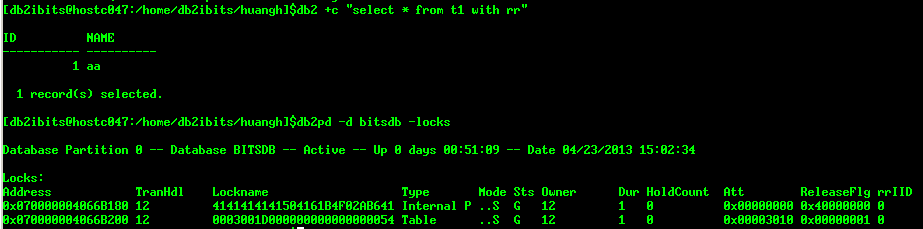
db2 +c "select * from t1 with rr for update"
例子2:X锁模拟
db2 +c "lock table t1 in exclusive mode"

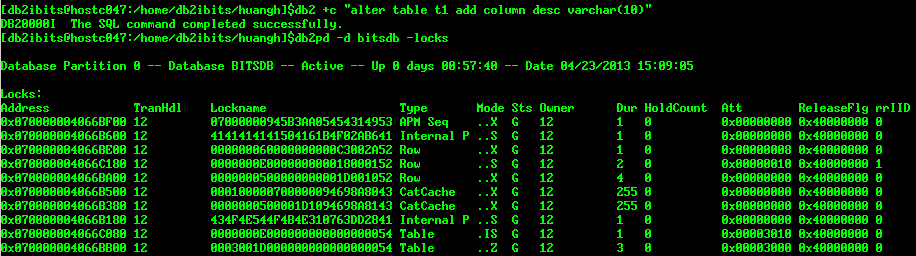
例子3:表的超级排他锁(Z锁)模拟
db2 +c "alter table t1 add column desc varchar(10)"
例子4:演示IN(意向无)
db2 +c "declare c1 cursor for select empno from employee where empno='000010' with ur"
db2 +c "open c1"

例子5:表SIX锁的模拟
db2 +c "lock table t1 in share mode"

db2 +c "insert into t1 values (2,'ee')"

2.3.行锁模式
在获得行锁前,必须先获得表锁。
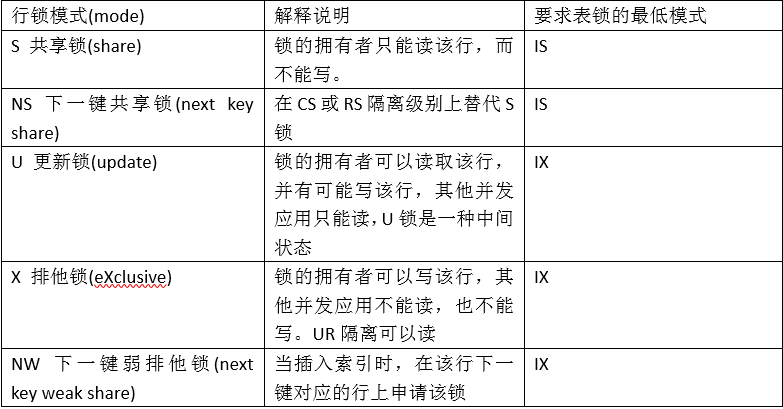
演示行锁模式
例子1:NS行锁、U行锁、X行锁模式模拟
db2 +c "select * from t1 where id=1 with rs"

db2 +c "select * from t1 where id=1 for update with rs"

这时继续在该窗口update刚刚获取的数据,发现U锁转换成了X锁
db2 +c "update t1 set name='aa' where id=1"

2.4.表锁和行锁兼容性
锁的兼容性,就是指两个或多个事务是否可以同时获取锁,如果可以,则表示兼容;如果不可以,则表示不兼容,其中一个事务只能等待锁释放。

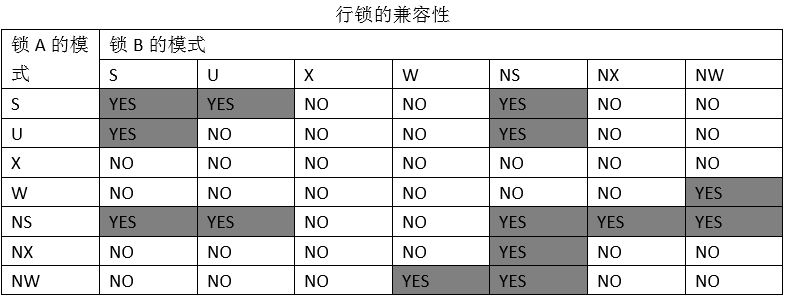
举例:
表锁的兼容:A事务在T1表中插入一行数据,B事务在T1插入另一行数据,那么,A,B两个事务在T1表锁是否兼容?插入数据时,A事务在表上需要获取IX,B事务也需要IX锁,通过表4.1可知,IX与IX锁是兼容的。这就说明数据库支持多个应用同时对一张表进行数据增、删、改,只要操作的不是同一行即可。
行锁的兼容:假设在默认的隔离级别下,A事务更新一行数据,B事务读取该行数据,两者是否兼容?更新数据需要在行上获取X锁,读取数据需要获取NS锁,通过表4.2可知,X锁与NS是不兼容的。在这种情况下,B事务只能等待A事务释放X锁才能继续处理,否则只能等待。
3、 锁转换、锁升级、锁等待、锁超时和死锁
3.1.锁转换
更改已挂起的锁定方式称为转换。当一个进程访问它已挂起锁定的数据对象,且访问方式需要比已挂起的锁定更严格时,数据库管理器将该对象上现有的锁模式与被请求的锁模式进行比较,如果需要的锁模式更高,将进行锁转换。一个进程在任一时间对数据对象只能挂起一个锁定。在一个事务中,当一个对象需要不同的加锁模式时,对该对象上加上更高模式的锁,否则将保持现有的锁模式。锁模式由低到高按照以下顺序排列:
表锁:IN->IS->S->IX->U->X->Z
行锁:S->U->X
在表锁定转换这一点上,IX(意向互斥)和S(共享)是特殊情况。S和IX锁定的严格程度相当,所以如果挂起了一个而请求另一个,那么结果转换为SIX(共享携意向排它锁)锁定。
锁转换例子:
在RS隔离级别下,如果一行被读取,那么该行的锁定为NS,包含该行的表具有意向共享锁定,如果随后更改了该行,那么表锁定将转换为IX,而行锁定转换为X。锁定转换同时发生在行和表上,发生了双重转换。
表db2obits.acctday的表结构如下:
CREATE TABLE "DB2OBITS"."ACCTDAY"
(
"ACCT_DAY" DATE NOT NULL ,
"IS_CURRENT" VARCHAR(1) ,
"PRE_ACCT_DAY" DATE ,
"COUNTRY_NUM_CODE" VARCHAR(6) NOT NULL
) ;
ALTER TABLE "DB2OBITS"."ACCTDAY"
ADD PRIMARY KEY
("COUNTRY_NUM_CODE");
第一个CLP窗口,执行读取一行的动作,并显示加锁情况,如下:


在同一个CLP窗口,更新该行,并显示加锁情况,如下:


可以看出,行和表上的锁,由NS和IS转换成了X和IX,这种现象称为双重转换。
3.2.锁升级
数据库管理器自动将锁定从行级别升级为表级别,以释放内存资源,称为锁升级(lock escation)。锁升级由数据库管理器自动完成,数据库的配置参数锁列表页面数(LOCKLIST)和应用程序占有百分比(MAXLOCK)直接影响锁升级的处理。
锁升级问题可以通过增加LOCKLIST和MAXLOCKS数据库参数的大小来解决。
每个数据库都有一个锁列表,该列表包含所有同时连接到数据库的应用程序所持有的锁。在32位平台上,一个对象上的第一个锁要求占64字节,而其他的锁要求占32字节。在64位平台上,第一个锁要求占112字节,而其他锁要求占56字节。
锁升级会在以下两种情况下被触发:
某个应用程序请求的锁所占用的内存空间超出了MAXLOCKS和LOCKLIST的乘积大小。这时,数据库管理器将试图通过为提出锁请求的应用程序申请表锁,并释放行锁来节省空间。以MAXLOCKS=1.3,LOCKLIST=1050来计算,应用程序请求的锁占用的内存空间如果为1.3*1050/100=13.65个4K页面,即13.65*4K=54.6K的话,将会发生针对该应用程序的锁升级
在一个数据库中已被加上的全部锁所占的内存空间超出了LOCKLIST定义的大小。这时,数据库管理器也将试图通过为提出锁请求的应用程序申请表锁,并释放行锁来节省空间。数据库管理器通过查看应用程序的锁列表并查找行锁最多的表,来决定对哪些锁进行升级。
3.3. 锁等待
锁与事务关联在一起,在事务完成之前,会一直占有锁。当其他事务需要该锁时,如果申请的锁与现有的锁不兼容,就只能等待,直到其他事务释放锁,这种现象叫做锁等待(lock wait)
例子:锁等待模拟
第一个CLP窗口
db2 "create table t1(id int,name char(10))"
db2 "insert into t1 values (5,'fff')"
db2 +c "update t1 set name='ggg' where id=5"
db2 +c "select * from t1 where id=5"
第二个CLP窗口
db2 +c "update t1 set name='hhh' where id=5"
3.4. 锁超时
继续上面的例子,如果事务等待超过了locktimeout数据库参数设置的值,该事务将会发生回滚,同时报911错误,Reason Code=68
例子:锁超时模拟
第一个CLP窗口
db2 "create table t1(id int,name char(10))"
db2 "insert into t1 values (5,'fff')"
db2 +c "update t1 set name='ggg' where id=5"
db2 +c "select * from t1 where id=5"
第二个CLP窗口
db2 +c "update t1 set name='hhh' where id=5"
3.5. 死锁
在两个应用中,应用A在等待应用B,同时应用B也在等待应用A,这样两者互相等待,造成谁也不能动,这种现象称为死锁。死锁的发生,99%是由于应用程序逻辑设计的问题造成的。
例子:死锁模拟
在第一个CLP窗口中创建两张表:t1和t2,然后在t1和t2表中各插入一行数据:
db2 "create table t1(id int,name char(10))"
db2 "create table t2(id int,name char(10))"
db2 "insert into t1 values (4,'eee')"
db2 "insert into t2 values (4,'eee')"
在第一个CLP窗口中,更新t1表中一行数据:
db2 +c "update t1 set name='ggg' where id=4"
在第二个CLP窗口中,更新t2表中一行数据:
db2 +c "update t2 set name='ggg' where id=4"
然后,在两个窗口中分别执行对t1、t2表的查询。
在第一个窗口中访问T2表
db2 +c "select * from t2 where id=4 with rr"
在第二个窗口中访问T1表
db2 +c "select * from t1 where id=4 with rr"
当两个窗口命令都输入后,同时执行(或较短的切换时间),会发现其中一个事务由于死锁而回滚。
4 、锁监控工具
在DB2中对锁进行监控有很多工具:快照监控、事件监控和db2pd。
4.1.快照监控方式
数据库快照是分析锁问题的最佳起点,与锁相关的信息如下:
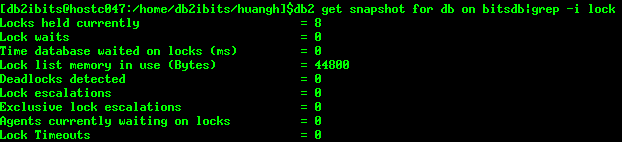
Locks held currently:数据库当前总的锁数量
Lock waits:数据库在开始第一个连接到现在发生锁等待的次数
Time database waited on locks (ms):数据库锁等待耗费的时间
Lock list memory in use (Bytes):使用的lock list大小。
Deadlocks detected:已经发生的死锁次数
Lock escalations:已经发生的锁升级次数
Exclusive lock escalations:已经发生的排他锁升级次数
Agents currently waiting on locks:正在发生锁等待的代理个数
Lock Timeouts:已经发生的锁超时次数
如果Lock list memory in use (Bytes)超过定义的LOCKLIST大小的50%,那么就增加LOCKLIST数据库配置参数中的4KB页的数量。
如果发生了Lock escalations>0或Exclusive lock escalations>0,则应该或者增大LOCKLIST或者MAXLOCKS,或同时增大两者。
4.2.事件监控方式
随着DB2版本的演变,锁监控工具变得越来越强大,但不可否认的是,针对锁等、锁超时和死锁都需要单独的工具来监控,这无形中增加了监控的复杂度和难度。为彻底改变这种情况,减少DBA的负担,DB2 V9.7版本引入了全新的锁事件监控器模型,使用统一的方法来捕获锁超时、锁等待和死锁,这就是CREATE EVENT MONITOR FOR LOCKING语句。
要使用CERATE EVENT MONITOR FOR LOCKING,需通过几个数据库参数来设置,以下是建议的值。
Lock timeout events (MON_LOCKTIMEOUT) = HIST_AND_VALUES
Deadlock events (MON_DEADLOCK) = HIST_AND_VALUES
Lock wait events (MON_LOCKWAIT) = NONE
Lock wait event threshold (MON_LW_THRESH) = 100000000
将Lock wait event threshold设置成100000000(100秒),即等待超过100秒时即开始捕获相关信息。
在更新完毕这些数据库配置参数后,会立刻生效。如果不想获取锁等待的信息,可以把MON_LOCKWAIT设置成NONE或MON_LW_THRESH的值大于锁超时的时间,建议在生产环境配置该监控时,把MON_LOCKWAIT设置成NONE。
参数设置完后,即可开始创建监控器进行锁事件的捕获:
db2 "create event monitor lockevmon for locking write to unformatted event table (table locks)"
db2 "set event monitor lockevmon state=1"
write to unformatted event table会将锁事件写到未格式化的表里(unformatted event table,UE)。之所以叫未格式化,是指里面的信息需要解析才可理解,解析的方法包括JAVA程序和存储过程。
先介绍JAVA程序,在DB2实例的sample目录下自带了一个Java解析程序,这个Java程序需要编译成class才能执行,编译方法如下:
先复制到指定的目录
cp home/db2ibits/sqllib/samples/java/jdbc/db2evmonfmt.java home/db2ibits/sqllib/samples/java/jdbc/DB2EvmonLocking.xsl home/db2ibits/huangh/locks
然后进入目录/home/db2ibits/huangh/locks,进行编译
/home/db2ibits/sqllib/java/jdk64/bin/javac db2evmonfmt.java (64位平台,如果是32位平台,将jdk64改成jdk32)
然后模拟一个锁等、锁超时和死锁。
当出现锁等、锁超时或死锁后,先取消激活lockevmon事件监视器
db2 "set event monitor lockevmon state=0"
接着就可以用刚才编译过的JAVA程序对未格式化的表进行解析:
/home/db2ibits/sqllib/java/jdk64/bin/java db2evmonfmt -d sample -ue locks -ftext -u db2ibits -p data1234>db2locks.out
-ue <table>指定未格式化的表名,-ftext是将输出格式化为文本文件,-u、-p用来指定用户名和密码。
下面分别模拟一个锁超时、死锁:
(1)锁超时模拟
第一个CLP窗口
db2 "create table t1(id int,name char(10))"
db2 "insert into t1 values (5,'fff')"
db2 +c "update t1 set name='ggg' where id=5"
db2 +c "select * from t1 where id=5"
第二个CLP窗口
db2 +c "update t1 set name='hhh' where id=5"
这样锁超时发生时,该事件监视器会记录锁超时的信息。
(2)死锁模拟
在第一个CLP窗口中创建两张表:t1和t2,然后在t1和t2表中各插入一行数据:
db2 "create table t1(id int,name char(10))"
db2 "create table t2(id int,name char(10))"
db2 "insert into t1 values (4,'eee')"
db2 "insert into t2 values (4,'eee')"
在第一个CLP窗口中,更新t1表中一行数据:
db2 +c "update t1 set name='ggg' where id=4"
在第二个CLP窗口中,更新t2表中一行数据:
db2 +c "update t2 set name='ggg' where id=4"
然后,在两个窗口中分别执行对t1、t2表的查询。
在第一个窗口中访问T1表
db2 +c "select * from t2 where id=4 with rr"
在第二个窗口中访问T1表
db2 +c "select * from t1 where id=4 with rr"
当两个窗口命令都输入后,同时执行(或较短的切换时间),会发现其中一个事务由于死锁而回滚。
结果文件db2locks.out见附件。
文件中的内容与上面提到的死锁格式一致,这里不再列出。
还可以通过SYSPROC.EVMON_FORMAT_UE_TO_TABLES存储过程将未格式化表转换为一组关系表,语法如下:
EVMON_FORMAT_UE_TO_TABLES(evmon_type,xsrschema,xsrobjectname,xmlschemafile,tabschema,tbsp_name,options,commit_count,fullselect)
在这个存储过程中,evmon_type指定为LOCKING,OPTIONS指定为RECREATE_FORCE,表示重建关系表,tabschema指定创建关系表的模式,tbsp_name指定表空间,fullselect是指定查询和过滤条件进行格式化:
db2 "call sysproc.EVMON_FORMAT_UE_TO_TABLES('LOCKING',NULL,NULL,NULL,NULL,NULL,'RECREATE_FORCE',-1,'SELECT * FROM LOCKS ORDER BY EVENT_TIMESTAMP')"
这个存储过程的结果是一组关系表,以下是这几张表的含义。
LOCK_EVENT:表对应发生的锁事件,每个事件对应一条记录
LOCK_PARTICIPANTS:表标识锁事件的参与者,每个参与的应用程序对应一行记录
LOCK_PARTICIPANT_ACTIVITIES:表包含了参与事件的应用程序曾今和当前正在执行的语句。
这些表中都有一个XMLID列来唯一标识每个事件,这个列的内容格式如下:
<event_header>_<event_id>_<event_type>_<event_timestamp>_<partition>
例如:对于锁事件,event_header统一为db2LockEvent,
db2LockEvent_6_DEADLOCK_2012-12-07-14.14.13.017327_0
db2LockEvent_4_LOCKWAIT_2012-12-07-14.14.08.804055_0
可通过SQL语句对锁相关事件进行查询(完全可找出引起死锁、锁超时、锁等待的SQL语句):
select substr(lp.xmlid,1,64),lp.participant_no,lp.participant_type,lp.application_handle,lp.participant_no_holding_lk,lpa.activity_id,lpa.activity_type,varchar(lpa.stmt_text,50) as statement from LOCK_PARTICIPANTS lp,LOCK_PARTICIPANT_ACTIVITIES lpa where lp.xmlid=lpa.xmlid and lp.participant_no=lpa.participant_no order by lp.xmlid desc,lp.participant_no,lpa.activity_id
以下语句用来统计各类锁事件发生的次数
db2 "select substr(event_type,1,20) as event_type,count(*) as count from lock_event group by event_type"
对未格式化表(UE表)的维护,有如下建议:
创建独立的表空间,考虑到内联LOB的高效率,建议创建独立的pagesize为32页的表空间。
当锁事件发生频繁的时候,会导致UE表增长很快,建议定期删除不需要的数据。注意:在删除以前需要首先通过set … state=0将事件监控器先关闭,否则会出现锁等导致数据无法删除。
当不需要锁事件监控器时,可以通过drop命令删除。但删除事件监控器并不会删除UE表,UE表必须通过手工删除。如果没有删除UE表,以后再创建事件监控器时,不能再使用同样的UE表。
删除操作:
db2 set event monitor LOCKEVMON state=0
db2 drop event monitor LOCKEVMON
db2 drop table LOCKS
在没有创建locking事件监视器前,查看系统已发生的死锁:
db2evmon -db sample -evm DB2DETAILDEADLOCK>deadlock.txt
db2evmon -path /home/db2ibits/db2ibits/NODE0000/SQL00006/MEMBER0000/db2event/db2detaildeadlock>deadlock.txt
总结:DB2 V9.7的锁监控方式方便且统一,适合部署在生产环境,在发生锁问题时,可以配置为只在锁超时和死锁的情况下才记录锁的信息和SQL语句的信息到locks表,因为锁超时和死锁通过该方式在测试环境部署,应该能解决大部分锁问题,继续在生产环境出现的几率很小,决定了locks表不会很大,假设一个锁的信息产生100条记录,每条记录大小大约为1KB,这样假设在1个月的监控期间产生了10个锁超时、5个死锁,那么这个表占用的物理大小为(10+5)*100*1KB=1500KB,这是理论大小,那么实际大小也不会很大,所以部署这种锁监控对数据库的性能和空间造成的影响可以忽略。
4.3.db2pd监控锁
TranHdl:用于指定事务句柄,以便只监视由特定事务持有的锁
showlocks:这个子选项将锁名称扩展成为有意义的解释。
下面展示了检查锁等待情形:
db2pd –d bitsdb –locks wait showlocks
db2pd -d bitsdb -transactions tranhdl 2
5日志案例
1 、当前数据库所有连接断开,日志就被归档吗?
答:日志会被归档,活动日志变成非活动日志并被复制到归档目录。重新连接数据库时,数据库管理器创建新的主日志文件并格式化。
要使日志不被频繁归档,可用如下命令激活数据库:db2 activate db sample,这样,当当前数据库连接都断开的时候,不会引起日志频繁归档。
2 、误删除表容器后应该如何恢复数据库最安全?
答:在数据库恢复前,建议断开所有数据库连接并且取消激活数据库,这样,可以把所有活动日志都变成归档日志,然后在数据库前滚的时候,如果归档日志文件很多,通过db2 "rollforward db sample query status"查找前滚开始的日志文件,从归档日志目录中,把这个文件和之后的日志文件拷贝到溢出目录。
以BITS系统为例,每天凌晨两点做一个数据库在线全量备份,中午12:00的时候数据库因为表空间被误删除而崩溃,这个时候,可以db2 force applications all; db2 "deactivate db sample",然后把归档日志路径下的日志文件复制到一个溢出路径,比如该溢出路径为/home/db2ibits/bitslog,然后通过凌晨两点的备份做数据库恢复,如:db2 "restore db sample",数据库前滚的时候,用如下命令前滚,可以保证数据库的完整性和一致性:
db2 "rollforward db sample to end of logs and stop overflow log path (/home/db2ibits/bitslog) noretrieve"。
6锁案例
1、RR隔离级别中,读过的行是什么意思?
描述:RR(Repeatable Stability):可重复读隔离级别,即把读过的行都加S锁。可以防止丢失更新、脏读、不可重复读、幻像读的情况。这里"读过的行"是指什么意思?
答:只要是扫描过的行(读过的行)都会加锁,若全表扫描,就加表锁;若走索引,相关的行(扫描过的、而不是符合过滤条件的)加锁。下面是一个例子,演示环境为:数据库版本V9.7,隔离级别为RR。
例如:t1这张表,表结构如下:
db2 "create table t1(id int,name char(10))"
该表有如下记录:
1、db2 "insert into t1 values (1,'a')"4
2、db2 "insert into t1 values (1,'b')"5
3、db2 "insert into t1 values (1,'c')"6
4、db2 "insert into t1 values (2,'a')"7
5、db2 "insert into t1 values (2,'b')"8
6、db2 "insert into t1 values (2,'c')"9
执行如下查询:
db2 +c "select * from t1 where id=1 and name='a' with rr"
显示加锁情况如下:
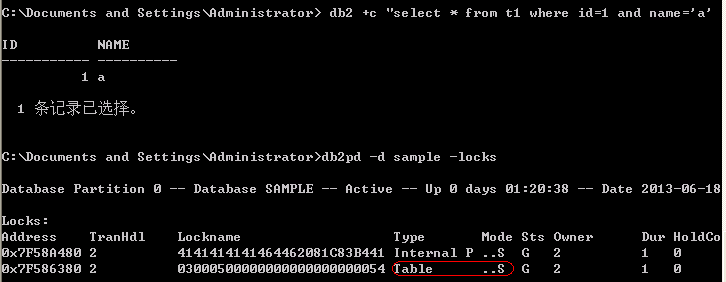
加锁结果为直接对表加S锁,这是为什么?
答:没有索引,全表扫描,那么直接对表加S锁。
创建如下索引:
db2 "create index t1_i1 on t1(id,name) allow reverse scans"
执行db2 +c "select * from t1 where id=1 and name='a' with rr"
显示加锁情况如下:
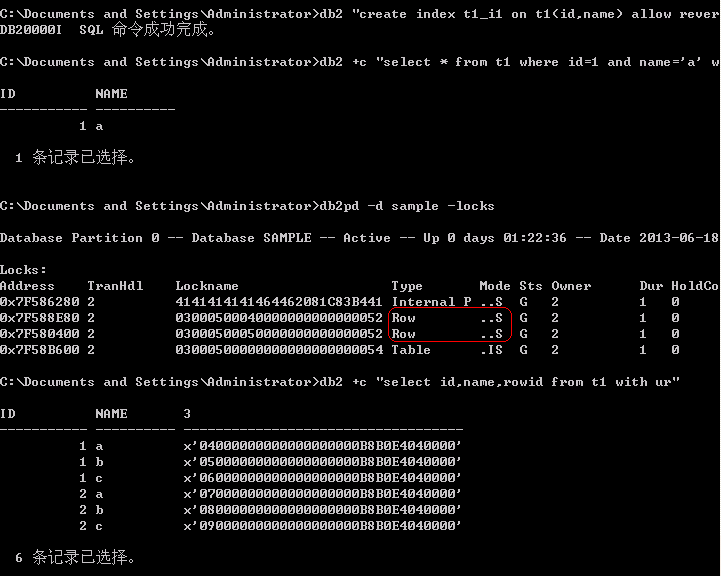
经过db2 +c "select id,name,rowid from t1 with ur",确认了第一个锁是对第1行加了行锁,第二个锁是对2加了行锁。这里加锁结果,是为什么?
答:根据创建的联合索引,扫描了1、2行,到第2行的时候,已经知道第2行不符合条件了,所以不会去扫描第3行,这就是为什么第2行有S锁,第3行没有的原因。
2、RR隔离级别如何保证不会出现幻像读
第一个CLP窗口:
db2 "create table t1(id int,name char(10))"
db2 "create index t1_i1 on t1(id) allow reverse scans"
db2 "insert into t1 values (1,'a'),(3,'b'),(5,'c')"
db2 +c "select * from t1 where id>=1 and id<=3 with rr"
加锁情况为:

第二个CLP窗口:
通过db2 "select id,name,rowid from t1",结果如下:

知道c1=1的行号为4,c1=3的行号为5,c1=5的行号为6,因为Lockname是由表空间ID+表ID+ROWID+锁类型组成,可以看出,db2 +c "select * from t1 where c1>=1 and c1<=3 with rr"
对c1=1、c1=3、c1=5三行都加了S行锁。
在该窗口下执行如下操作:
db2 "insert into t1 values (3,'f')"
这个操作处于锁定等待。
当前锁状况如下:
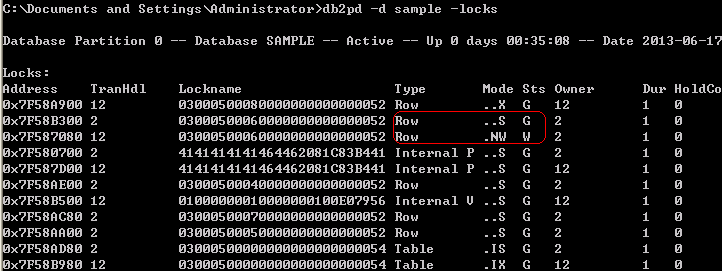
原因在于:将行插入到索引时,获取对下一行的NW锁定。但该行已经被另一应用持有了S锁定,因为NW与S不兼容,所以该插入动作将处于锁定等待状态。保证了应用程序继续执行db2 +c "select * from t1 where id>=1 and id<=3 with rr"的时候不会出现幻像读。
如果不是执行db2 "insert into t1 values (3,'f')",而是执行
db2 "insert into t1 values (4,'f')",将因为同样的原因也对id=5 and name=’c’的记录申请NW锁而出现锁等待,从这里可以看出,RR隔离级别为了保证不会出现幻像读,定义的过于严格,出现了BUG。
如果执行db2 "insert into t1 values (5,'f')",是能够成功插入。
NW 下一键弱排他锁(next key weak share): 当插入索引时,申请对该行对应索引键的下一索引键对应的行加NW锁,如果加锁成功,就开始执行插入操作。
3、进行出口买单修改交易时发生死锁分析
现象描述:生产环境两个柜员在做不同业务编号的出口买单修改交易的时候,因为死锁,一个柜员做的交易出现了异常。数据库版本为DB2 V9.7,CUR_COMMIT为ON,隔离级别为RS
原因解释:假设出口买单表为t1,表结构和相关信息如下:
db2 "create table t1(id int,name char(10),c3 varchar(10))"
创建了如下索引:
db2 "create index t1_i1 on t1(id)"
该表中有如下记录:
db2 "insert into t1 values(1,'a','111'),(3,'b','333'),(5,'c','555'),(7,'d','777'),(9,'e','999')"
当时的情况用CLP模拟,类似于如下场景:
第一个CLP窗口执行:
db2 +c "update t1 set name='ff' where id=3 "
第二个CLP窗口执行:
db2 +c "update t1 set name='gg' where id=5"
然后在第一个CLP窗口键入如下待执行语句:
db2 +c "select * from t1 where c3='333' with rs"
在第二个CLP窗口键入如下待执行语句:
db2 +c "select * from t1 where c3='555' with rs"
同时在第一个CLP窗口和第二个CLP敲回车键,执行两个SELECT语句,这时在第三个CLP窗口通过db2pd -d sample -locks获得锁情况如下:
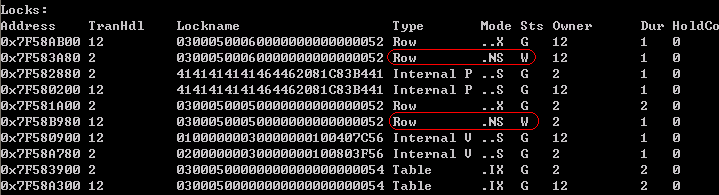
过了一会,第二个CLP窗口因为死锁而回滚。信息如下:
SQL0911N 因为死锁或超时,所以当前事务已回滚。原因码为 "2"。 SQLSTATE=40001
原因在于:因为db2 +c "select * from t1 where c3='333' with rs"进行的是表扫描,行C1=5已经被第二个CLP窗口加了X锁,该select语句在申请NS的时候因为锁不兼容而锁等待。另外一个窗口也是类似。所以出现了互相等待,而死锁。
解决方案:
方案一:创建列C3上的索引
通过创建如下索引减小db2 +c "select * from t1 where c3='333' with rs"语句的加锁粒度。
db2 “create index t1_i2 on t1(c3) allow reverse scans”
重新模拟,问题得到解决。
方案二:设置DB2注册表变量DB2_EVALUNCOMMITTED=ON
为什么DB2_EVALUNCOMMITTED=ON,就不会出现死锁,因为:查询的时候不是先申请锁,而是先计算谓词,如果谓词条件符合,才对该记录申请加锁。对于db2 +c "select * from t1 where c3='222' with rs",id=1的记录根据谓词c3='222'已经排除在外了,所以不会因为id=1的记录而引起锁等待。同样,第一个CLP也不需要等待第二个CLP持有的X锁,这样,查询语句都得到了正确的想要的结果。
在DB2 V9.7版本及之后,建议设置注册表变量DB2_EVALUNCOMMITTED=ON,数据库配置参数CUR_COMMIT=ON,这样可以降低锁的范围,减少锁的个数,同时通过CUR_COMMIT=ON读before image做到写不阻止读,极大提高数据库的并发性,减少锁问题的发生。
4 如何通过U锁避免死锁
先看一个例子:
假设某个员工履行新的工作职责并被调入另一个部门工作。公司的两名部门经理(原部门的经理A和新部门的经理B)正在使用人事部门程序更新SAMPLE数据库的EMPLOYEE表中的该员工电话号码。
在两名部门经理可能并发处理同一条记录的情况下,为了保证读数据的稳定性,需要使用RS隔离级别。但这样,存在发生死锁的可能。如下:
部门经理A对应的应用程序A执行了如下SQL:
select empno,firstnme,phoneno from employee where empno='000010' with rs;
执行一些业务逻辑…
update employee set phoneno='1092' where empno='000010';
部门经理B对应的应用程序B执行了如下SQL:
select empno,firstnme,phoneno from employee where empno='000010' with rs;
执行一些业务逻辑…
update employee set phoneno='1092' where empno='000010';
对于该问题,解决方案有两种:
方案一:选择记录的时候,指定对选中记录加U锁
SQL由
select empno,firstnme,phoneno from employee where empno='000010' with rs;
改成
select empno,firstnme,phoneno from employee where empno='000010' for update with rs;
或
select empno,firstnme,phoneno from employee where empno='000010' with rs use and keep update locks;
方案二:把RS隔离级别修改为CS隔离级别,通过乐观锁来实现功能
乐观锁:假设A应用程序在修改某行时,B应用程序试图对这一行进行修改的可能性极低,如果B应用程序确实对这一行进行了修改,那么A应用程序的更新或删除操作将会失败,A应用程序需要自己处理这些失败,例如通过重新选择来处理失败。
select rid_bit(employee),row change token for employee,empno,firstnme,phoneno from employee where empno='000010';
update employee set phoneno='1092' where rid_bit(employee)=x'00000000000000040000000007340b2d' and row change token for employee=1094216;
文章word版及附件共享链接:
https://pan.baidu.com/s/1kUSG0Vd
供稿 | 黄海 编辑 | lin

