




数据库参数
1配置参数优化
设置参数实际上是在分配资源,需要了解每种资源的特点和数据库中消耗资源的各个对象之间的依赖关系,依据具体情况,对参数设定和调整。
配置和优化系统参数的工作顺利完成后,CPU、内存、磁盘和网络的处理能力应该会得到充分的利用,并高效地运转。
2数据库管理器参数
2.1 代理(agent)
2.1.1 代理概述
DB2的代理(agent)是位于DB2服务器中的服务于应用程序请求的一些线程。当有外部应用程序连接至DB2实例提出访问请求时,DB2的代理就会被激活去应答这些请求。
2.1.2 代理的生命周期

在DB2服务器中存在代理池,当实例刚启动后这里便有一些代理(数量取决于实例参数num_initagents)。在没有任何数据库连接时,它们处于待命状态,就是空闲代理。而当有外部程序连接至数据库时,这些代理开始得到命令去服务于这些新建的连接,这时它们就变成了活动的协调代理。这些协调代理再将请求逐步细分,分配给下一级代理,即子代理去处理。如果当前的代理都已经在工作了,同时又来了新的请求,数据库管理器会创建新的代理去应答。当事务处理完毕而且数据库连接断开后,协调代理要么返回代理池,变回空闲代理,要么就自动销毁(取决于实例参数num_poolagents)。
2.1.3 代理类型
DB2代理大概有三种类型:空闲代理、协调代理(活动协调代理+池协调代理)、子代理(活动子代理+池子代理)。
代理类型 | EDU NAME |
空闲代理 | db2agent(idle) |
活动的协调代理 | db2agent(dbname) |
池协调代理 | db2agntdb(dbname) |
活动的子代理 | db2agntp(dbname) |
池子代理 | db2agnta(dbname |
空闲代理:指的是没有任何任务的代理。这种代理不服务于任何连接,处于一种备用或待命状态。当代理变成空闲代理时,它仍然保留了其代理的私有内存。这样设计是为了提高性能,因为当代理被再次调用时,它便有准备好的私有内存。如果有很多的空闲代理,并且所有这些空闲代理都保留了它们的私有内存,那么就可能导致系统耗尽内存。为了避免这种情况,DB2使用一个注册表变量来限制每个空闲代理可以保留的内存量。这个变量就是DB2MEMMAXFREE。它的默认值是8388608字节。这意味着每个空闲代理可以保留最多8MB的私有内存。如果有100个空闲代理,那么这些代理将保留800MB的内存。
活动的协调代理:指的是处于工作状态的代理,每一个外部应用程序产生的数据库活动连接都有一个活动协调代理来为它服务。
池协调代理:当活动的协调代理完成工作返回池时,该协调代理称为池协调代理,是空闲代理的一种,保留了其代理的私有内存。如果数量超过了NUM_POOLAGENTS参数,那么这个协调代理就会自动销毁。
子代理:指的是接受协调代理分发出来的工作的下一级代理。在DB2 V9.5以前,只有在多分区环境(MPP)或节点内并行(INTRA_PARALLEL=ON)环境下才存在子代理,在DB2 V9.5及以后的版本中所有环境都可能存在子代理。
池子代理:当活动的子代理完成工作返回池时,该子代理称为池子代理,是空闲代理的一种,保留了其代理的私有内存。如果数量超过了NUM_POOLAGENTS参数,那么这个子代理就会自动销毁。
2.1.4 代理程序相关配置参数
NUM_INITAGENTS:这个参数的值指在实例刚刚启动时便生成的一些空闲代理的数目。这是为了提高性能,因为这些代理可以随时变成协调代理去应答外部应用请求,而不用临时生成新的代理。默认值为0。
是否可以联机配置:否
例如:当NUM_INITAGENTS设置为5时,实例启动后,就会产生5个空闲代理。
NUM_POOLAGENTS:这个参数用来控制代理池中的代理的数量,当活动的代理完成工作返回池时,如果数量超过了这个参数,那么这个代理就会自动销毁。默认值AUTOMATIC。
是否可以联机配置:是
注意:在连接集中器激活的情况下,代理池中的代理数目在某一时刻可能会超过NUM_POOLAGENTS的大小,以应对突发的高密度连接。
MAX_COORDANENTS:这个参数决定了实例中在同一时刻最大的协调代理的数目,默认值AUTOMATIC。当前代理数可能会大于MAX_COORDANENTS。
是否可以联机配置:是
MAX_CONNECTIONS:实例允许的最大连接数,默认值AUTOMATIC(MAX_COORDANENTS)。
是否可以联机配置:是
在一个实例下的所有数据库的MAXAPPLS值之和不能超过MAX_CONNECTIONS。
Maxappls:是数据库配置参数,它指定了可以连接到数据库的并发应用程序(本地和远程)的最大数量。默认值automatic,即允许任何数目的应用程序连接。
是否可以联机配置:是
当应用程序尝试连接数据库,但是连接到数据库的应用程序数已经达到了maxappls的值时,会向应用程序返回下面这个错误,表明连接到该数据库的应用程序数已达到了最大值:
SQL1040N The maximum number of applications is already connected to the database. SQLSTATE=57030
2.1.5 代理案例
Current agents= Idle agents+ Active coord agents+ Pooled coord agents +活动子代理+池子代理
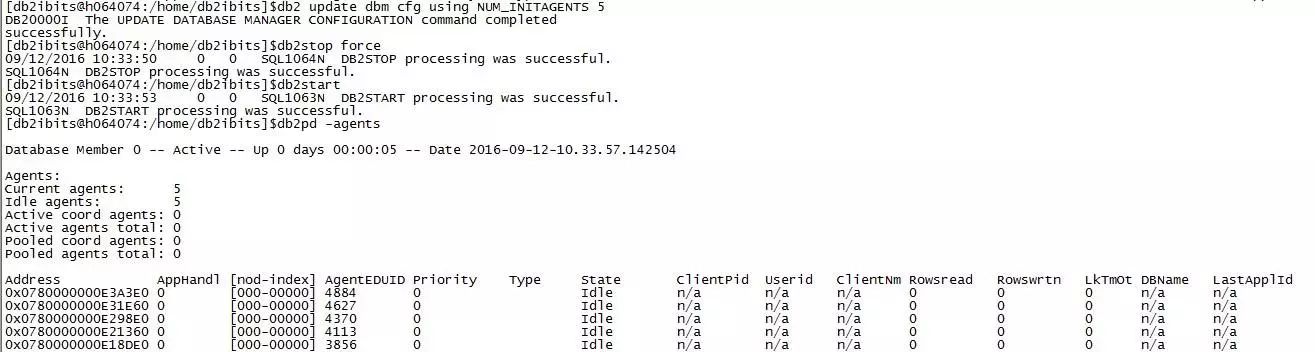
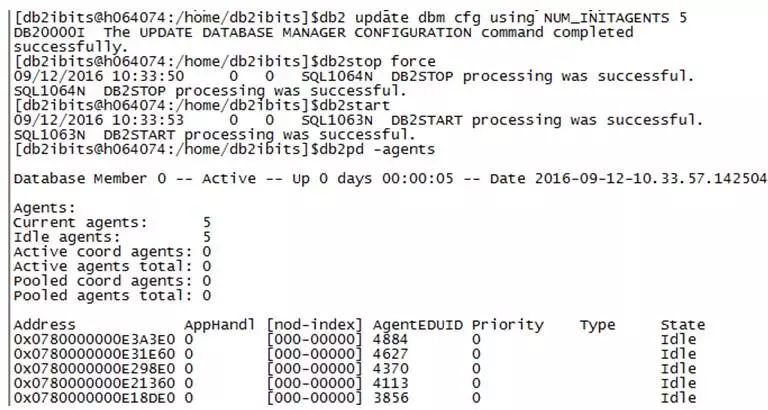
db2 update dbm cfg using NUM_INITAGENTS 5
db2stop force
db2start
db2pd –agents
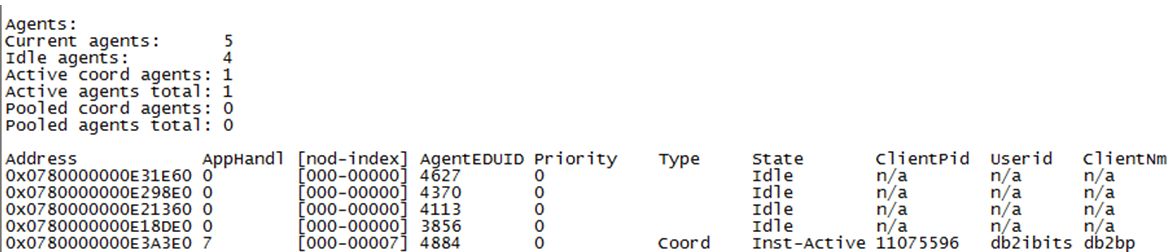
db2 attach to db2ibits
db2pd –agents
db2 connect to bitscn
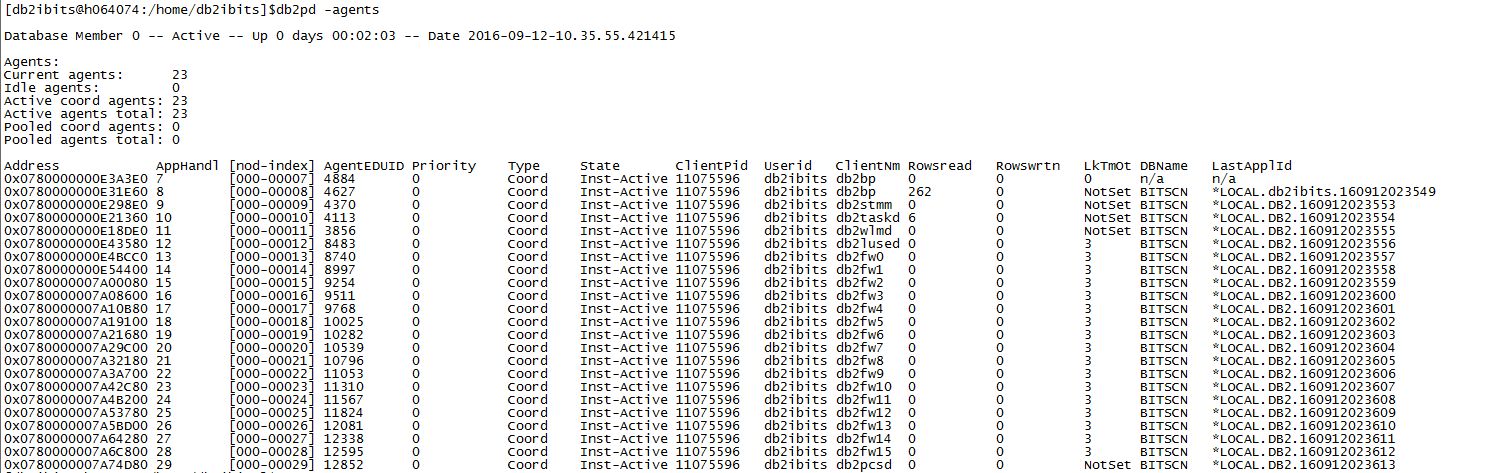
db2 terminate过后,再执行db2pd –agents

开启分区内并行后的当前代理数(数据库管理器参数:MAX_QUERYDEGREE=ANY(默认值)数据库参数:DFT_DEGREE>1 ,设置完毕,重启数据库生效)
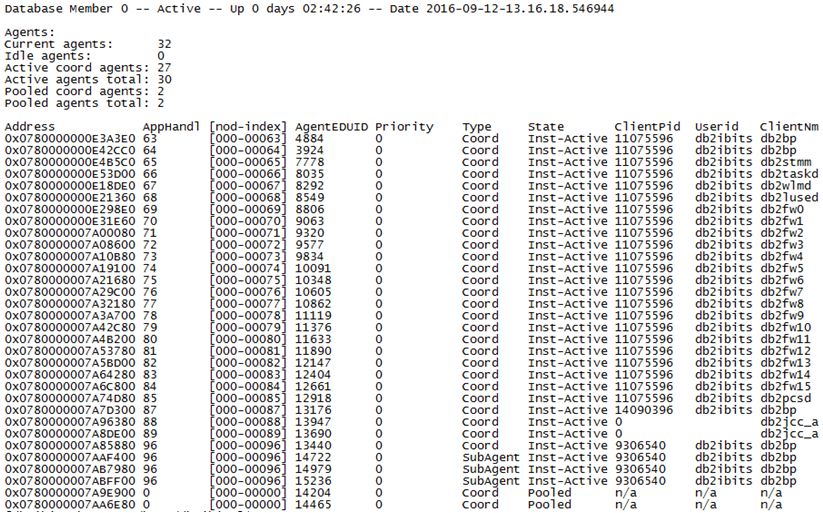
2.1.6 代理使用监控
如下为数据库管理器快照中代理的信息
High water mark for agents registered = 58
Agents registered = 48
Idle agents = 1
Agents assigned from pool = 264081
Agents created from empty pool = 237
Agents stolen from another application = 6
High water mark for coordinating agents = 53
High water mark for agents registered:连接到数据库管理器的代理曾出现的最大数量。
Agents registered:实例中当前注册的代理的数量。
Idle agents:显示了在代理池中空闲代理的数量,
Agents assigned from pool:则显示了从代理池中将一个代理分配出去的次数。
Agents created from empty pool:显示了在空池情况下必须创建的代理的数量。
Agents stolen from another application:从其他暂时空闲的应用程序中偷代理 这种现象出现的次数。
High water mark for coordinating agents:连接到数据库管理器的协调代理曾出现的最大数量。
当Agents created from empty pool/ Agents assigned from pool的比值比较大(5:1或更大)时,说明这时代理的创建、删除比较频繁,需要增大NUM_POOLAGENTS。
NUM_POOLAGENTS的默认值为automatic(初始值为100)。
NUM_INITAGENTS的默认值为0。
在没有打开连接集中器的情况下,如果Agents stolen from another application不为 0,需要调大数据库管理器参数MAX_COORDAGENTS的值。
如果对最大连接数和协调代理数都不想进行限制的话,可以将它们都设定为automatic。如下:
MAX_COORDAGENTS = AUTOMATIC(200)
MAX_CONNECTIONS = AUTOMATIC(MAX_COORDAGENTS)
2.2 实例快照监控开关
建议打开,快照、表函数、动态性能视图等的输出元素很多来自监控元素。
设置方式为:
db2 attach to db2ibits
db2 update dbm cfg using DFT_MON_BUFPOOL ON DFT_MON_LOCK ON DFT_MON_SORT ON DFT_MON_STMT ON DFT_MON_TABLE ON DFT_MON_UOW ON
判断参数是否可联机设置:设置完毕后查看内存值和磁盘值是否一致
查看数据库管理器参数,需要先attach实例,db2 attach to db2ibits,然后执行。
db2 get dbm cfg show detail|grep –I mon
查看数据库参数,需要先connect数据库,db2 connect to bitscn,然后执行。
db2 get db cfg show detail|grep –i sort
如果内存值和磁盘值一致,表示可联机设置,并已生效。
注意:如果设置了监控开关打开,在当前会话并不能获取到有效的快照信息,需要重新打开一个窗口获取快照。
2.3 数据库监控堆大小(mon_heap_sz)
这是为数据库系统监视器(system monitor)分配的内存数量。当执行诸如捕获快照之类的数据库监控活动时,就要从监视器堆中分配内存。获取快照时需要把监控元素从各内存块中集中整理到MON_HEAP_SZ,然后输出,获取快照时间一般为0.03秒。
如果该内存过小,不足以存放快照的基本数据结构,那么将报类似如下的错误:
SQL0973N Not enough storage is available in the "MON_HEAP_SZ" heap or stack to process the statement. SQLSTATE=57011
建议大小设置为8192(32M)。
2.4 分区内并行(Intra_parallel)
指定数据库管理器是否可以使用分区内并行。对于OLTP系统,其并发连接数通常较多,这时关闭分区内并行较好(CPU富余的环境建议开启),对于OLAP等并发连接较少并且SQL较复杂的情况下,开启分区内并行通常能够获益。
简单工作负载通常指IO密集工作负载(OLTP),而复杂工作负载通常是CPU密集负载(OLAP),混合工作负载是指具有70% OLTP,30% OLAP的特性,对于简单工作负载和混合工作负载通常不启用分区内并行。
如果系统是OLAP的, CPU数与分区数的比例是4:1,CPU负载运行的平均百分比是50%,启用intra_parallel很可能会提高性能。
如果启用分区内并行,请按照如下设置:
数据库管理器参数:
INTRA_PARALLEL=YES(默认为NO)
其他配置均采用默认值(MAX_QUERY_DEGREE 为 -1 或 ANY,DFT_DEGREE 为 -1 或 ANY,这两个参数的取值范围为-1,1到32767)
需重启数据库生效。
在多处理器(Multiple Processors)环境下,使用数据库分区内的并行处理特性,能大大提高 CPU 的利用率,进而提高数据库查询的性能。通常来说,在 DB2 中,启用 INTRA_PARALLEL 之后,其他配置均采用默认值(MAX_QUERY_DEGREE 为 -1 或 ANY,DFT_DEGREE 为 -1 或 ANY),即可使系统达到最优状态。在某些情况下,如果 DB2 的并行性能未能达到最优,可根据数据分布特性、查询的特征等手工配置相应的并行度,使查询性能得到优化,手动设置方法为:db2 SET CURRENT DEGREE \'4\'。
2.5 KEEPFENCED
Keep Fenced Process,UDF和SP按照运行模式分为两种:fenced和unfenced,fenced模式是一种c/s的通信方式,存储过程为客户端请求server的一个 agent为其执行业务逻辑。unfenced模式是一种直接调用db2进程并在进程的地址空间内执行,有不安全性,但该模式可以读取运行的PID,而 fenced模式做不到。
如果KEEPFENCED设置为YES,可以使UDF或SP所调用fenced进程或线程一直保持并被重复使用,一直到实例关闭才销毁,但这将占用一定资源(如内存)。例如,使用java写的sp,sp运行完成后不会结束JVM,下次运行sp将省去启动JVM的时间。
配置:
update dbm cfg using keepfenced YES
3数据库参数
3.1 内存
3.1.1、Instance_memory
定义:实例内存,可以为数据库分区分配的最大内存量
默认值:automatic
是否可以联机配置:是
设置指引:该值可以保持为automatic。在激活数据库分区时计算值,计算值介于物理内存的75%到95%之间。对于非独立的数据库服务器,根据实际需求指定大小。
设置:
[db2ibits@h148137:/home/db2ibits/huangh]$db2 get dbm cfg show detail|grep -i INSTANCE_MEMORY
Size of instance shared memory (4KB) (INSTANCE_MEMORY) = AUTOMATIC(1744455) AUTOMATIC(1744455)
3.1.2、SELF_TUNING_MEM
定义:根据需要在启用了自调整功能的内存使用者之间动态地分配可用内存资源。
默认值:单分区环境ON,多分区环境OFF
是否可以联机配置:是
设置指引:从DB2 V9开始,DB2引入了内存自动调优的功能。启用此功能之后,内存调整器将在下列内存使用者之间动态分配可用的内存资源:缓冲池、锁定内存、程序包高速缓存和排序内存。
调整器在database_memory配置参数所定义的内存限制范围内工作,database_memory的值也可以自动调整。
将 database_memory 的值设置为 AUTOMATIC之后,调整器将确定数据库的整体内存需求并根据当前数据库需求来增加或减少分配给数据库共享内存的内存量。例如,如果当前数据库需求很高,并且系统上有足够的可用内存,那么将为数据库共享内存分配较多的内存。如果数据库内存需求下降,或者系统上的可用内存量变得过低,那么将释放一些数据库共享内存。
如果 database_memory 配置参数未设置为AUTOMATIC,那么数据库将使用指定的内存量,根据需要在内存使用者之间分配内存。通过两种方法来指定此内存量:将 database_memory 设置为某个数值或者将其设置为 COMPUTED。在后一种情况下,总内存量基于数据库启动时的数据库内存堆初始值之和。
还可以对内存使用者启用自调整功能,如下所示:
对于锁定内存,使用 locklist 或 maxlocks 数据库配置参数(指定 AUTOMATIC 值)
对于程序包高速缓存,使用 pckcachesz 数据库配置参数(指定 AUTOMATIC 值)
建议不要对缓冲池、排序堆启用内存自动调整功能。
注:
1).locklist 数据库配置参数的值将与 maxlocks 数据库配置参数一起进行调整。对 locklist 参数禁用自调整功能将自动地对 maxlocks 参数禁用自调整功能,而对 locklist 参数启用自调整功能将自动地对 maxlocks 参数启用自调整功能。
2).仅当数据库管理器配置参数 sheapthres 设置为 0 时,才允许自动调整 sortheap 或 sheapthres_shr 数据库配置参数。
3).sortheap 的值将与 sheapthres_shr 一起进行调整。对 sortheap 参数禁用自调整功能将自动地对 sheapthres_shr 参数禁用自调整功能,而对 sheapthres_shr 参数启用自调整功能将自动地对 sortheap 参数启用自调整功能。
如果工作负载的内存特征不断变化,那么 STMM 将以较低的频率在多变的目标条件下进行调整。在这种情况下,STMM 将无法实现绝对汇合,而是尝试维护针对当前工作负载进行调整的内存配置。
3.1.3、Database_memory
定义:数据库共享内存区域保留的内存量
默认值:automatic
是否可以联机设置:是
设置指引:该参数代表数据库的共享内存,建议保持为automatic。
DATABASE_MEMORY不超过instance_memory,instance_memory(75%-95%物理内存)。
3.1.4、缓冲池
定义:用于存放读入的数据页和将要写入的数据页
建议值:物理内存大小的50%
是否可以联机配置:是
设置指引:调整缓冲池的个数;调整每个缓冲池的大小
案例:缓冲池命中率
来源:db2pd -d dbname -bufferpools
指标:优秀>95%,良好>80%
描述:从内存中访问数据仅需纳秒级,而从磁盘访问数据则需数毫秒。DB2对数据的获取是通过缓冲池,如果数据已经缓存到缓冲池,就可通过缓冲池直接获取,如果数据不在缓冲池,则需要从磁盘读到缓冲池。因此,命中率越高,代表着读取同样的数据时需要的 I/O 越少,性能就越好。
分析:
TBSBP4K的数据和索引缓冲池命中率分别为:67.43%、93.94%,该缓冲池大小为4.3G,只被表空间TBS4K使用,目前所有应用表都位于该表空间上。
其余缓冲池IBMDEFAULTBP、TMPBP、OPMBP大小分别为28.2M(Automatic)、530.0M、1.5G,分别被表空间SYSCATSPACE、SYSTOOLSPACE,TEMPSPACE1,OPMTS使用到,这些缓冲池的命中率都大于99%,按照经验,OPMTS分配的内存可以降低,由当前的1.5G降低为0.5G。
通过db2 "call get_dbsize_info(?,?,?,-1)"得到数据库大小为223477669888Bytes,约为208G,即大约208G的数据应用4.3G的缓存,明显偏小。
建议:
1、调整TBSBP4K缓冲池的大小,由当前的4.3G调整到16G。
db2 "alter bufferpool TBSBP4K immediate size 4194304"
2、调整OPMBP缓冲池的大小,由当前的1.5G调整到0.5G。
db2 "alter bufferpool OPMBP immediate size 16000"
3、表空间规划
创建一个缓冲池TBSBP4K_IDX,大小为4G、一个表空间TBS4K_IDX,大小为200G,把应用表的数据和索引分离,提高缓存的效率。这步可以暂缓实施,由项目组决定是否执行。
3.1.5、排序
数据库管理参数:SHEAPTHRES
数据库参数:Sortheap、sheapthres_shr
设置指引:sortheap是数据库级配置参数,它定义了用于排序的专用内存页的最大数目。每当用户递交了排序请求,排序操作首先会在代理私有内存中进行(私有排序),私有排序区的大小由数据库参数SORTHEAP决定。只有SHEAPTHRES=0时排序才会移至数据库共享内存中进行(共享排序)。不管私有排序还是共享排序,出现排序溢出,将会造成20%的性能下降。
建议如下设置:
SHEAPTHRES=0
SORTHEAP = 50000(200M)
HEAPTHRES_SHR = 200000(800M)
排序监控:数据库快照
Total Private Sort heap allocated = 0
Total Shared Sort heap allocated = 0
Shared Sort heap high water mark = 22398
Post threshold sorts (shared memory) = 0
当前使用的共享排序堆值( Total Shared Sort heap allocated)
共享排序堆高水位标记(Shared Sort heap high water mark):SHEAPTHRES_SHR的历史峰值。如果超过了SHEAPTHRES_SHR的当前设置值,建议参考高水位值调大SHEAPTHRES_SHR。
排序阈值(Post threshold sorts):排序 sortheap 请求对共享内存堆空间的并发使用而受限的总次数。这意味着排序请求了一定量的 sortheap,但得到的少于请求的。它可能表明SHEAPTHRES_SHR 对于工作负载太小。
Total sorts = 342710
Total sort time (ms) = 160512
Sort overflows = 2280
Active sorts = 0
Number of hash joins = 142264
Number of hash loops = 0
Number of hash join overflows = 0
Number of small hash join overflows = 0
Post threshold hash joins (shared memory) = 0
Active hash joins = 0
散列连接总数(Number of hash joins):已执行的散列连接的总数。
散列循环总数(Number of hash loops):散列连接的单个分区大于可用 sortheap 的总次数。如果次数较多,必须调大sortheap的值。
如果 DB2不能将构建表的所有行放入内存,会将某些分区溢出到临时表以供以后处理。在处理这些临时表时,DB2 会尝试将每个构建分区装入一个 sortheap。然后 DB2读取相应的探测行,并设法使它们与构建表匹配。如果 DB2 不能将某些构建分区装入 sortheap,则 DB2 必须借助散列循环算法。散列循环表明散列连接的执行效率低下,并且可能导致严重的性能下降。它可能表明 sortheap 大小对于工作负载太小。
散列连接溢出数(Number of hash join overflows):将构建表中的行放入内存时超出了可用 sortheap 的总次数。
散列连接少量溢出数(Number of small hash join overflows):将构建表的行放入内存时,散列连接超过可用 sortheap 不到 10% 的总次数。出现较小的溢出表明增加 sortheap 有助于提高性能。
散列连接阈值(Post threshold hash joins):散列连接 sortheap 请求对共享内存堆空间的并发使用而受限的总次数。这意味着散列连接请求了一定量的 sortheap,但得到的少于请求的。它可能表明SHEAPTHRES_SHR 对于工作负载太小。
监控指标:
Sort overflows/ Total sorts<5%,否则应该同步调整SORTHEAP和SHEAPTHRES_SHR的大小,每次调整幅度为10%
Post threshold sorts<10,否则应调整SHEAPTHRES_SHR的大小,每次调整幅度为10%
Number of hash loops<10,否则应调整SORTHEAP的大小,每次调整幅度为10%
Number of hash join overflows<100,否则应调整SORTHEAP的大小,每次调整幅度为10%
Number of small hash join overflows<100,否则应调整SORTHEAP的大小,每次调整幅度为10%
Post threshold hash joins<10,否则应调整SHEAPTHRES_SHR的大小,每次调整幅度为10%
案例一:排序堆大小建议设置为固定值
创建一个测试表
db2 "create table employee(emp_id int not null primary key,name char(20),dept_id int,salary decimal,address char(30),remark char(40)) in WF_DATA_DMS_8K"
初始化100W条数据
db2 "begin atomic declare count int default 1; while(count<1000000) do insert into employee values(count,'--emp' concat char(count),ceiling((rand()*1000)),20000.50,'-----address' concat char(count) concat '---','------remark' concat char(count) concat '----'); set count=count+1;end while;end"
该语句执行排序
db2 "select dept_id,name from employee where dept_id<100 order by dept_id"|grep selected
测试结果1:
数据库参数设置:
SHEAPTHRES=200000
HEAPTHRES_SHR = AUTOMATIC(53668)
SORTHEAP = AUTOMATIC(1024)
结果:私有排序
排序执行中的快照:
Total Private Sort heap allocated = 1024
Total Shared Sort heap allocated = 0
Shared Sort heap high water mark = 0
Post threshold sorts (shared memory) = 0
Total sorts = 0
Total sort time (ms) = 0
Sort overflows = 0
Active sorts = 1
排序执行完的快照:
Total Private Sort heap allocated = 0
Total Shared Sort heap allocated = 0
Shared Sort heap high water mark = 0
Post threshold sorts (shared memory) = 0
Total sorts = 1
Total sort time (ms) = 81
Sort overflows = 1
Active sorts = 0
测试结果2:
数据库参数设置:
SHEAPTHRES=200000
SORTHEAP = 10000
HEAPTHRES_SHR = 20000
结果:私有排序
排序执行中的快照:
Total Private Sort heap allocated = 7816
Total Shared Sort heap allocated = 0
Shared Sort heap high water mark = 0
Post threshold sorts (shared memory) = 0
Total sorts = 1
Total sort time (ms) = 81
Sort overflows = 1
Active sorts = 1
排序执行完的快照:
Total Private Sort heap allocated = 0
Total Shared Sort heap allocated = 0
Shared Sort heap high water mark = 0
Post threshold sorts (shared memory) = 0
Total sorts = 2
Total sort time (ms) = 150
Sort overflows = 1
Active sorts = 0
测试结果3:
数据库参数设置:
SHEAPTHRES=0
SORTHEAP = 10000
HEAPTHRES_SHR = 20000
结果:共享排序
排序执行中的快照:
Total Shared Sort heap allocated = 7816
Shared Sort heap high water mark = 7816
Post threshold sorts (shared memory) = 0
Total sorts = 0
Total sort time (ms) = 0
Sort overflows = 0
Active sorts = 1
排序执行完的快照:
Shared Sort heap high water mark = 7816
Post threshold sorts (shared memory) = 0
Total sorts = 1
Total sort time (ms) = 70
案例二:排序溢出比例
来源:数据库快照
公式:排序溢出次数/排序总数(Sort overflows/Total sorts)
指标:OLTP:5,或者在接近 5 的数值上长时间维持稳定
描述:排序溢出就是当排序内存不够时,数据需要使用临时空间进行排序。一般来说,希望数据尽可能在内存中完成。当发现大量的排序溢出时,就要看排序堆内存参数设置是否足够大。
分析:
Sort overflows = 10448
Total sorts = 145116
指标值=10448/145116=7.19%
数据库参数:
SORTHEAP = 16834
建议:
调整SORTHEAP参数值为50000,语句为:
db2 update db cfg using SORTHEAP 50000
不需要重启数据库
案例三:平均排序时间
来源:数据库快照
公式:排序总时间/排序总数(Total sort time (ms)/Total sorts)
指标:远小于系统预期平均语句的执行时间
描述:一般来说,一条语句的执行时间包括锁等待、数据读取时间、排序时间。因此用数据库中平均的排序时间对比平均语句返回的速度,就可以大概估算出执行一条语句时有多少的时间用于排序。一般都希望排序时间越少越好。如果该值过高,用户可以考虑优化查询与添加索引,尽量减少排序的消耗。
分析:
Total sorts = 145116
Total sort time (ms) = 1457123
指标值=1457123/145116=10.04ms
建议:
调优SQL
案例四:平均每条交易的排序次数
来源:数据库快照
公式:排序总数/交易总数(Total sorts/(Commit statements attempted+ Rollback statements attempted))
指标:OLTP<5
描述:对于 OLTP 应用来说,由于每条交易的短小精干的特性,我们需要尽可能减少每条交易所需的排序数量。
大部分情况下,这种调优需要应用开发人员的配合,一方面在数据库中建立合适索引的同
时,另一方面优化应用程序逻辑,减少 SQL 所需要排序的次数。在典型的 OLTP 系统中,尽量将每一条交易平均所需的排序数量维持在 5 以下。
分析:
Total sorts = 145116
Commit statements attempted = 283029692
Rollback statements attempted = 30766
指标值=145116/(283029692+30766)=0.000512
建议:
无
3.1.6、Pckcachesz
定义:用于高速缓存数据库上的静态和动态SQL。
默认值:64 位 automatic [-1, 32-2147483646] [0G-8G]
是否可以联机配置:是
设置指引:该参数在OLTP环境中比较重要,程序包高速缓存(pckcachesz)用来缓存数据库上的静态SQL程序包,使数据库管理器在重新装入程序包时可以不访问系统目录;或者对于动态SQ语句,可以免去编译这一步;如果PCHR<100%或PKG_CACHE_NUM_OVERFLOWS>0,就需要考虑适当增大pckcachesz的大小。
案例:包缓存命中率(package cache hit ratio)
来源:数据库快照
公式:1-包缓存插入数量/包缓存读取数量(1–Package cache inserts Package cache lookups)
指标:1,或者能够长时间保持接近 1 的稳定数值
描述:该指标表示有多少查询语句可以直接在包缓存中找到。当一条查询被请求的时候,数据库在将其编译之前,首先要从包缓存中查找有没有已经被编译好的包可以直接运行。如果该包已经存在,那么该 SQL 可以直接被运行而不用再次编译。如果应用程序在运行一段时间后,绝大部分的语句都已经被缓存在包缓存中,那么可以节省很多 SQL 编译的时间与 CPU 消耗。
分析:
Package cache lookups=283055153
Package cache inserts= 823216
包缓存命中率=1-823216/283055153=0.997
数据库参数PCKCACHESZ= AUTOMATIC(8222)
内存高水位= 330.9M
建议:
无
3.1.7、Catalogcache_sz
定义:编目缓存可以使用的最大空间,用于缓存系统编目信息
默认值:-1[MAXAPPLS*5]
是否可以联机配置:是
设置指引:由于DB2对系统表的高频率使用,让其常驻内存可以提高性能。编目缓存保存着一些重要编目信息的数据结构,当系统需要这些信息的时候,可以直接以二进制的方式在数据结构中提取出需要的信息,而不是依靠关系表查找出相应的行和列。一般来说,该参数不需要过于频繁的调整,当认为编目缓存过小时,可以逐步增加编目缓存的大小来适应系统的需求。
案例:编目缓冲区插入比例
来源:数据库快照
公式: 编目缓冲区插入次数/编目缓冲区查询次数(Catalog cache inserts/Catalog cache lookups)
指标:0,或者在接近 0 的数值上长时间维持稳定
描述:在系统的每一个分区中,Catalogcache_sz中都会分配出一块空间用于缓冲编目表的信息。在数据库的日常操作中,查询编目表是一个非常频繁的操作。譬如当用户从一个表读取数据的时候,系统就要查询编目表,理解该表在什么表空间、应该如何访问等信息。因此为了性能着想,DB2 在数据库栈内存中单独开辟了一块空间,用于存储编目信息。
但是如果用户有很多数据库对象,而该编目缓存的大小过小,则该内存无法容纳下所有的
信息。那么当新的信息来临时,就会把一些不常用的信息替换出去。
如果该替换经常发生,那么每次当系统想要查找编目数据时,就要从编目表空间中查找,这样会导致系统性能一定程度上的下降。
因此,一般建议将 catalogcache_sz 设置逐渐增大,直到系统中不再频繁出现编目缓冲区插入的操作。
分析:
Catalog cache lookups = 15709916
Catalog cache inserts = 3910
Catalog cache high water mark = 1279630(Bytes)
数据库参数:
CATALOGCACHE_SZ= 300
db2mtrk –I –d –w结果:
catcacheh高水位为:1.6M
建议:
调整CATALOGCACHE_SZ参数值为500,语句为:
db2 update db cfg using CATALOGCACHE_SZ 500
不需要重启数据库
3.1.8、db_heap
数据库堆(DBHEAP)包括日志缓冲区(logbufsz)和事件监控程序使用的内存,同时,还存放有表(每张表占用4KB)、索引、表空间(每个表空间占用10KB)和缓冲池的控制块信息。在表压缩推出之后,每个表的压缩字典都会保存在数据库堆中,尽管每个压缩字典的大小都不会太大(大概100KB左右),但是如果系统中使用了大量的压缩字段,可能会对数据库堆得大小产生严重的影响。出现内存不够用的时候,数据库将报错,这个值建议设置为AUTOMATIC,这表示数据库堆可以根据需要增大,直到达到database_memory限制或达到instance_memory限制。
事件监控程序使用到DBHEAP的大小,如下:
db2 create event monitor dlock for statements,deadlocks with details write to file '/tmp/db2event' buffersize 8
这个监控程序将耗用8*4KB的缓冲区。
日志缓冲区logbufsz建议设置为8192(即32M)
3.1.9、UTIL_HEAP_SZ
UTIL_HEAP_SZ指定了DB2中实用程序堆的大小,此参数指定可由备份、恢复和LOAD(包括LOAD恢复)命令同时使用的最大内存量。建议配置成102400(即400M)。
案例:增量备份报错
增量备份时,报UTIL_HEAP_SZ空间不足,导致备份失败。把值由20000修改成32768及以上的值后,增量备份成功。
3.1.10、应用程序内存(APPL_MEMORY)
应用程序内存集合。从此集合中分配的内存一般用于特定应用程序的处理,包括应用程序堆、统计信息堆和语句堆及不可配置的共享工作区。
这个值建议设置为AUTOMATIC,这表示APPL_MEMORY可以根据需要增大,直到达到instance_memory限制。
APPL_MEMORY包括:appshrh(应用程序共享内存)+ 每个应用程序占用的内存(apph)+ 语句编译堆(STMTHEAP)+统计信息堆(STAT_HEAP_SZ),如下:
appshrh
4.7M
Memory for application 185
stath apph other
256.0K 320.0K 384.0K
Other这部分内存为代理程序私有内存。
3.1.11、应用程序堆(APPLHEAPSZ)
每个应用一个应用程序堆,存放agent或subagent当前sql文本处理的所需内存,大小决定于sql文本的复杂度及宿主变量大小。如果是分区数据库,这部分内存使用APP_CTL_HEAP_SZ堆,而不在应用程序堆。大小建议设置为AUTOMATIC,按需分配,初始值为64K。在运行时按需要分配内存,这个值仅是上限值。
无法监控,如果应用报错,加倍该值,看应用错误是否消失。
3.1.12、STMTHEAP
语句堆大小(STMTHEAP)---在编译SQL语句期间用作SQL编译器的内存工作空间。
SQL语句编译的时候,会用到该SQL 语句堆(4KB)。假设当前STMTHEAP的大小为2048个4KB页,如果一个SQL文本很大很复杂,编译的时候用到了超过2048个4KB页的大小,此时,该SQL语句执行的时候就会报错,如下:
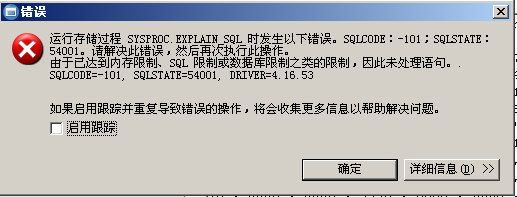
这是通过IBM DATA STUDIO的SQL调整工具运行时报出的错误。
通过db2 update db cfg using STMTHEAP 2048 AUTOMATIC来修改该参数,结果如下:
(STMTHEAP) = AUTOMATIC(2048)
然后再次在IBM的SQL调整中执行该语句,通过查看存取方案图发现语句堆最大使用率为2503 Pages。
所以,建议该参数设置为AUTOMATIC,防止SQL过长过复杂不能执行。
该值是对每个连接分配的内存。该数据值和解释语句有关,如果太小,可能比较大的语句会解释不了。这个内存只在用的时候才申请,平时是不会申请的。
3.1.13、统计信息堆(STAT_HEAP_SZ)
统计信息堆(STAT_HEAP_SZ)的大小指定了使用RUNSTATS命令收集统计信息中所用内存堆的最大值。它是在启动RUNSTATS命令时分配的,然后当它完成时释放。分配更多内存,这样能确保RUNSTATS命令能够更快完成。
案例:
STAT_HEAP_SZ设置值为AUTOMATIC(4384)
执行如下两个runstats
db2 "runstats on table db2obits.bp_transition with distribution and detailed indexes all"
db2 "runstats on table db2obits.wf_task with distribution and detailed indexes all"
查看数据库内存池
db2pd -d bitscn –mempools
Memory Pools:
Address MemSet PoolName Id SecondId Overhead LogSz LogHWM PhySz PhyHWM CfgSize Bnd BlkCnt CfgParm
0x0A000200001D08D0 Appl stath 6 75 0 21597712 21597712 24379392 24379392 24379392 No 1293 STAT_HEAP_SZ
0x0A000200001D0760 Appl stath 6 50 0 8370176 8370176 11141120 11141120 17956864 No 469 STAT_HEAP_SZ
查看数据库内存
db2mtrk -i -d –v
Statistics Heap (75) is of size 24379392 bytes
Statistics Heap (50) is of size 11141120 bytes
3.1.14、代理程序私有内存
代理程序私有内存即agent内存,包括SORTHEAP(私有排序)、JAVA_HEAP_SZ、AGENT_STACK_SZ、QUERY_HEAP_SZ(V9.7之后不存在)。如:
通过db2mtrk -i -d -a -p可以看到
Memory for application 185
stath apph other
256.0K 320.0K 384.0K
Memory for agent 14909
other
384.0K
JAVA_HEAP_SZ:用来限制JAVA存储过程和UDF提供服务的JAVA解释器使用的内存堆的最大值。为了保证线程之间不会发生内存越界问题,每个受防护的UDF、受防护的存储过程进程及运行JAVA存储过程的db2fm进程都有自己单独的内存堆。只有运行JAVA UDF或存储过程的代理线程才会分配此内存。
AGENT_STACK_SZ:限制DB2为每个代理线程分配的虚拟内存大小。对于给定的一组应用程序,可使用此参数优化服务器的内存使用率。与简单的查询语句相比,越复杂的查询语句使用的堆栈空间越多。
Query_heap_sz,占用agent的私有内存空间,存储每个agent运行时所有的sql文件,一般不需要修改,如果访问大的LOB,可能需要增加该值,比如10000。(该参数在V9.7时还存在,V10.1之后就不存在)。
3.1.15、Aslheapsz
Aslheapsz,是app和agent通信的buffer,占用实例共享内存空间。
3.1.16、Rqrioblk
Rqrioblk,是client和server通信的buffer,占用每个agent的私有内存空间,建议设置为最大值64K,默认为32K。
3.1.13、内存参数小结
(1) 任何一个内存配置参数,实际使用值可能大于配置值,表明用了溢出内存,溢出内存存在于实例、数据库中。
(2) 实例内存包括:other(kerh、bsuh等内存池)+ fcmbp+ monh
(3) 数据库全局内存包括:Pckcacheh+Catcacheh+Shsorth+Lockh+dbheap+bufferpool+util heap+other(溢出内存)。
(4) 应用程序全局内存包括:appshrh+ 每个应用程序使用的(apph)内存+stat_heap_sz+stmtheap。
(5) 代理程序专用内存:sortheap+java_heap_sz+agent_stack_sz+ query_heap_sz(V9.7之后不存在)
(6) 内存设置建议
只能设置为固定值的数据库参数
UTIL_HEAP_SZ,建议值400M
CATALOGCACHE_SZ
CHNGPGS_THRESH,建议值60
LOGBUFSZ,建议值8192
对于STMM类型,最好只启用INSTANCE_MEMORY、DATABASE_MEMORY、PCKCACHESZ、LOCKLIST,缓冲池和排序内存设置为固定值;
其他数据库内存参数最好设置为NUM AUTOMATIC。
3.2 锁
3.2.1、DB2_EVALUNCOMMITTED
定义:当启用此变量时,可对未落实的数据进行谓词求值。
DB2V8.1.4中首次引入了DB2_EVALUNCOMMITTED这个DB2注册变量。
DB2_EVALUNCOMMITTED变量影响DB2在游标稳定性(CS)和读稳定性(RS)隔离级别下的行锁机制。当启用该功能时,DB2可以对未提交的插入(INSERT)或更新(UPDATE)数据进行谓词判断,如果未提交数据不符合该条语句的谓词判断条件,DB2将不对未提交数据加锁,这样就避免了因为要对未提交数据加锁而引起的锁等待状态,提高了应用程序访问的并发性。同时DB2会无条件忽略在进行表扫描时删除的行数据(不管是否提交)。
默认值:NO
是否可以联机配置:否
设置指引:这个参数建议生产数据库上配置成 ON,需要重启实例才能生效。
从 DB2 命令窗口输入 db2set DB2_EVALUNCOMMITTED 命令:
db2set DB2_EVALUNCOMMITTED=ON
db2stop force
db2start
V9.7及之后的版本,在CS隔离级别,该参数的功能被CUR_COMMIT=ON覆盖。
3.2.2、DB2_SKIPINSERTED
定义:DB2_SKIPINSERTED注册变量控制对于使用游标稳定性(CS)或读稳定性(RS)隔离级别的语句,是否可以忽略未落实的数据插入。
默认值:OFF
是否可以联机配置:否
设置指引:根据DB2_SKIPINSERTED注册变量的值不同,将以两种方式中的一种来处理未落实的插入。如果值为ON,DB2将把未提交的INSERT(只对于CS和RS隔离级别)看做它们还没有被插入,这在许多情况下能够提高并行性,并且是大多数应用程序的首选行为。未落实的插入被视为尚未发生。
如果值为OFF(默认值),DB2服务器将等待插入操作完成(落实或回滚),然后相应地处理数据。
建议在生产数据库上配置成ON。从DB2命令窗口输入db2set DB2_SKIPINSERTED
命令:
db2set DB2_SKIPINSERTED=ON
db2stop force
db2start
V9.7及之后的版本,在CS隔离级别,该参数的功能被CUR_COMMIT=ON覆盖。
3.2.3、cur_commit
定义:cur_commit(当前已落实)是DB2 V9.7中引入的DBCFG参数,在先前版本中,CS隔离级别会阻止应用程序读取其他应用程序更改过的任何行,直到更改已落实。在DB2 V9.7中,在CS隔离级别下,启用当前已落实的语义之后,读操作不必等待行更改落实即可返回值,尽可能返回当前已落实的结果,大大提高了并发性
默认值:ON
是否可以联机配置:否
设置指引:建议保持默认设置就可以。需要提醒的一点是,如果DB2数据库是从9.5升级到9.7版本,在数据库升级期间,cur_commit配置参数将设置为DISABLED,需要升级后手工更改成ON。
3.2.4、Locktimeout
定义:此参数指定应用程序为获取锁定将等待的秒数,以帮助避免应用程序出现全局死锁。
默认值:-1[-1;0-32767]
是否可以联机配置:否
设置指引:如果锁定请求处于暂挂的时间大于locktimeout值,那么请求应用程序将接收到错误并将其事务回滚。locktimeout的默认值为–1,可以关闭锁定超时检测,如果出现锁等待,应用程序将会出现无穷等待现象。
对于生产系统中的OLTP大约为60秒比较好。对于开发环境,应该使用60并部署锁时间监视器以解决锁相关的情况。如果有大量的并发用户,可能需要增加locktimeout时间以避免回滚。
3.2.5、Locklist
定义:此参数指示分配给锁定列表的内存量。每个数据库都有一个锁定列表,锁定列表包含
由同时连接至数据库的所有应用程序挂起的锁定。
默认值:automatic[4-134217728][16K-512G]
是否可以联机配置:是
设置指引:应用程序使用的锁定列表百分比达到maxlocks时,数据库管理器就会对应用程序挂起的锁定执行从行到表的锁定升级。虽然升级过程本身花不了多少时间,但是锁定整个表(与个别行比较)降低了并行性,并且可能因对受影响的表进行后续访问而降低整个数据库性能。如果锁定升级导致性能问题,那么可能需要增大此参数或maxlocks参数的值。可以使用数据库系统监视器来确定是否正在发生锁定升级。
建议使用默认值automatic,当LOCKLIST启动自动后,其大小不能超过DATABASE_MEMORY的20%,DATABASE_MEMORY不超过instance_memory,instance_memory(75%-95%物理内存)。

3.2.6、maxlocks
定义:此参数定义应用程序挂起的锁定列表的百分比,必须在数据库管理器执行锁定升级之前填写该列表。
默认值:automatic[1-100]
是否可以联机配置:是
设置指引:maxlocks是与locklist参数一起调整的,建议使用默认值。
建议使用默认值automatic,并根据实际情况调整大小。
3.3 日志
3.3.1、DB2_LOGGER_NON_BUFFERED_IO
定义:此变量将在日志文件系统上启用直接I/O。
默认值:默认开启,在默认情况下主日志文件和辅助日志文件使用非缓冲I/O。
是否可以联机配置:否
设置指引:建议该参数设置为ON。
从DB2命令窗口输入db2set DB2_LOGGER_NON_BUFFERED_IO命令:
db2set DB2_LOGGER_NON_BUFFERED_IO=ON。
3.3.2、logarchmeth1
定义:此参数指定已归档日志的主要目标的介质类型。
默认值:OFF[LOGRETAIN,USEREXIT,DISK,TSM,VENDOR]
是否可以联机配置:是
设置指引:交易系统必须启用归档设置。
3.3.3、logbufsz
定义:LOGBUFSZ参数指定将日志记录写到磁盘之前的缓冲区的大小。对日志记录进行缓冲,会减少日志记录写入磁盘的频度,从而减少了I/O操作数。
默认值:64 位 256 [4 - 131070 ][16k-512M]
是否可以联机配置:否
设置指引:数据库写日志先写在这个内存中,如果没有写满,每秒自动刷新一次,内存用满也会刷新一次,最好不要让它被用满而被迫写到磁盘。当下列事件之一发生时会将日志记录写到磁盘:
● 事务提交。
● 日志缓冲区已满或 1 秒钟。
● 其他某个内部数据库管理器事件发生。
一个理想情况应该是,读取日志页的数量为0,而有非常多的写日志的页,当有很多的日志页需要读取时,LOGBUFSZ值就需要相应地调大,通过数据库快照,发现
Log pages read = 5006
Number log buffer full = 1133464
建议增加该参数的值,尽量让"Log pages read"接近0。建议logbufsz的值修改为8192,修改命令为:db2 update db cfg using LOGBUFSZ 8192。
补充:Log pages read,是指从磁盘读取活动日志、甚至归档日志到日志缓冲池供数据库活动使用,表现在如下几个方面:
回滚、前滚、崩溃恢复需要把日志从日志文件读到日志缓冲池进行前滚和回滚操作;
CUR_COMMIT=ON的数据库(V9.7及之后的数据库版本):当一个事务更新了某个表的某条记录,事务迟迟不提交,其他事务读该记录时,将会出日志缓冲区读;如果因为日志缓冲区满或者时间过了1S,那就要去活动日志读,如果活动日志对应的文件已满,则会复制到归档日志目录下,但仍然是从活动日志路径读该日志条目到缓冲池。所以,如果日志缓冲池过小的话,将会频繁出现因为CUR_COMMIT的原因,把日志条目从磁盘读回到日志缓冲池中,这跟数据缓冲池小引起数据页反复物理读的现象一样,影响性能,所以当Log pages read过多时,就需要增加LOGBUFSZ的值。
DBHEAP数据库堆,包含日志缓冲区(LOGBUFSZ)、实用程序(主要是事件监控程序)和表/索引/表空间/缓冲池的控制块信息。在数据库启动时分配,按需扩展内存量,直到达到所配置的上限。
通过数据库快照,发现:
Memory Pool Type = Database Heap
Current size (bytes) = 12648448
High water mark (bytes) = 14401536
Configured size (bytes) = 27869184
可以看出,DBHEAP高水位的值离配置的值还有一段距离,所以该配置的值是合适的。但因为上面修改了LOGBUFSZ参数,所以需要同时修改dbheap,因为logbufsz使用的空间由dbheap参数控制。建议dbheap的值修改为automatic(10000)。修改命令为:db2 update db cfg using dbheap 10000 automatic。
3.3.4、Logfilsiz
默认值:1000[4-1048572][16k-4G]
是否可以联机配置:否
建议值:100M
3.3.5、Logprimary
默认值:3[2-256]
是否可以联机配置:否
建议值:30
在10.1版本中,活动日志大小为(LOGPRIMARY+LOGSECOND)*LOGFILSIZ,其中日志个数的值必须小于或等于256,logfilsiz的最大为1048572,即4G,所以活动日志最大已经可以达到1024G。主日志在第一个连接到达数据库或者数据库被激活后立即分配,而辅助日志在主日志大小不够的时候动态分配。
3.3.6、Logsecond
默认值:2[-1;0-254]
是否可以联机配置:是
建议值:170
3.3.7、Newlogpath
定义:更改存储活动日志文件的位置,路径最大长度为242个字节。
3.4 IO
3.4.1、MAXFILOP
Maximum Total of Files Open,这个参数指定每个数据库代理所能打开的最大文件数(或者认为: 服务器打开文件的最大数目)。如果打开一个文件时被打开的文件数超出了这个值,则要关闭该代理正在使用的一些文件。不断地打开和关闭文件减缓了 SQL 响应时间并耗费了 CPU 周期。文件包括SMS和DMS表空间容器中的文件(如果使用SMS容器,要求该值比较高,也需要检查操作系统对该值的限制)。
通过数据库快照,发现Database files closed= 1584。
建议增加该参数的值,直到快照监控输出为0。建议MAXFILOP的值修改为默认值61440,修改命令为:db2 update db cfg using MAXFILOP 61440。
3.4.2、更改页阈值(CHNGPGS_THRESH)
当缓冲池中的被修改的数据页(脏页)与缓冲池总大小的比例超过一定阀值的时候(chngpgs_thresh),DB2就会触发后台的页面清除进程/线程,将被选择的页(victim pages)以异步方式物理写入磁盘。OLTP系统建议值为60。
案例:脏页偷取(dirty page steal)
来源:数据库快照
公式:脏页偷取触发次数(Dirty page steal cleaner triggers)
指标:非常低
描述:脏页偷取是一种对性能影响极大的操作。当系统中的脏页偷取过多的时候,意味着需要让页清除器工作得更加卖力。
如果发现系统中的页清除器一直很空闲,则可以通过调节softmax 与 chngpgs_thresh 来让它们忙起来。这两个参数都是控制何时触发页清除器的参数,其中 softmax 是按照缓冲池中 MinbuffLSN 与当前 LSN 之间的差距来计算何时需要触发,而chngpgs_thresh 则是计算缓冲池中脏页的数量与可用页面总数来进行计算。两者的作用同样都是触发页清除器,只不过从不同的角度计算而已。
但是如果通过db2pd -stack all 抓取的stack 发现所有的页清除器一直非常繁忙,但是无论如何刷新磁盘的速度也赶不上数据写入缓冲区的速度,这时就需要增加页清除器的数量了。
分析:
Dirty page steal cleaner triggers = 88831
LSN Gap cleaner triggers = 837134
Dirty page threshold cleaner triggers = 28238
数据库参数:
CHNGPGS_THRESH= 80
NUM_IOCLEANERS = AUTOMATIC(12)
SOFTMAX=520
建议:
NUM_IOCLEANERS = AUTOMATIC(12),表示页清除器可以按需分配,数量充足。
Dirty page steal cleaner triggers= 88831,数值很高,表示页清除器工作的不充分,已经严重影响了数据库的缓冲池读性能,这种工作的不充分是受参数CHNGPGS_THRESH、SOFTMAX影响的,SOFTMAX超过阈值发生了837134,CHNGPGS_THRESH超过阈值发生了28238次,对比发现,有必要调整CHNGPGS_THRESH,由当前的80调整到50。语句为:
db2 update db cfg using CHNGPGS_THRESH 50
需要重启数据库。
3.4.3、异步页清除程序的数目(NUM_IOCLEANERS)
这个参数指定数据库的异步页清除程序的数目,在数据库代理程序需要缓冲池中的空间之前,这些页清除程序将缓冲池中已更改的页写到磁盘,这允许代理程序不必等待已更改页被写到磁盘就可以读取新页,这样会加快应用程序事务的运行。
通过数据库快照,发现
Dirty page steal cleaner triggers= 11549,这意味着有11549次需要代理程序自身把数据页从缓冲池写到磁盘。
建议增大NUM_IOCLEANERS的值,使"Dirty page steal cleaner triggers"尽量小。建议NUM_IOCLEANERS的值修改为automatic(12),修改命令为:
db2 update db cfg using NUM_IOCLEANERS 12 automatic。
案例、数据、索引页清除
来源:数据库快照
公式:异步写入/总写入(async writes/total writes)
指标:≥95%
描述:该指标代表着页面清除线程是否能够有效地将脏页在后台刷入磁盘。由于缓冲池的大小是有限的,一般来说数据库不可能把所有的数据都放入内存。这时,哪些数据需要驻留内存,哪些被更新的数据需要被写入磁盘,然后留出空间给其他数据,就是 DB2缓冲池管理模块需要决定的。当缓冲池中的被修改的数据页(脏页)与缓冲池总大小的比例超过一定阈值的时候(chngpgs_thresh),DB2就会触发后台的页面清除线程,将被选择的页(victim pages)以异步方式物理写入磁盘。但是如果该清除机制触发得不够频繁,或者缓冲池太小使得系统无法有效地找到一个干净的页面,DB2 就会选择一个脏页,将它写入磁盘,然后读取另外一个页面进入内存,这种写入方式叫做同步写入。可以想象,相对异步写入,同步写入会对数据的读取造成很大的性能问题。因而,该指标的用途就是监测异步写入与总写入的比例。
分析:
Asynchronous pool data page writes = 15820385
Asynchronous pool index page writes = 18512169
Buffer pool data writes = 16141488
Buffer pool index writes = 18906035
指标值=(15820385+18512169)/(16141488+18906035)=34332554/35047523=97.96%
建议:
无
3.4.4、IO服务器的数目(NUM_IOSERVERS)
诸如备份和恢复之类的实用程序使用I/O服务器代表数据库代理程序执行预取I/O和异步I/O操作。该参数是数据库配置参数,用于指定数据库的I/O服务器的数目。超过这个数量的预取和实用程序I/O在任何时候都不能在数据库中执行。I/O服务器用于执行预取操作,此参数则指定数据库中I/O服务器的最多数量。非预取I/O是从数据库代理调度的,因此不受此参数的约束。建议值大于磁盘数量,小于CPU数量的4到6倍。
当前值
NUM_IOSERVERS = 3
建议值
NUM_IOSERVERS = 6
数据库快照信息:
Time waited for prefetch (ms) = 231431333(等待预取的时间)
Time waited for prefetch(等待预取的时间),预取操作需要NUM_IOSERVERS在后台异步的执行,如果等待预取的时间过长,则很有可能是因为预取线程个数,需对um_ioservers参数进行调整。
AVG_APPLS
Average Number of Active Applications,一般设置为AUTOMATIC(1),由数据库管理器根据当前并发执行的应用程序数进行自动调整
DB2优化器根据这个参数来评估资源的使用策略,特别是缓冲池空间。
4调整数据库参数案例
附件《dbcheck.sh》是数据库巡检脚本。
附件《数据库性能检查.pdf》是根据数据库巡检脚本获取的信息给出的数据库建议优化方案。
文章word版及附件共享地址:
https://pan.baidu.com/s/1i5CfLkT
供稿 | 黄海 编辑 | lin

