





Orchestrator是一个对MySQL复制提供高可用、拓扑、管理和可视化的工具,它能够主动发现当前拓扑结构和主从复制状态,也可以重构当前的拓扑结构,识别各种故障并自动恢复。
但它最难的还是发音:OK丝翠特儿
Orchestrator 默认只提供MySQL主从复制的拓扑管理。在发生故障转移时,会重新组织拓扑,选出新主库并指定其他从库连接到它。但Orch自身不会进行任何DNS更改或VIP漂移。切换后,应用程序可能连接到错误的数据库,那么是否可以按照MHA+VIP类似的方式,来使用Orchestrator呢?

想象中的美好秩序

现实生活无情暴击
Hooks: Orchestrator为此提供了Hooks。(可以恢复过程中调用的外部脚本)
有很多种不同的Hooks:
OnFailureDetectionProcessesPreFailoverProcessesPostIntermediateMasterFailoverProcessesPostMasterFailoverProcessesPostFailoverProcessesPostUnsuccessfulFailoverProcesses
通过这些Hooks,我们可以根据当前的架构来定义、调用自己的外部脚本,让应用找到新的Master。
今天内容主要有3部分:
1. 测试环境准备
2. Orch VIP方式切换配置
3. 各种测试切换:
-无负载下的切换
-只读场景下的切换
-读写场景下的切换(Switchover、Failover)
原计划是分3篇来发,但这周 小万能修
 幼儿园开学有些忙,干脆合在一起发完拉倒。来一段噼里啪啦的弹棉提提神。
幼儿园开学有些忙,干脆合在一起发完拉倒。来一段噼里啪啦的弹棉提提神。车还是要有的,今天是稳稳的公交车,小朋友们请在4名工作人员的引导下有序上车,扶稳坐好,愉快的旅程开始了。

为艺术献身的马赛克
1. 测试环境准备
# 数据库环境配置
准备3台测试数据库:末三位IP:169、170、171。
对外提供服务的VIP:172
数据库版本5.7.22
参数按一般生产级别配置即可
binlog_format = ROWtransaction-isolation = READ-COMMITTEsync_binlog = 1innodb_flush_log_at_trx_commit = 1innodb_support_xa = 1log_slave_updates=1relay_log_recover = 1relay_log_info_repository = TABLEmaster_info_repository = TABLE
# 3台数据库已经在Orch中发现

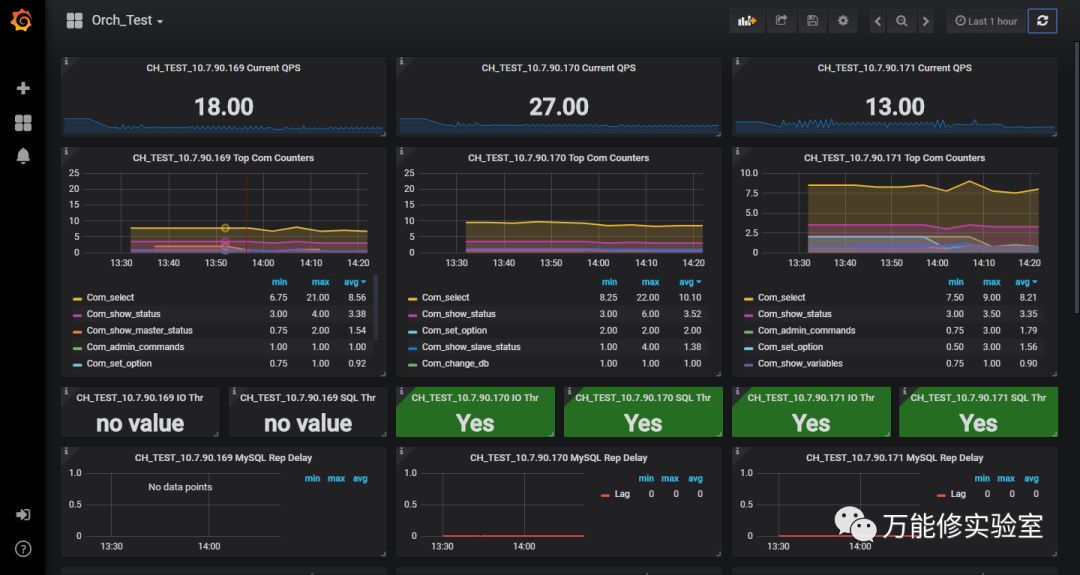
# 为了方便,监控指标我都集中做在一个PMM面板中(3台DB对应3列)。
数据库主要关注QPS,各种com值、主从延迟。
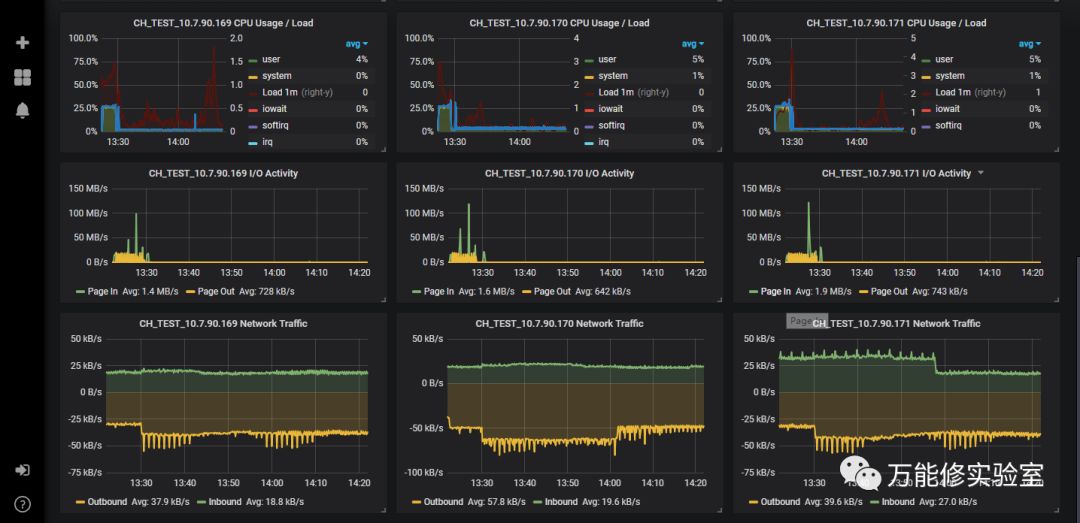
操作系统主要监控了CPU、IO、网络。
2. Orch VIP方式的切换配置
2.1 数据库端配置:
# 三个数据库服务器上分别建立用户
@db1,@db2,@db3
useradd -m orchestrator -s bin/bash密码:pass orchestrator
# 设置sudo
vi etc/sudoers.d/orchestratorDefaults !requirettyorchestrator ALL=(ALL) NOPASSWD: /usr/sbin/arping,/sbin/ip,/bin/ping
chmod 0440 etc/sudoers.d/orchestrator
# 在当前的主库db1上绑定VIP:
@ db 1(master)添加vip:
ip address add 10.7.90.172/24 dev eth1
删除vip:
ip address del 10.7.90.172/24 dev eth1
2.2 Orch Server端配置:
# 建立ssh用户:
useradd -m orchestrator -s bin/bash[root@localhost ~]# su - orchestrator[orchestrator@localhost ~]$ ssh-keygen -t rsa -P ''Generating public/private rsa key pair.Enter file in which to save the key (/home/orchestrator/.ssh/id_rsa):Created directory '/home/orchestrator/.ssh'.Your identification has been saved in home/orchestrator/.ssh/id_rsa.Your public key has been saved in home/orchestrator/.ssh/id_rsa.pub.The key fingerprint is:SHA256:VikBGtkQUMcjBXVbIS1AiCQny4Qamhzyb8uF5aguhDM orchestrator@localhost.localdomainThe key s randomart image is:+---[RSA 2048]----+|+o++*%Bo+.o. ||**. +++..=.. ||*=. .. .o.o ||+.. . o ||. . = S ||E. = o. ||.o + o ||. . o || o. |+----[SHA256]-----+
# 分发秘钥到各个数据库:
cd home/orchestrator/ssh-copy-id -i ~/.ssh/id_rsa.pub orchestrator@10.7.90.169ssh-copy-id -i ~/.ssh/id_rsa.pub orchestrator@10.7.90.170ssh-copy-id -i ~/.ssh/id_rsa.pub orchestrator@10.7.90.171
# 测试到3个数据库的免密码连通:
ssh 10.7.90.169 hostnamessh 10.7.90.170 hostnamessh 10.7.90.171 hostname
# 在配置文件中PostMasterFailoverProcesses加入vip修改的脚本
vi etc/orchestrator.conf.json"PostMasterFailoverProcesses": ["sudo -u orchestrator usr/local/orchestrator/failover.sh {failureType} {failureClusterAlias} {failedHost} {successorHost} >> tmp/orc_failover.log"],
# 脚本内容和日志内容可以自行修改
#!/bin/bashoriginal_master=$3new_master=$4ssh_user=orchestratorvip_eth=eth1vip=10.7.90.172vip_mask=24echo "Down VIP on $original_master"ssh -o ConnectTimeout=5 -o StrictHostKeyChecking=no $ssh_user@$original_master "sudo -n sbin/ip address delete $vip/$vip_mask dev $vip_eth"echo "Up VIP on $new_master"ssh -oStrictHostKeyChecking=no $ssh_user@$new_master "sudo -n sbin/ip address add $vip/$vip_mask dev $vip_eth"echo "Refresh arp"ssh -oStrictHostKeyChecking=no $ssh_user@$new_master "sudo sbin/arping -q -c 3 -A $vip -I $vip_eth"
3. 测试切换
3.1 测试-1:无负载下的切换:
# 在3台数据库上确认vip(172)只绑定在169上:
# DB1上检查(VIP目前在DB1上):[root@mysql1 mysql]# ip addr|grep "10.7.90."inet 10.7.90.169/24 brd 10.7.90.255 scope global eth1inet 10.7.90.172/24 scope global secondary eth1 <---- VIP# DB2上检查:[root@slave1 mysql]# ip addr|grep "10.7.90."inet 10.7.90.170/24 brd 10.7.90.255 scope global eth1# DB3上检查:[root@slave2 mysql]# ip addr|grep "10.7.90."inet 10.7.90.171/24 brd 10.7.90.255 scope global eth1
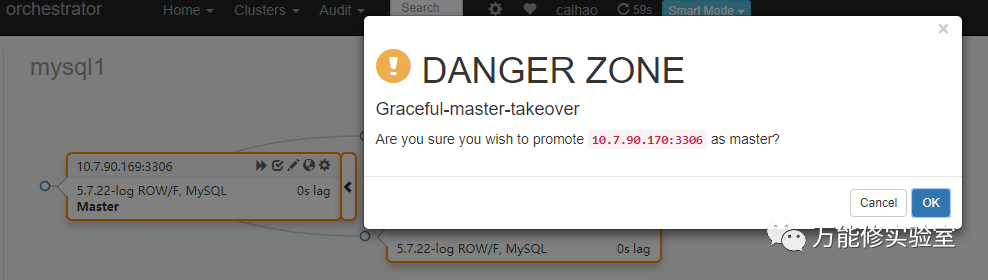
# 提升170 为主库
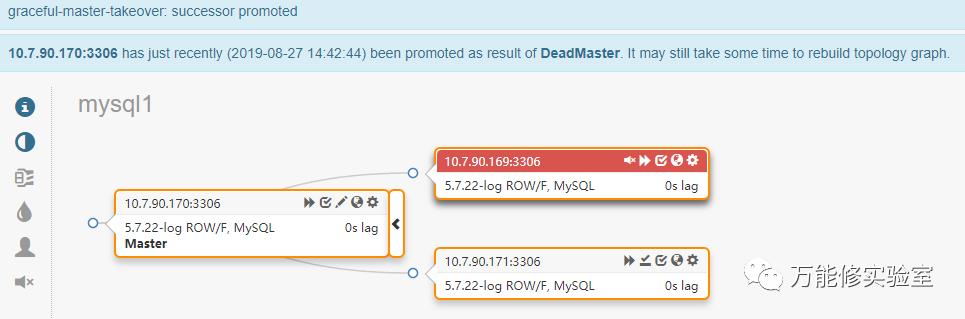
# 确认切换结果
# 注意默认的原master同步是未启动用,手动start slave
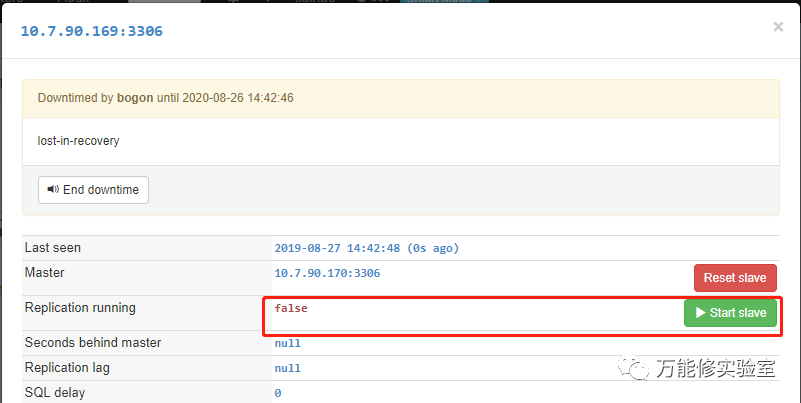
# 启动后已同步恢复正常
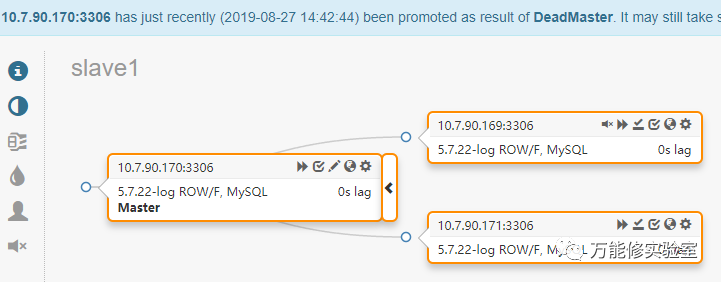
# 监控也可以看到,170的IO和SQL线程已关闭
# 再检查VIP,已妥妥儿的绑定到新主库 170上
# DB1上检查:[root@mysql1 mysql]# ip addr|grep "10.7.90."inet 10.7.90.169/24 brd 10.7.90.255 scope global eth1# DB2上检查(VIP已切换到DB2):[root@slave1 mysql]# ip addr|grep "10.7.90."inet 10.7.90.170/24 brd 10.7.90.255 scope global eth1inet 10.7.90.172/24 scope global secondary eth1 <---- VIP# DB3上检查:[root@slave2 mysql]# ip addr|grep "10.7.90."inet 10.7.90.171/24 brd 10.7.90.255 scope global eth1
# 切换日志上的内容:
---------------------------------------2019-08-27-13-14-29: Down VIP 10.7.90.172 eth1 24 on Original Master 10.7.90.1692019-08-27-13-14-29: Up VIP 10.7.90.172 eth1 24 on New Master 10.7.90.1702019-08-27-13-14-29: Refresh arp on New Master 10.7.90.170---------------------------------------
3.2 测试-2:只读场景下的切换
# 使用sysbench模拟只读业务,针对vip 172压测
[root@mysql2 ~]# cat sb_configmysql-host=10.7.90.172mysql-port=3306mysql-user=sbtestmysql-password=*******mysql-db=sbtesttime=300threads=16report-interval=5db-driver=mysql
# 综合只读查询(包含范围查询、sum、order by 和 distinct):
sysbench --config-file=sb_config oltp_read_only --tables=32 --table-size=100000 run
# 压测一段时间,已经可以看到各个指标明显变化。

# sysbench此时是这样的
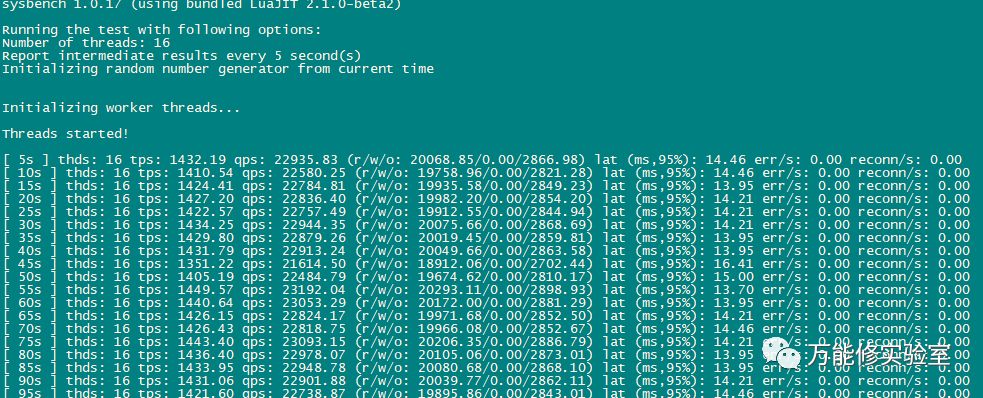
# 切换主库,由170 切换到 171
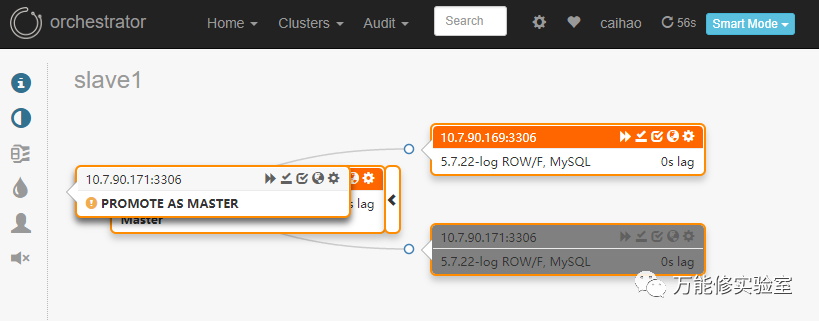
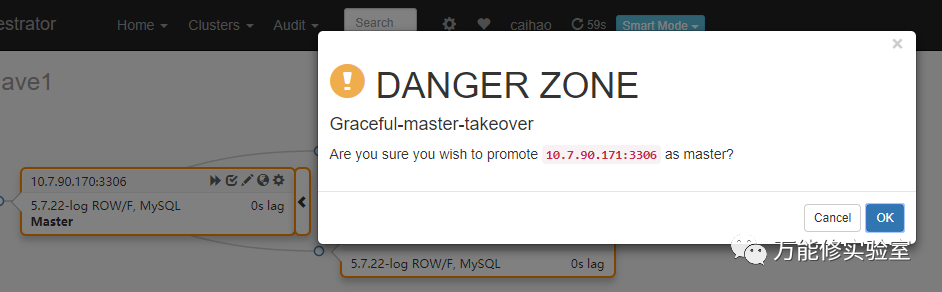
# 171此时:我好了
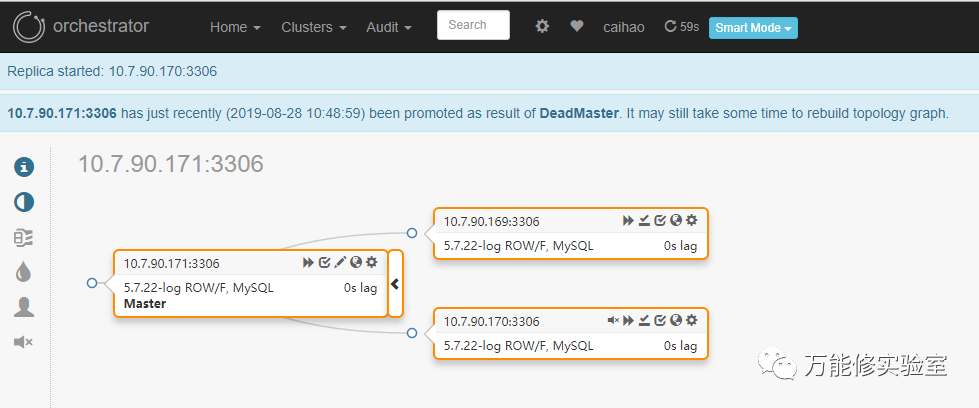
# sysbench此时:我TM挂了
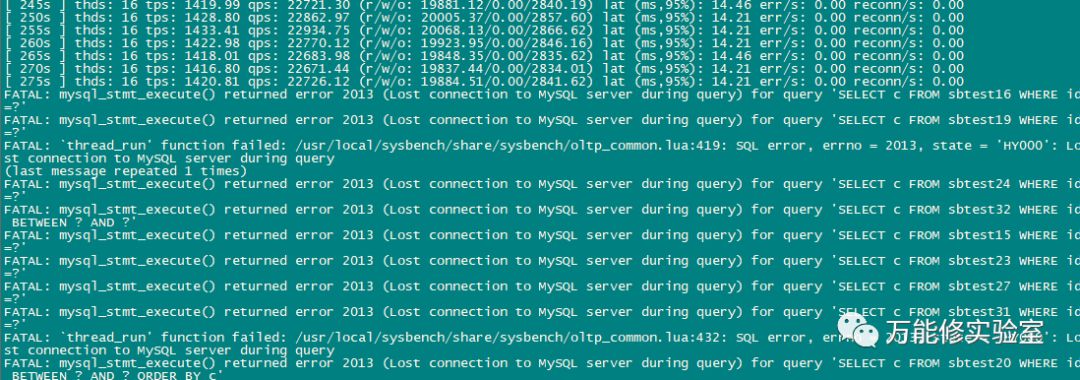
# 再检查VIP,绑定到新主库 171上
# DB1上检查:[root@mysql1 ~]# ip addr|grep "10.7.90."inet 10.7.90.169/24 brd 10.7.90.255 scope global eth1# DB2上检查:[root@slave1 ~]# ip addr|grep "10.7.90."inet 10.7.90.170/24 brd 10.7.90.255 scope global eth1# DB3上检查(VIP已切换到DB3):[root@slave2 ~]# ip addr|grep "10.7.90."inet 10.7.90.171/24 brd 10.7.90.255 scope global eth1inet 10.7.90.172/24 scope global secondary eth1 <---- VIP
# 切换日志上的内容:
---------------------------------------2019-08-28-10-48-58: Down VIP 10.7.90.172 eth1 24 on Original Master 10.7.90.1702019-08-28-10-48-58: Up VIP 10.7.90.172 eth1 24 on New Master 10.7.90.1712019-08-28-10-48-58: Refresh arp on New Master 10.7.90.171
3.3 测试-3:读写场景下的切换(Switchover)
# 综合读写测试 oltp_read_write
sysbench --config-file=sb_config oltp_read_write --tables=32 --table-size=100000 run
# 为防止压力过大主从延迟只开了2个线程
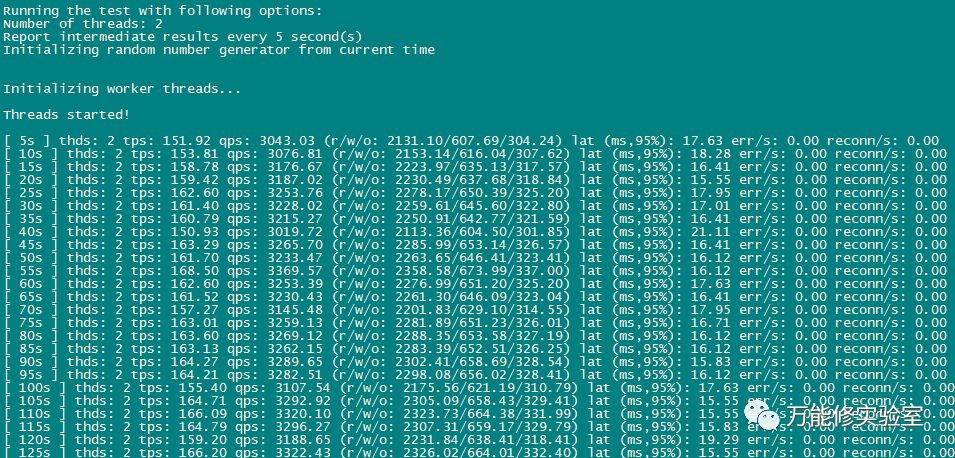
# 压测一段时间,各个指标变化,注意从库已经有1秒的延迟。
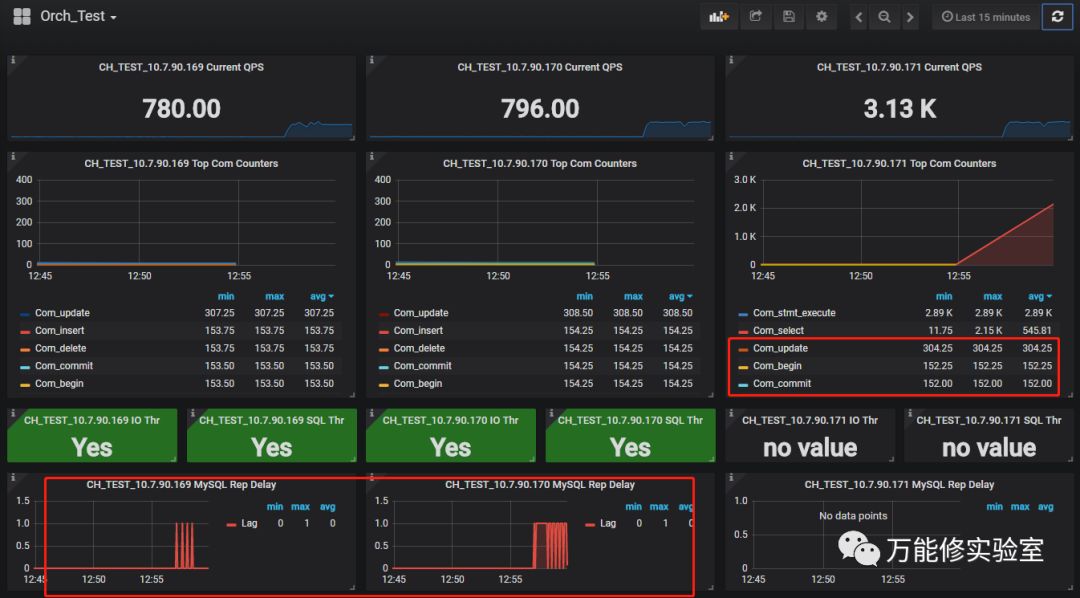
# 切换主库,由171 切换到 169
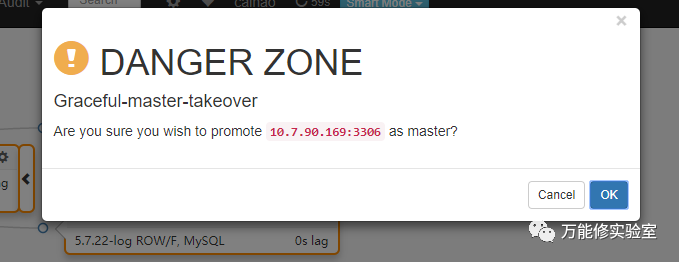
# 切换完成,169已提升为主库。 *注意原主库171上面有个红色的提示
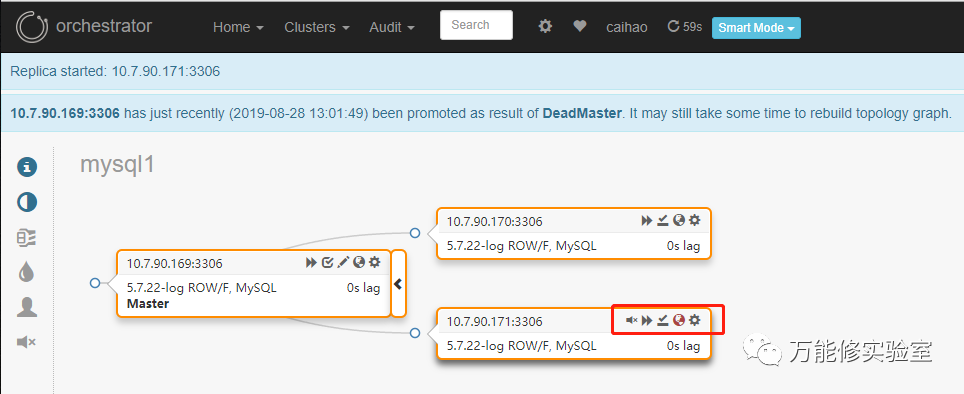
# sysbench此时:又TM挂了

# 检查VIP已绑定到新主库 169上
# DB1上检查(VIP已切换到DB1):[root@mysql1 ~]# ip addr|grep "10.7.90."inet 10.7.90.169/24 brd 10.7.90.255 scope global eth1inet 10.7.90.172/24 scope global secondary eth1 <----VIP# DB2上检查:[root@slave1 ~]# ip addr|grep "10.7.90."inet 10.7.90.170/24 brd 10.7.90.255 scope global eth1# DB3上检查:[root@slave2 ~]# ip addr|grep "10.7.90."inet 10.7.90.171/24 brd 10.7.90.255 scope global eth1
# 切换日志上的内容
---------------------------------------2019-08-28-13-01-47: Down VIP 10.7.90.172 eth1 24 on Original Master 10.7.90.1712019-08-28-13-01-47: Up VIP 10.7.90.172 eth1 24 on New Master 10.7.90.1692019-08-28-13-01-48: Refresh arp on New Master 10.7.90.169
# 根据右边的提示,这问题是由于切换过程中有一些事物没有同步到从库导致。
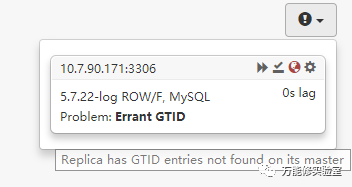
# Orch自身提供了修复方案:在该节点reset master清除对应的GTID
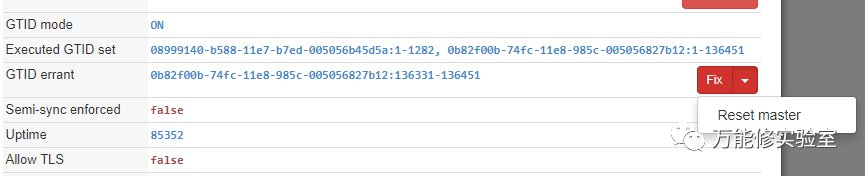
# 执行后,状态恢复正常。
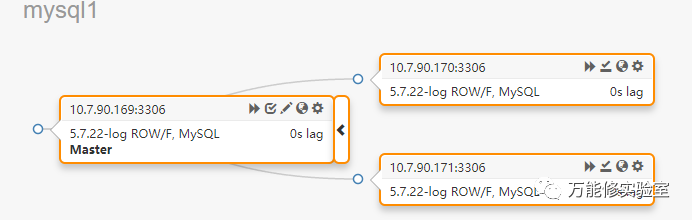
# 但实际上这里有一个坑:因为此时是手动切换(类似Oracle DG的Switchover),即主库正常的情况下切换vip到备库,切换过程中原主库并没有真正故障,有短暂时间是可以写入数据的,可能导致切换后主从不一致。这里使用pt-table-checksum工具进行分析,可以看到很多主从不一致的数据,要手动使用pt-table-sync 才能修复。
这个问题估计可以调用其他Hooks来解决。
3.3 测试-4:读写场景下的切换(Failover)
模拟master意外中断,测试Orch能否自动切换到最合适的slave,并绑定vip
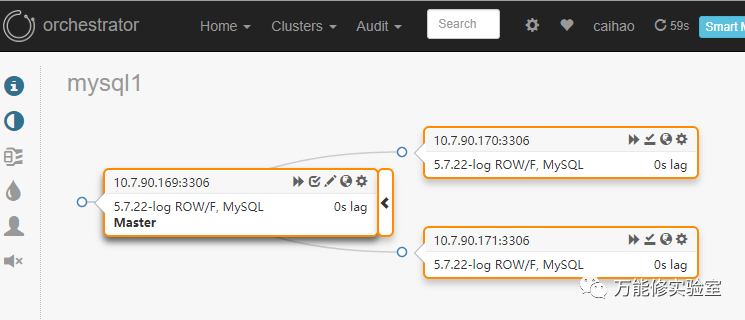
# 当前拓扑 主库:169
# 读写混合走起
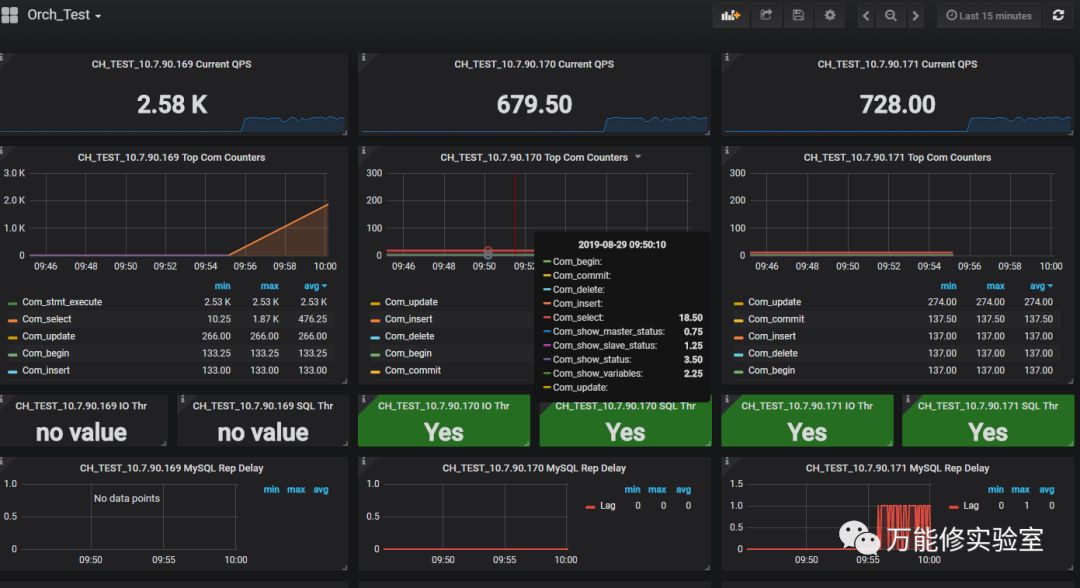
# 确认数据已写入
# 在当前主库169上找到mysqld_safe和mysqld ,直接kill

# Orch发起了故障转移,提升171为新master
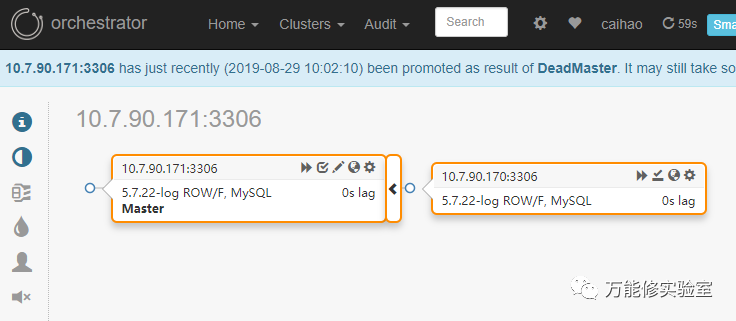
# 原主库169已经被踢出集群
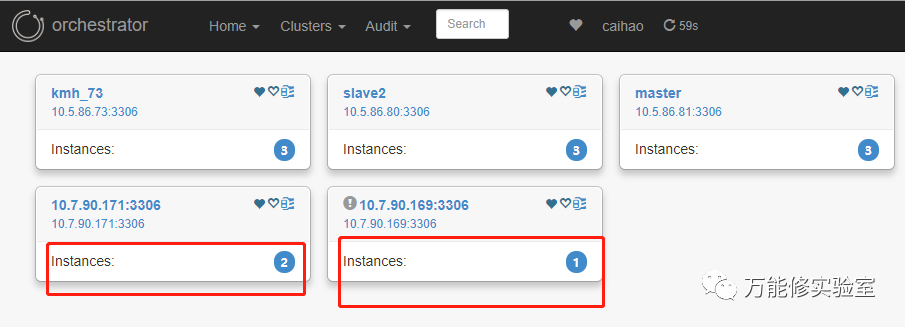
# 检查VIP已绑定到新主库 171上
[root@mysql1 ~]# ip addr|grep "10.7.90."inet 10.7.90.169/24 brd 10.7.90.255 scope global eth1[root@slave1 ~]# ip addr|grep "10.7.90."inet 10.7.90.170/24 brd 10.7.90.255 scope global eth1[root@slave2 ~]# ip addr|grep "10.7.90."inet 10.7.90.171/24 brd 10.7.90.255 scope global eth1inet 10.7.90.172/24 scope global secondary eth1 <----VIP
# 原主库169要重新CHANGE MASTER加入新拓扑中
[root@localhost][(none)]> show slave status\GEmpty set (0.00 sec)[root@localhost][(none)]> CHANGE MASTER TO MASTER_HOST='10.7.90.171', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='***', MASTER_PASSWORD='****';Query OK, 0 rows affected, 2 warnings (0.04 sec)[root@localhost][(none)]> start slave;Query OK, 0 rows affected (0.09 sec)[root@localhost][(none)]> show slave status\G*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 10.7.90.171Master_User: replMaster_Port: 3306Connect_Retry: 60Master_Log_File:Read_Master_Log_Pos: 4Relay_Log_File: relay.000001Relay_Log_Pos: 4Relay_Master_Log_File:Slave_IO_Running: YesSlave_SQL_Running: Yes.略.
# 检查最新拓扑
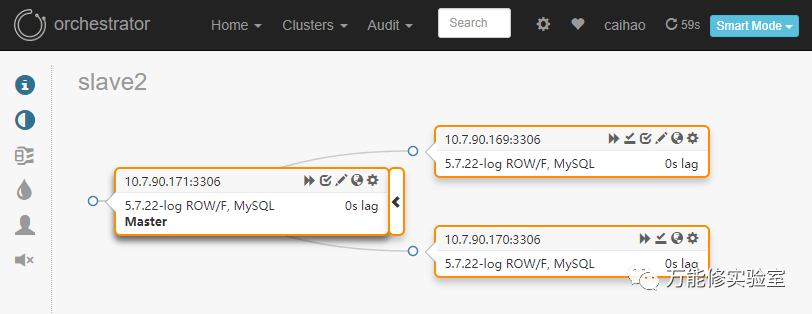
# 由于是主库故障导致的切换,Failover期间无数据修改,无损半同步能够最大限度保证binlog发送到slave。
用pt-table-checksum检查主从一致性也没啥问题。

Orch的VIP方案简单总结下:
部署简单,基本上额外准备一个脚本就可以完成切换功能
对于应用来说只暴露一个IP,无需调整
由于访问DB不借助中间件,性能无损耗
依赖MySQL原生复制,服务器故障发生时即使有增强半同步仍可能丢数据,要做好日志补回机制
由于sysbench本身没有重连机制,测试切换的过程中会中断,有条件的还是建议用实际应用程序做测试。
下一篇文章中将继续探讨Orch的其他玩法,比如前端加个ProxySQL代理。
