




2019年8月24日,PostgreSQL中文社区第一次携手腾讯TBase在深圳举办数据库行业技术交流会,来自线上线下超过500名开发者一起畅谈数据库相关技术。百度NewSQL数据库研发工程师许泽敏受邀在大会上进行了主题为《CockroachDB高可用最佳实践方案》的技术分享,介绍了CockroachDB的高可用特性,包括多副本一致性、Replication Zones、灾备恢复能力以及基于这些特性构建的高可用部署方案。

以下是分享的内容,主要包括:CockroachDB高可用特性、最佳实践、灾备恢复和未来展望。
高可用特性
在原始的单机数据库中,通常只有一个节点可以提供服务,如果该节点故障了,不仅服务不可用,还存在丢失数据的风险。为了提高稳定性,衍生出了Active-Passive的模式,通过不同方式把数据同步到Slave节点上,来为Master节点提供冷备或者热备份,当Master节点故障时可以把服务切换到Slave节点来继续提供服务。这种模式提供了一定的容灾能力,但是容灾程度有限,可扩展性较差。
随着业务规模增大,单节点难以满足需求,衍生出了Sharding的模式。用户根据某些字段,把数据切分成不同分片,每个分片都是独立的Active-Passive架构,在分片前会增加一个Sharding路由模块来路由用户请求。一些业务的MongoDB集群是采用这种Sharding模式的,MySQL也有具备Sharding功能的中间件。Sharding模式把数据切片放在不同的节点上,可以扩大集群存储能力和分摊负载,但也存在一定局限性:这种架构使得维护过程变得复杂,在使用过程中分片逻辑可能会逐渐渗透到应用的业务逻辑中,如果业务逻辑变更或者其他原因需要修改分片方式,维护过程相对比较麻烦;另一方面这种模型对于事务的实现也很不友好。
CockroachDB采用的是Multi-Active的模式,集群中每个节点都可以独立提供服务,并且提供一定的容灾和自修复能力。底层的用户数据分布式存放在多个节点上,每个节点存储一部分数据,这些数据都是以多副本的形式存放在不同节点上的,节点之间通过一定的方式进行同步,保证多个副本数据的一致性。通常在集群前面会挂一层负载均衡来路由用户请求,也可以及时屏蔽故障节点。
CockroachDB底层的数据是怎么分布和存储的,又是怎么保证多个副本之间的数据一致性的?

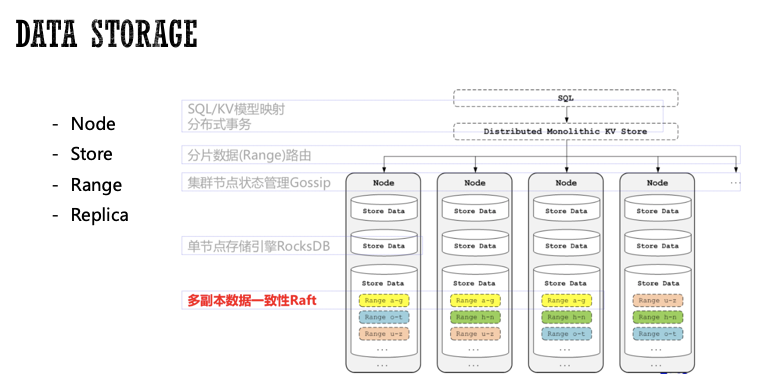
首先介绍了CockroachDB底层的数据存储形式。CockroachDB采用分层架构,最顶层是SQL层,SQL层沿用了传统关系型数据库的概念,如Scheme、Table、Column和Index。
SQL层构建于分布式KV存储之上,后者负责Range路由寻址,提供统一的KV存储。一个CockroachDB实例称为1个Node,1个Node可以有1个或多个Store。通常每个Store独占一块磁盘(建议使用SSD),对应一个RocksDB实例;每个Store包含多个Range,Range为KV层数据管理的最小单元。每个Range默认64MB,负责存储有序的KV数据集合。
每个Range默认有3个副本,分布在不同的实例上,那么这里存在一个问题:Range之间如何同步数据?如何保证数据一致性?
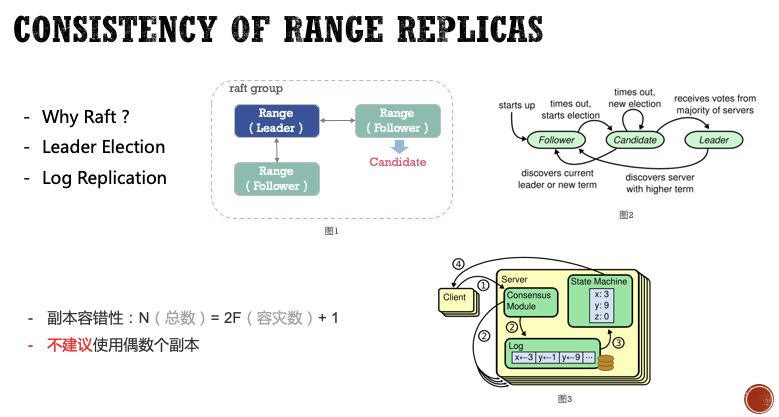
CockroachDB是通过Raft协议保证数据多副本的一致性。Raft是从Paxos演化而来的,是目前分布式数据库中很常见的一致性算法。Raft使用了更简化更清晰的模型解决多副本一致性的问题。
Range的三个副本是一个Raft Group,其中一个副本是Leader,剩余的都是Follower。Raft为每个Follower设置一个随机选举超时时间,当Leader副本故障或者出现网络分区时,Follower超过该时间没有收到Heartbeat,就会自行发起选举请求,最终会选出新的Leader来继续提供服务。
在Raft group中写入一条数据,首先需要在Leader副本的Raft log中记录相关日志,然后Leader将该条LogEntry发送给所有Follower,Follower收到后会记录在本节点的Raft log中,并回复Leader;当Leader确认group中大多数节点记录了该条日志,就会Apply该条日志到本节点的State machine,并告知客户端该条数据已经成功写入;Leader会在后续的消息中通知其它Follower也把该条日志apply到State machine,从而达到数据最终一致。Raft是强一致性协议,也就是从客户端角度来看,只要接收到写入成功的回复,无论Raft group中任何节点出现故障,Raft协议都能保证Client一定能读到正确的值。从写入流程可以看出,多数副本之间的网络延迟对于数据写入性能是有一定影响的,在实际部署中应当尽量保证副本间的网络质量。
集群的副本容错性计算公式:N(总数)= 2F(容灾数)+ 1;默认3副本的部署方式,最多可以提供1个副本的容灾能力。在实际部署中,建议提高系统数据副本数量,从而提供更好的容灾能力。对于副本数量,奇数个副本的稳定性胜过偶数个副本,一般不建议配置偶数个副本,否则在出现网络分区时会有一定概率造成整体Raft group不可用的情况。
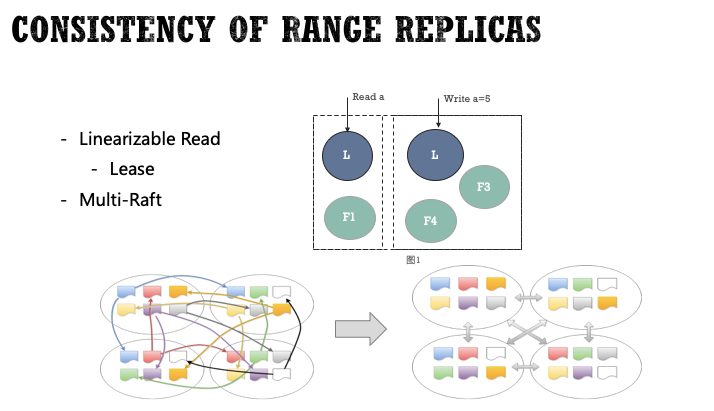
如果直接从Leader副本上读数据,在出现网络分区时,可能会出现Stale read的问题。数据库如何保证Linearizable Read?目前业界有两种常见的解决思路:
读请求需要得到大多数的认可,或者Leader在处理一个读请求前需要再次通过一轮心跳确认自己还是唯一的Leader。这是一种比较常见的做法,这种做法的一个问题是效率较低,读请求也是2 RTT的开销。
引入Lease机制。Lease是一个有时间期限的租约,由节点发起申请,同一时刻只能拥有一个Lease,持有Lease的节点称为Lease holder。所有请求首先找到Lease holder,由它转发给Leader进行处理。通常情况下,Lease基本都是由Leader节点持有,也就是同一个节点,也就避免了多一次转发的开销。
CockroachDB通过Lease机制来保证Linearizable Read。在出现网络分区情况下可能存在极短暂的Raft group不提供服务的问题。在数据库CAP理论中,这是一种典型的牺牲一定可用性,也要保障一致性的做法。
CockroachDB作为分布式数据库,每个节点可能存在成千上万个Range,如果每个Range内部独立通信,那么同一时刻在网络中会存在大量的Raft Message。CockroachDB采用Muli-Raft的优化方式来解决这个问题,基本思想就是以Node为单位聚合Message并批量发送,从而大大减轻网络传输压力。
CockroachDB还支持用户指定实际数据的位置分布。用户首先通过Locality为CockroachDB实例添加物理位置信息,然后使用Replication Zones功能来指定数据集的位置分布。在这个案例中,用户将数据库db01的所有数据都约束存在华南地区的广州01机房。
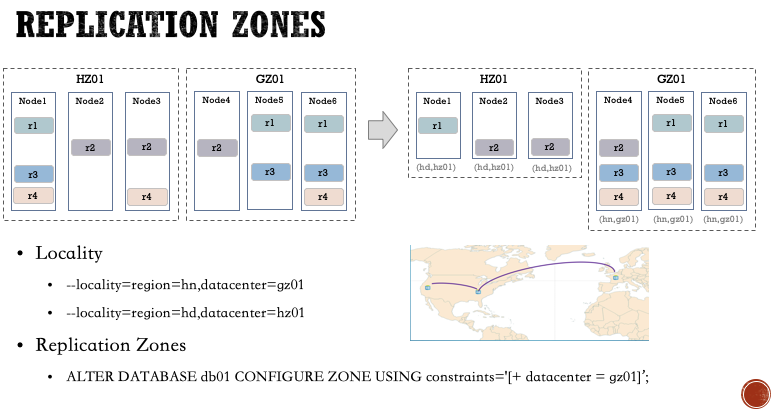
目前CockroachDB支持指定Database、Table、Rows和Secondary index级别的数据集。除了指定数据集位置信息,还支持指定副本数量等,更多功能可以查阅用户手册相关章节。
可以看出CockroachDB在功能设计上也有一些全球化部署方面的考虑。目前很多国家非常重视数据安全,例如日本和欧洲的一些国家是很忌讳把数据传出国外的,用户可以通过这个功能来控制敏感数据只存储在本地。另一方面,用户也可以通过Partition功能,在上层把业务数据进行分区,然后把某部分数据放到距离用户更近的节点上,提高访问速度。对于一些国际化业务,这是个很有用的特性,不过对于大多数中国用户来说,可能没有这方面顾虑,不过我们可以根据实际需求,利用这个特性,通过调整数据分布和副本数来构建不同的高可用集群。
最佳实践
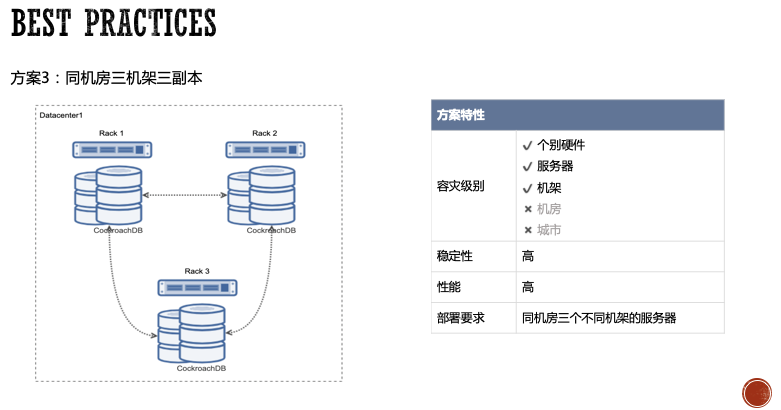
第一种方案是同城三机房三副本,在同个城市的三个不同机房部署集群,每个CockroachDB实例进行Locality配置,分为3个Datacenter,每个Datacenter配置1个副本的数据分布约束。
这种部署模式存在频繁的跨机房同步操作,为了保证数据库的性能,使用同城三机房方案对机房之间的网络延迟和网络质量有比较高的要求。在实际中,同城的机房延迟通常在1ms左右,并且CockroachDB优化了多个副本间的通信,所以在实际使用上性能表现非常不错。
这种部署方案的优势是很明显的,除了可以抵御个别硬件故障外,还可以抵御机房级别的灾难,这对于可用性要求高的用户来说,是不错的选择。不过这种部署方式需要同城三个不同机房,并且要求机房间网络质量良好,门槛相对会高很多。
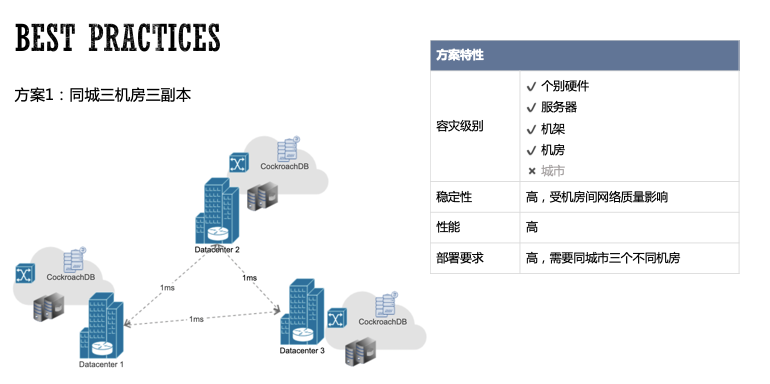
第二种方案是两地三机房部署,在主城市2个机房,副城市1个机房,每个机房配置1个副本的数据分布约束,这样三个副本会分布在3个不同机房。
不同城市之间网络延迟相对较高,网络抖动风险高。不过主城市有两个副本,根据Raft一致性特点,在正常情况下,主城市的两个机房也能保证快速写入。但如果主城市挂了一个机房,则剩余的一个机房需要频繁和副城市的机房频繁通信,这时性能会有所下降,取决于两地机房的网络延迟。在模拟机房故障的测试中,在故障出现时集群整体可用,不过期间会有大概几十秒的波动,延迟从10ms以内波动到40ms左右,在一分钟后恢复稳定。
这种部署方式的硬件条件相对容易满足,并且还提供了机房级别的容灾。还有一个隐藏的好处,就是如果你有在副城市有读多写少并且希望能就近读的情况,可以通过Replication Zones把这部分数据相关的Range的Lease放到副城市的实例上,这样可以就近读,提高访问速度。其他数据的Lease可以依然保持在主城市,从而提供更优的写性能。
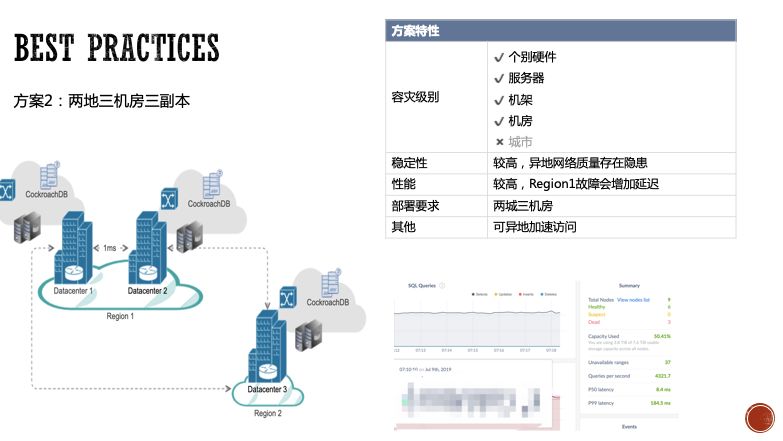
第三种方案是单机房三机架三副本的方案。多个CockroachDB实例均匀部署在不同机架的服务器上。这种部署方式提供1个机架的容灾能力。如果你的机器都在同一个机房,或者对机房容灾没有强需求,可以使用这种部署方案。
这里列举的3种部署方案各有优缺点,其实还有很多不同的部署方案,用户可以根据自身业务对性能和容灾的需求进行定制。
灾备恢复
任何系统的高可用的容灾能力都是有一定限度的,在实际生产环境中不可避免会有意外发生,例如维护人员误操作、从删库到跑路,或者黑客攻击、自然灾害等。数据备份恢复能力是数据安全的最后一道防线。CockroachDB通过BACKUP和RESTORE语句提供了备份恢复的功能。
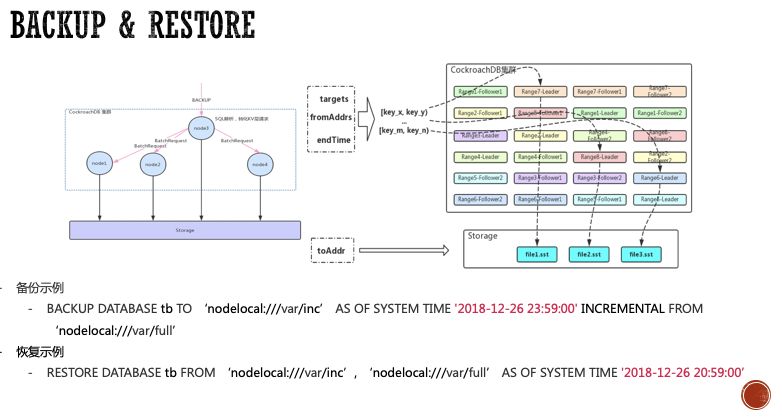
CockroachDB支持备份Database和Table级别的数据,支持备份单库、单表、多库、多表的备份;
备份方式支持全量备份和增量备份,也支持指定时间点备份。
数据备份到外部分布式存储系统上,目前支持一些常见的,例如NFS、S3、Google cloud;
业务可以针对不同重要程度的数据,进行不同粒度的备份。
在性能方面,备份过程对CPU消耗相对不高,如果集群负载不是特别高,是不会影响到正常使用的。恢复过程相对会消耗更多CPU资源。一般也不建议在业务高峰期去进行大量数据的备份。
CockroachDB的备份过程是分布式的,首先会解析用户需要备份的数据信息,产生备份任务,然后将子任务分发到相关节点直接从KV层找到相关的Range并备份成SST文件。所以备份速度跟数据分布和节点数量息息相关的,理论上数据分布在越多节点,备份速度就会越快,不过也受限于外部存储系统的写入速度。
what's next?
CockroachDB已经具备比较完善的高可用能力,不过在集群故障自修复方面有一些可以优化完善的地方。集群在副本修复期间需要在相关Raft
group中增加Follower副本,从而存在一定的稳定性风险。CockroachDB计划引入Learner角色来降低副本修复期间存在的稳定性风险。
结 语

本次分享从CockroachDB底层的数据存储结构出发,介绍了多副本一致性的原理、CockroachDB提供的Replication Zones功能特性和灾备恢复能力,然后介绍基于这些特性部署的3种高可用方案和各自的优缺点,希望通过这次分享可以让大家对CockroachDB的高可用能力有更多的认识。

关于我们:我们是百度 DBA 团队,团队有多位 CockroachDB PMC Member 及 Contributor, 目前正积极推动 NewSQL 在百度内部以及外部的发展。除了NewSQL, 我们在MySQL, PostgreSQL, GreenPlum 有多年的内核开发经验及实践经验,对数据库和大数据领域有疑问或者需求欢迎联系我们,同时欢迎有志青年加入我们!
关注我们

