




CockroachDB凭借着高可用、弹性伸缩和支持分布式事务的特性成为开源NewSQL中的佼佼者。作为一款分布式关系型数据库,CockroachDB集群性能随着集群节点数增多而呈现线性增长的趋势。除了扩展节点之外,合理使用索引也能显著提升查询性能。本文小编将从用户的角度来介绍CockroachDB索引基础和索引优化实践。
CockroachDB索引概述

CockroachDB的存储引擎是RocksDB,以键值对的方式存储数据。它在SQL层除了支持主键之外,还支持普通二级索引、联合二级索引、唯一性索引等。同时CockroachDB也是以键值对的形式存储索引,键的内容由各个索引字段拼接而成,值的内容则是主键的值。使用索引能避免SQL全表扫描,减少资源开销,充分提高SQL读性能,但另一方面采用索引会增加存储空间,造成写性能下降,需结合业务场景合理使用。
CockroachDB常见的索引操作包括CREATE INDEX、DROP INDEX、 ALTER INDEX、SHOW INDEX。
账户必须拥有表级别的CREATE权限才能执行创建索引语句,我们看下CREATE INDEX的具体用法。
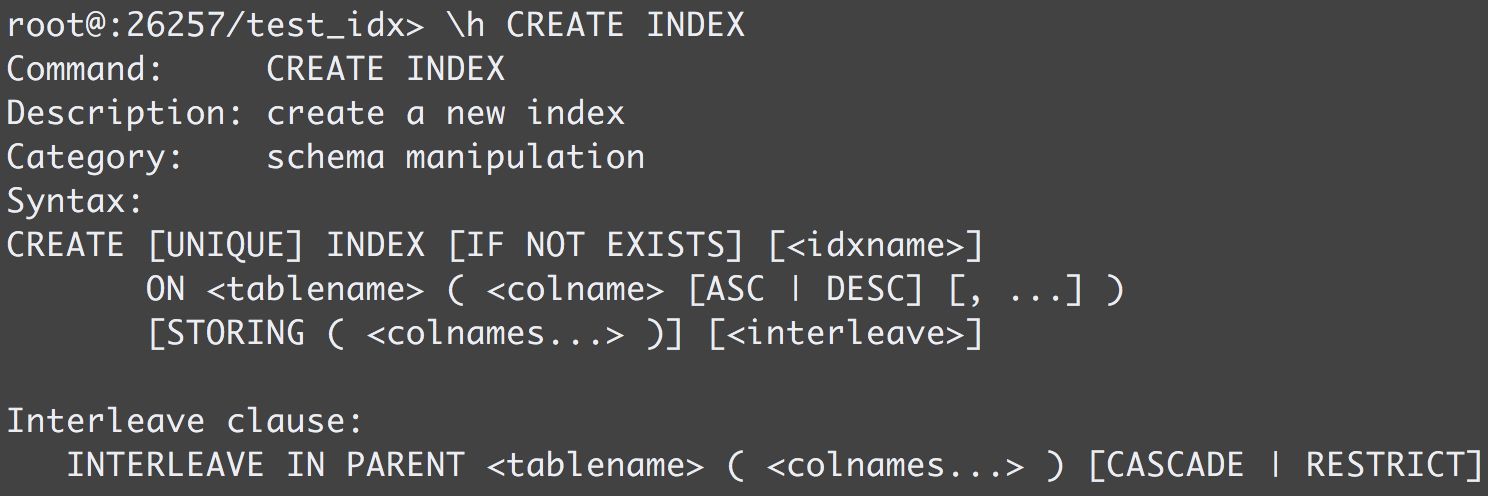
各个字段的说明如下:
字段 | 说明 |
UNIQUE | 支持唯一性、非唯一性索引;假如指定UNIQUE创建索引时,则除了插入、更新数据时会做唯一性冲突校验,创建时也会对现有数据做唯一性冲突校验; |
idxname | 索引名字,如果没有显式指定,则默认命名为<table>_<columns>_key/idx |
ASC | DESC | 索引的排序方式,默认是升序,在LIMIT语句尤其重要; |
STORING | 等同COVERING,当使用该索引时能同时获取到特定的列值,只适合特定的场景; |
interleave | 指定索引KV存储结构,一般默认即可; |
举例说明,假如test_idx库中存在一张idx_peolpe个人信息表,结构如下:

我们分别创建唯一性索引和联合索引:
“CREATE UNIQUE INDEX IF NOT EXISTS idx_class_num ON idx_people(class , number) STORING (names);”
“CREATE INDEX IF NOT EXISTS idx_name ON idx_people(name DESC); ”
然后通过“SHOW INDEX FROM idx_people”来查询idx_people索引信息:

相信不少读者对SHOW INDEX的结果感到困惑,只创建两个索引,怎么会出现七行结果呢?从Name字段中,我们不难看出这七条记录只对应了三个索引。primary 是主键索引,如果建表语句中无显式指定,则自动生成一个全局唯一的表级别rowid作为主键。其次,idx_class_num和idx_name对应上述两个SQL新增的索引项。众所周知,CockroachDB 是以KV的方式实现底层数据存储,索引数据结构也是一样。在联合索引中,Key值由各个索引字段拼接而成,Seq对应的是相应索引字段在Key值的位置。
Table和Name字段的含义是所在的表和索引名。Unique的含义是索引字段是否唯一。我们创建索引时指定idx_class_num为唯一性索引,与上图SHOW INDEX的结果一致。Direction、Storing字段跟我们创建索引时指定的排序方式和STORING相关,但是STORING包含的字段是无法保证排序。Implicit字段代表是创建索引时隐式包含的索引列,通常主键会被隐式地包含到索引以提升查询数据的效率。例如我们创建idx_name索引时仅指定了names这列,实际上隐式包含了id这个主键。
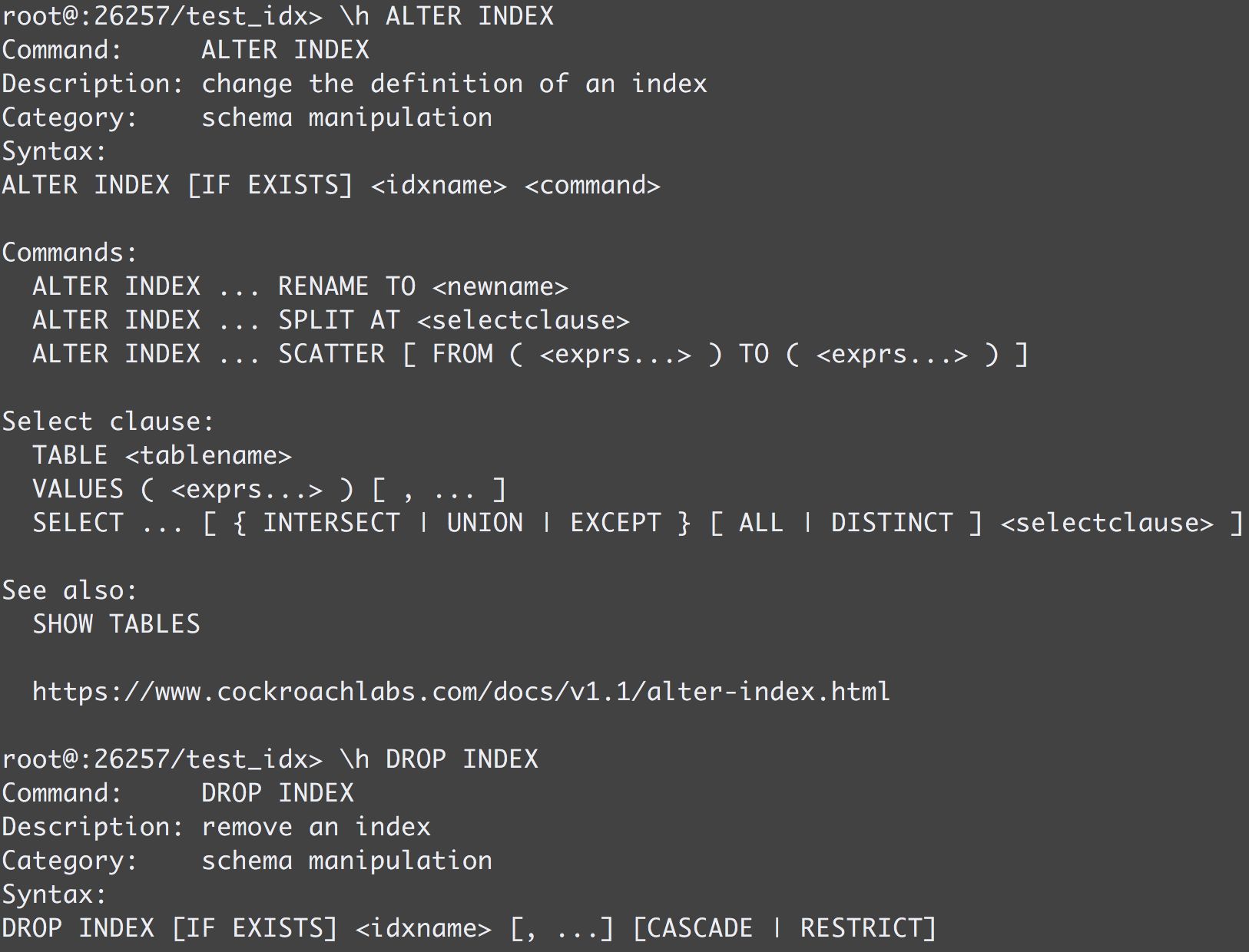
DROP INDEX 跟 ALTER INDEX 使用起来则相对比较简单,以下是具体的用法,有兴趣的同学可以动手实践下。
CockroachDB索引实践
当我们创建索引时,CockroachDB对指定索引的列值重新进行排列,以键值对的形式存储。合理有效地创建索引,执行SQL扫表时就能减少扫描数据的行数,以达到高效查询的效果。在生产环境使用过程中,使用索引一方面会增加存储的开销,另一方面影响写入的效率和性能,所以并非索引越多越好。
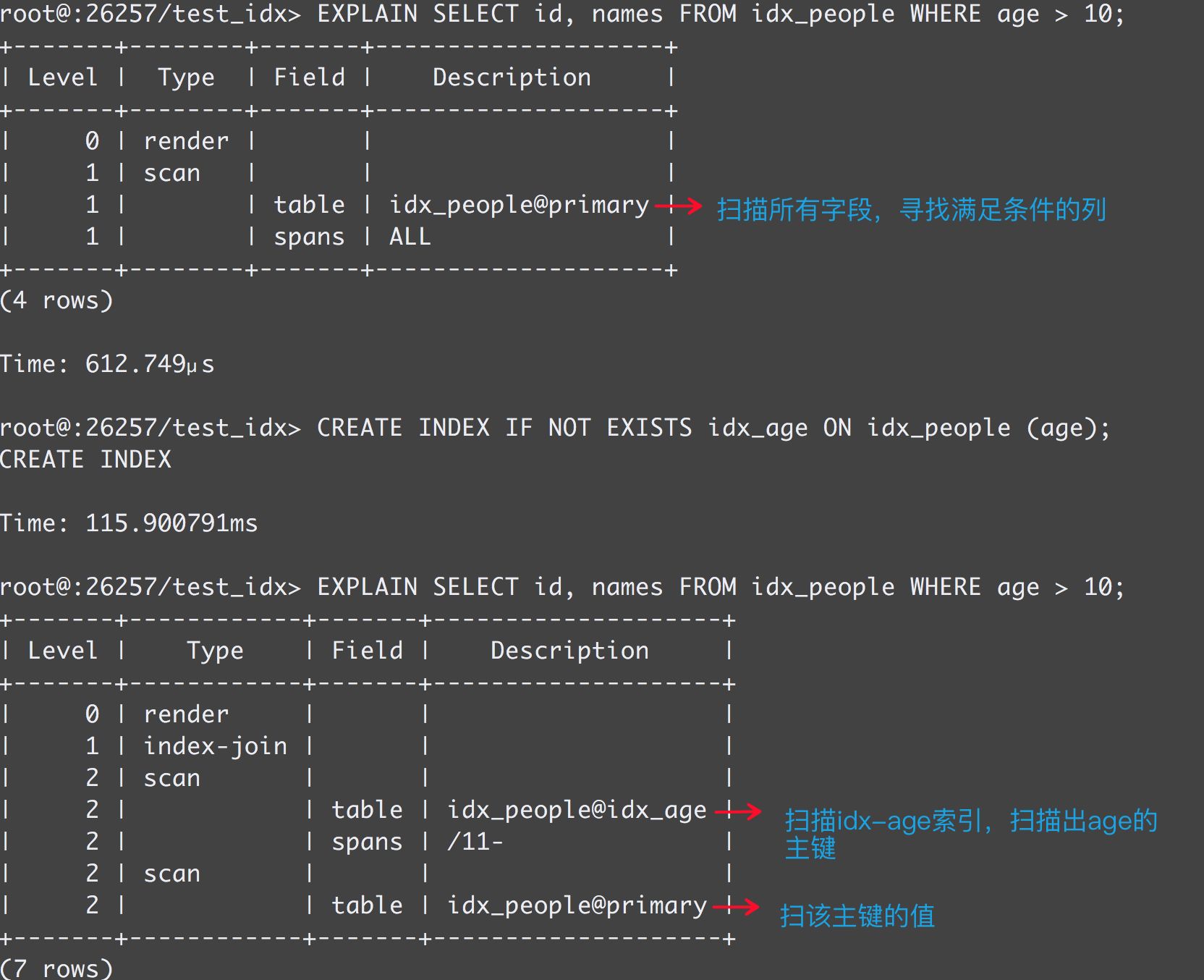
我们一开始在idx_people表中并未创建age相关的索引。假如有个需求想查询年龄大于10岁的身份证号、名字,即执行“SELECT id, names FROM idx_people WHERE age > 10”语句。与MySQL一样,我们可通过EXPLAIN获取执行计划,在此基础上了解CockroachDB的执行过程,从而获取SQL是否命中索引及命中哪个索引的信息。从执行计划中,我们可看出CockroachDB会逐一扫描主键idx_people@primary,以寻找满足条件的列。创建age索引后,再获取执行计划,可以看出CockroachDB的扫描方式发生较大变化。它会先扫描idx_people@idx_age索引,找到大于age>10所对应的主键,再扫描idx_people@primary来获取id、names。
通过上述例子,同学们应该能大致了解索引如何工作。假如SQL中有多个查询条件且表存在多个索引,CockroachDB会怎样选择索引呢?了解以下索引命中规则能帮助你创建更合适的索引。
1、主键
每张表都拥有主键——如果建表语句没有显式指定则生成全局唯一的rowid列作为主键。当没有其他索引可选择时,会默认扫描主键索引。值得注意的是,一旦创建主键则无法再变更,因此建表时根据业务场景选择合适的主键,尤其重要。
2、二级索引
CockroachDB支持单键索引和联合索引,假如你创建了(class,number,age) 这个联合索引,如果SQL中过滤条件带了class/number/age,class/number ,class都能高效地使用到索引。假如你创建(class)这个单键索引,只有过滤条件是 class 才能高效运用。虽然过滤条件是class/number时也能命中索引,但仍需去主键进一步过滤number的条件。
在联合索引下能高效检索:

在单键索引下效率则明显下降:

当然这并不是推荐大家一味地抛弃单键索引而采用联合索引,因为创建联合索引的开销会比单键的更大。这个案例是说明有些业务场景下选择联合索引更合适、效率更高。
3、索引选择原则—前缀
CockroachDB索引的数据结构是键值对。Key的数据编码格式是拼接TableID、IndexID、各个索引列的值形成字符串。
假如存在以下Schema和数据:
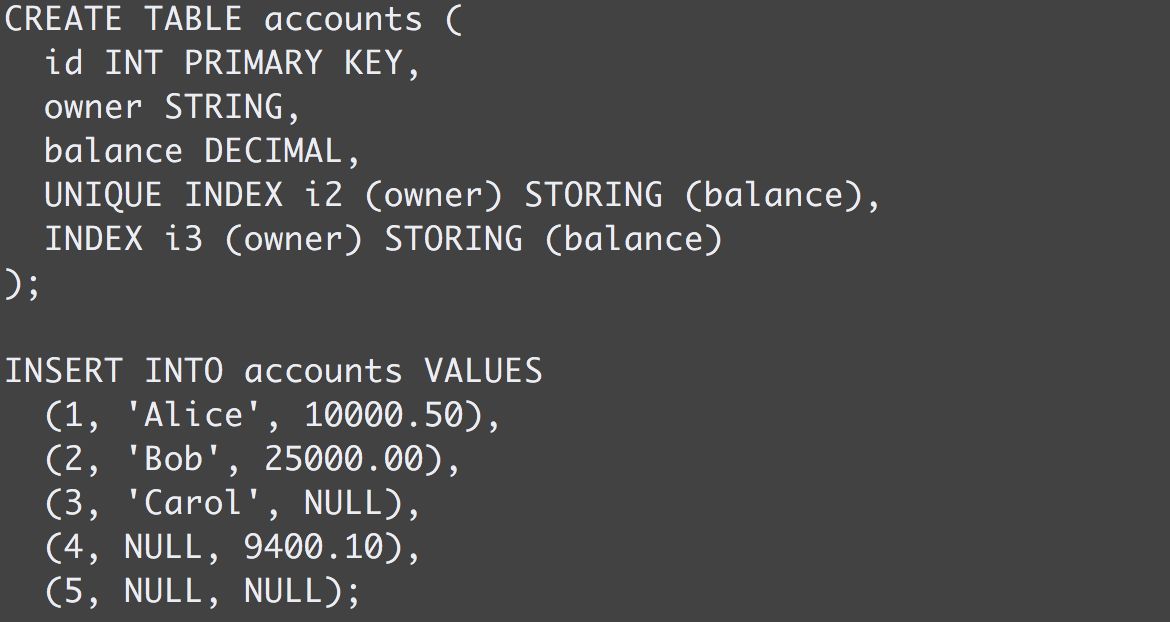
索引i2的键的存储格式是/Table/<TableID>/<IndexID>/<Indexed Column Value>/<Implicit Column Value>/<Column family ID>/<TimeStamp>,如下所示:
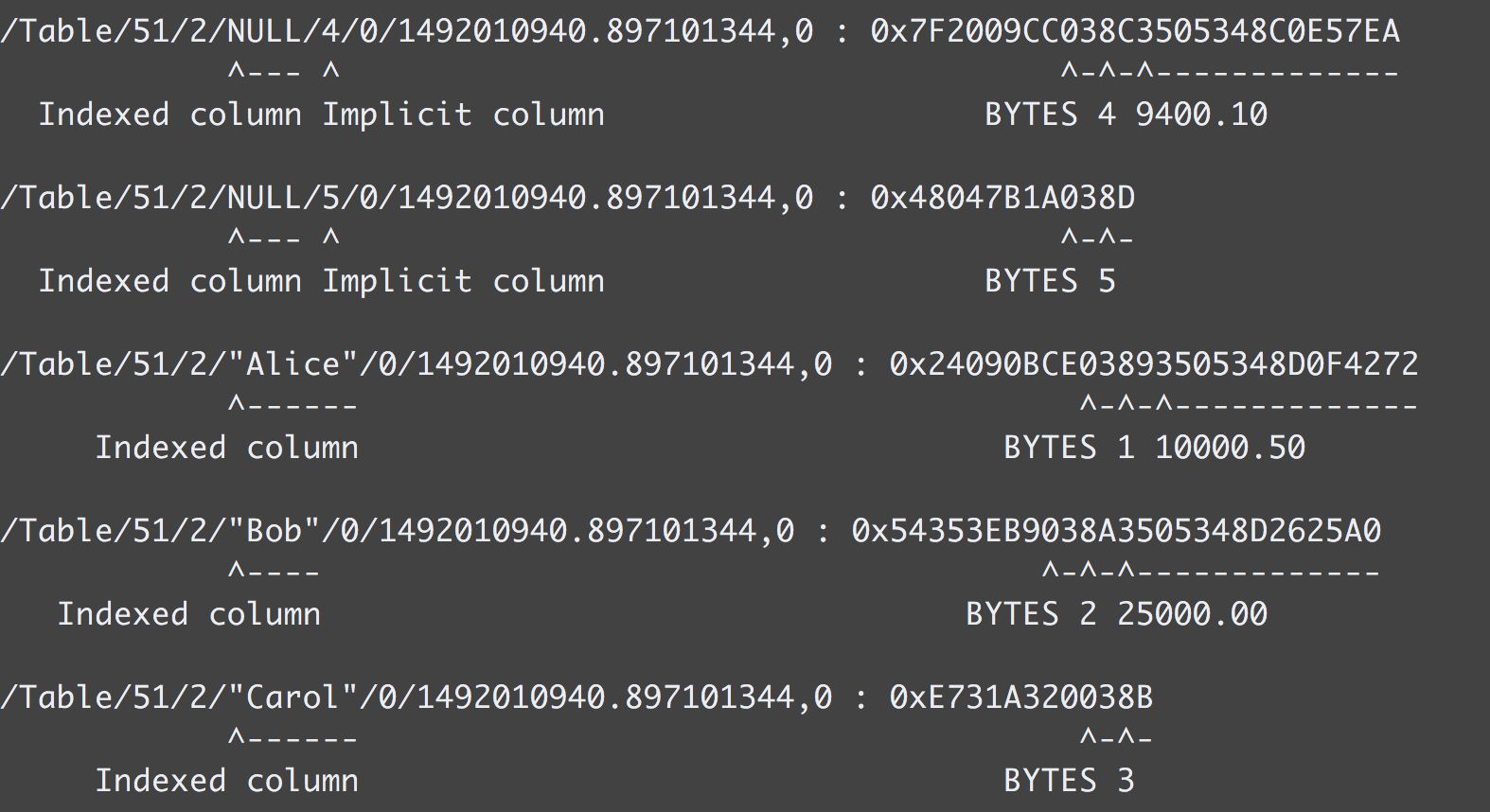
假如是联合索引,则按照创建时按照字段从左到右的顺序进行拼接,即前缀匹配。
在idx_people表中,创建索引指定的顺序是(class,number),假如存在以下数据:
INSERT INTO idx_people VALUES
(1, 'A', 10, true, 2, 40),
(2, 'B', 11, true, 3, 43),
(3, 'C', 12, true, 2, 42),
(4, 'D', 10, true, 3, 41);
则索引数据的存储方式大致如下所示
…/2/40/1/… : …
…/2/42/3/… : …
…/3/41/4/… : …
…/3/43/2/… : ...
假如我们使用“SELECT id,names FROM idx_people WHERE class in(2, 3) and number > 40” 是可以完全使用索引的(class, number)字段,但假如“SELECT id,names FROM idx_people WHERE class > 2 and number in (40 , 41)”,则无法利用索引number字段。假如新增(number,class)索引,则能够同时使用到。
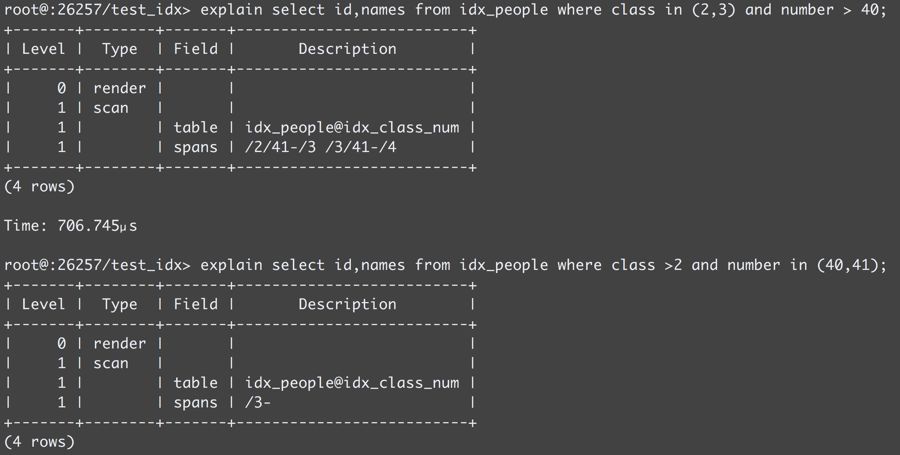
4、强制命中某一索引
在特定场景下SQL可命中多个索引,而查询优化器选择了相对低效的索引,则我们可以使用 “SELECT … FROM Table@Index WHERE …” 的方式强制使用指定的索引。
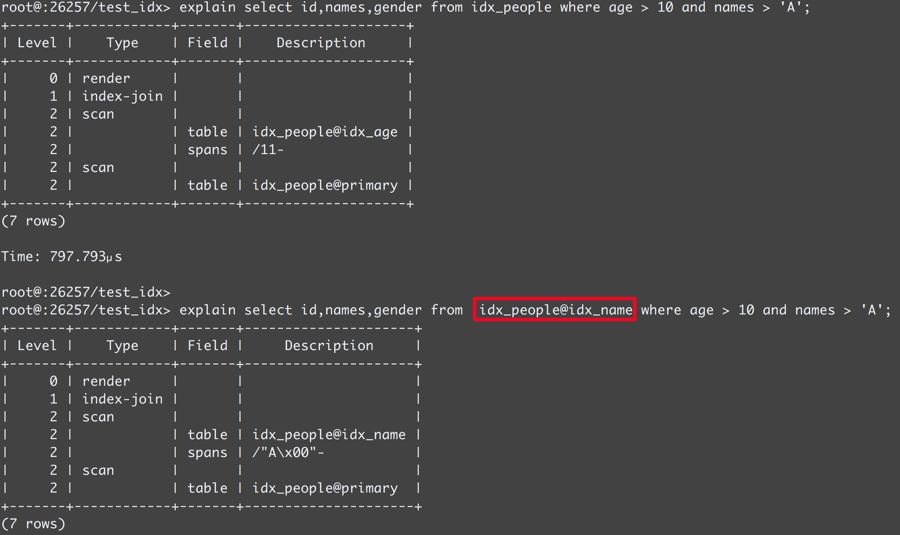
通过以上几个关于索引的case介绍,大家应该大致知道了CockroachDB索引的运行机制。在实践中,如何选择合适的索引还需要结合数据特征和业务查询场景进一步调整和优化。
关于我们:我们是百度DBA团队,团队有两位CockroachDB PMC Member及一位Contributor, 目前正积极推动NewSQL在百度内部以及外部的发展。除了NewSQL, 我们在MySQL, PostgreSQL, GreenPlum有多年的内核开发经验及实践经验,对数据库和大数据领域有疑问或者需求欢迎联系我们,同时欢迎有志青年加入我们!
关注我们

