




一次PG日志撑满的处理过程
这是我自己的一次经历。之前投稿给其他平台。现在在自己的公众号上发一下。之前的平台也没有问题,只是我现在刚开始写素材不多。
背景环境:
CentOS Linux release 7.6.
PostgreSQL 12.3
早上接到电话反馈数据库磁盘使用率达到95%。经过检查数据库实例运行正常,主从数据一致。
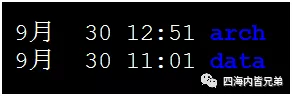
发现磁盘目录情况。Data是PG的数据库的数据目录。Arch是归档目录。这两个目录当时大约都是95G。也就是累计190G。
 图片
图片
每个日志文件是16M,有大概6500多个日志文件。开始分析原因,发现每隔10分钟一个,那说明不是数据库的DML产生的日志,而是后台自动刷新。查找相关参数在PG中控制日志切换的参数是这个archive_timeout。这个参数有点望文生义,看上去叫超时,实际上就是日志多久自动切换一次。这个名字起得有点坑。默认是600,也就是10分钟,完全对的上。这个10分钟对不对?很难说,结合实际吧。不过有一点提一下。此参数是根据默认值进行日志归档,但是如果没到时间,满了一样归档。
先修改这个让它不要再这样生成了。好在这个参数是可以动态修改的。用这句查询参数。select name, setting,context from pg_settings where name=‘archive_timeout’;图中是我修改后的。
 图片
图片
看到sighup(这是幸运的): 给服务器发送HUP信号,会服务器重新加载postgresql.conf配置,可以立即生效。意味着不用重启就可以更改全局参数。
修改命令如下:alter system set archive_timeout=3600;
不过即使你改了你再看还是原来的,为什么因为他只是写到了后台的那个配置文件,没有加载到内存,就像MySQL的privilege一样。需要手工一下。说真的Oracle的alter system带上了scope=both就让我们爽多了。(官方你是不是改改啊)
PG的刷新命令是select pg_reload_conf();好了接下来就10分钟一次可以大幅降低频率了。
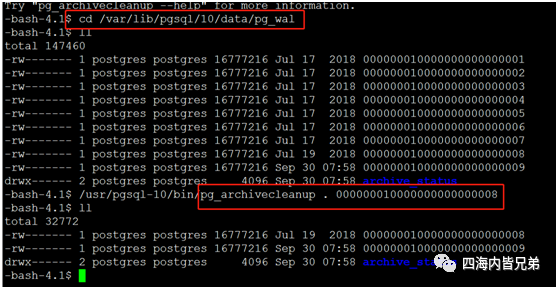
接下来清理磁盘日志先清理arch的。文件切记自己删除,这和Oracle的归档以及MySQL的binlog一样。不过PG没有,应该和官方建议一下。这个可以有。这个清理工具叫做pg_archivecleanup,现在测试环境尝试一下(什么时候都先测试的做做)下图为测试。可以看到清除了。
 图片
图片
注意事项,要删除哪些,找到那些的最后一个比如上图的尾号008的。执行pg_archivecleanup . 那个文件。实测,清除了。那个008文件之前的都没有了。
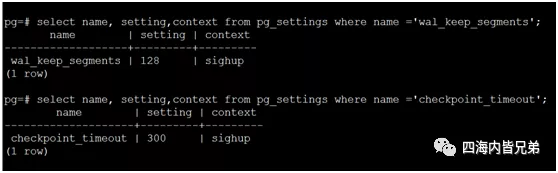
接下来这个问题就有点麻烦了,WAL目录下的文件。这里感谢去哪儿的彭占元老师的分析,先查了两个参数。下图中的wal_keep_segments是保留多少个,而checkpoint_timeout是看你多少时间清理一次。又是pg的风格timeout表示间隔。默认5分钟。
 图片
图片
默认5分钟。select * from pg_stat_get_archiver();
看到了从8月到现在一直有6053个,你乘以16M 就是95G。
 图片
图片
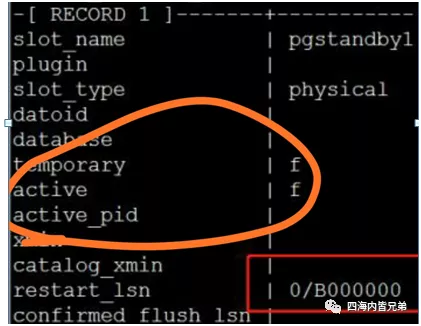
select * frompg_replication_slots ;看到了这个事实证明这个就是问题所在。
 图片
图片
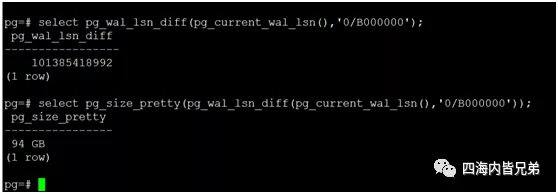
selectpg_walfile_name(‘0/B000000’);咱也不知道当初发生了什么?据说这种问题比较常见,认了。
 图片
图片
你看,算下来94G
 图片
图片
由于之前的那个这里是有问题的。所以删除它。
selectpg_drop_replication_slot(‘pgstandby1’);
 图片
图片
删除以后等到了检查点去看,如果都被清理了。当然手工检查点也行。
 图片
图片
观察了一会主从,数据也在同步变化。解决。
