




GreatDB作为一款国产化分布式数据库产品,在金融、运营商、能源等行业已有广泛应用。其在Mysql8.0MGR的基础之上做了大量的优化,在分布式可扩展性、数据库兼容性以及集群高可用层面有自己的优势,本文将简单介绍GreatDB的基本架构,并测试快速部署计算存储分离集群环境。
GreatDB整体架构
GreatDB整体架构如下图所示包括计算层和存储层、其中计算层部分实现分布式数据库架构下的整个集群元数据、数据节点和计算节点的管理和维护。
架构特点
计算层和存储层可以独立弹性扩展。
计算层和存储层之间没有强耦合性,实现计算与存储的分离。
计算和存储层的特性重点不⼀样,可以针对性的进行开发迭代。
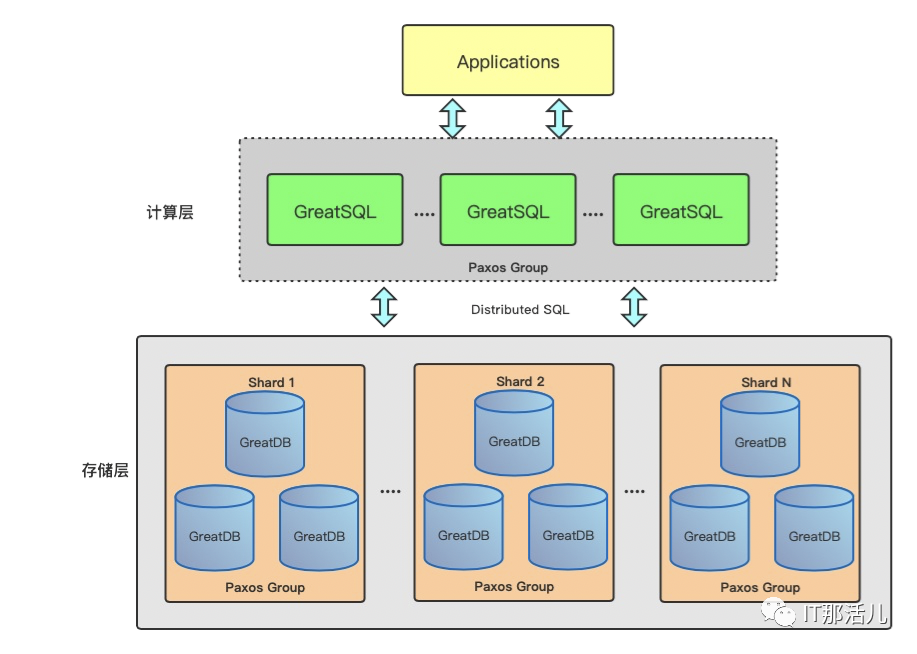
SQL节点(计算层)
SQL节点之间使⽤MGR的多主模式,组成了⼀个全同步集群,也作为数据库集群暴露给应⽤程序的节点。每个SQL节点 都可以接收⽤户的读写请求。SQL节点主要负责实现了⾃研的GreatDB引擎,其功能如下:
维护集群的元数据信息
维护表的分布信息
与数据节点通信,将数据存取任务下发到数据节点
SQL节点扩充了MySQL系统表,会将集群元数据写⼊到系统表中,⽤户操作任何⼀个节点改变了集群的元数据,都会通过全同步复制同步到集群其它节点,从⽽达到元数据强一致的效果。
数据节点(存储层)
数据节点按照shard进⾏划分,⼀个shard内的数据节点构成⼀个MGR单主集群,负责存储集群的一个分⽚的数据,⼀个 shard内保证副本数据的强一致性。所有shard共同构成集群的完整数据。数据节点主要负责如下功能:
接收SQL节点的SQL命令并执⾏。
组建MGR集群,⾃动故障恢复。数据节点不⽌具有存储功能,数据节点⼀样具有计算能⼒,可以进⾏复杂计算,SQL节点可以将部分计算逻辑下推到计算节点进⾏计算。
连接方式
应用客户端可以通过JDBC或者ODBC直接连接到计算节点,也可以经过负载均衡F5或loadbalance或LVS或HAProxy的方式连接到计算节点,达到流量均衡的目的。
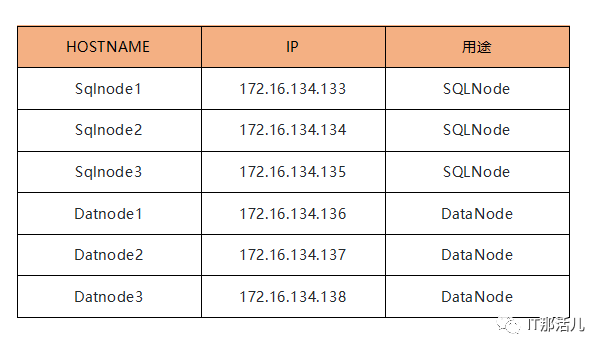
GreatDB集群计算存储分离环境部署至少需要三台计算节点、三台数据节点,服务器与端口配置设计如下:
服务器列表
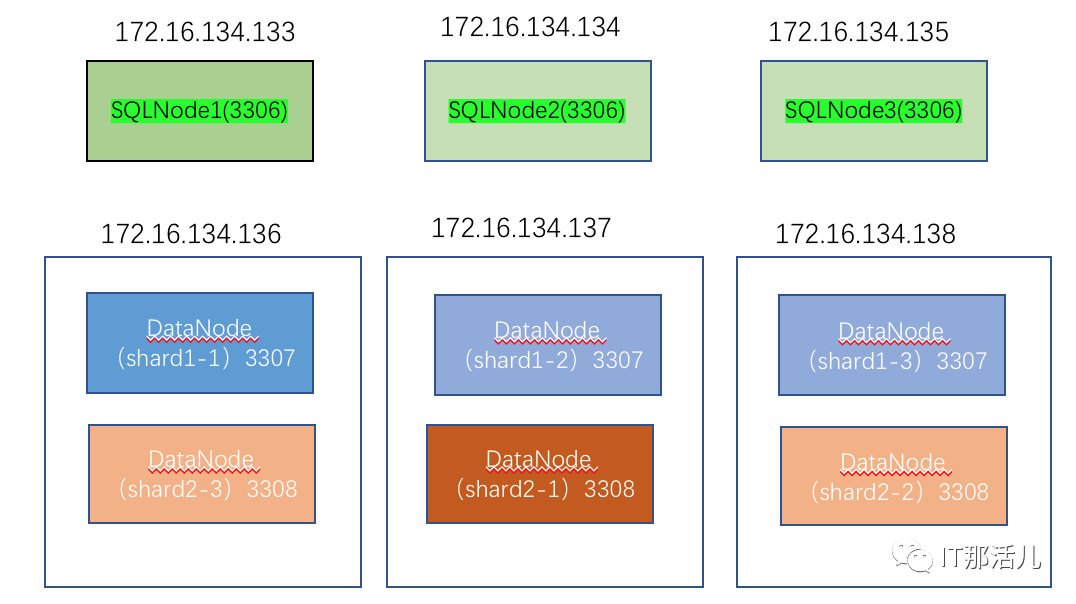
拓扑图和端口
GreatDB快速安装部署
依赖库安装
依赖库安装 GreatDB Cluster服务器程序依赖libaio库,用户可以通过如下命令进⾏安装。
▼▼▼## Yum-based systemsshell> yum search libaio # search for infoshell> yum install libaio-devel # install library
GreatDB Cluster客户端程序依赖libncurses库,用户可以通过如下命令进⾏安装:
▼▼▼## Yum-based systems shell> yum search ncurses # search for info shell> yum install ncurses-devel # install library
安装包准备
将greatdb-cluster-5.0.6-2e6cda47fea-Linux-glibc2.17-x86_64.tar.gz软件安装包上传至所有服务器
在所有服务器解压软件安装包至目录/usr/local/greatdb-cluster
按照下⾯的指令进⾏软件包的安装:
▼▼▼shell> groupadd greatdb shell> useradd -r -g greatdb -s bin/false greatdb shell> cd usr/local shell> tar -xzvf greatdb-cluster-5.0.6-2e6cda47fea-Linux-glibc2.17-x86_64.tar.gzshell> ln -s greatdb-cluster-5.0.6-2e6cda47fea-Linux-glibc2.17-x86_64 greatdb-cluster shell> cd greatdb-cluster shell> chown greatdb:greatdb -R
配置文件与数据
为了⽅便管理,统⼀将配置⽂件设置在 etc/greatdb-cluster ⽬录下,数据⽬录设置 在 /var/lib/greatdb-cluster ⽬录下。
▼▼▼shell> mkdir /var/lib/greatdb-cluster shell> mkdir /etc/greatdb-cluster
每个节点和⽂件及⽬录的对应关系如下:

配置⽂件模板 SQLNode和DataNode的配置⽂件模板与MySQL配置方式⼀致,为了简化⽣成配置⽂件的复杂度,针对单机快速部署提供如下bash脚本create_config.sh ,内容如下:
▼▼▼#!/bin/bashset -exip=$1port=$2echo "[mysqld]datadir=/var/lib/greatdb-cluster/$portsocket=/var/lib/greatdb-cluster/$port/greatdb.sockuser=greatdbport=$2server_id=$RANDOMmax_connections=1000report-host=$1## group replication configurationbinlog-checksum=NONEenforce-gtid-consistencygtid-mode=ONloose-group_replication_start_on_boot=OFFloose_group_replication_recovery_get_public_key=ONloose-group_replication_local_address= \"$1:1$2\""
此模板接收两个参数,node名称和端⼝号,这⾥使⽤ create_config.sh创建不同节点的配置⽂件。
▼▼▼# 在sqlnode1上⽣成计算实例的配置⽂件bash create_config.sh 172.16.134.133 3306 > /etc/greatdb-cluster/3306.cnf# 在sqlnode2上⽣成计算实例的配置⽂件bash create_config.sh 172.16.134.134 3306 > /etc/greatdb-cluster/3306.cnf# 在sqlnode3上⽣成计算实例的配置⽂件bash create_config.sh 172.16.134.135 3306 > /etc/greatdb-cluster/3306.cnf## 在datanode1上⽣成数据节点的配置⽂件bash create_config.sh 172.16.134.136 3307 > /etc/greatdb-cluster/3307.cnfbash create_config.sh 172.16.134.136 3308 > /etc/greatdb-cluster/3308.cnf## 在datanode2上⽣成数据节点的配置⽂件bash create_config.sh 172.16.134.137 3307 > /etc/greatdb-cluster/3307.cnfbash create_config.sh 172.16.134.137 3308 > /etc/greatdb-cluster/3308.cnf## 在datanode3上⽣成数据节点的配置⽂件bash create_config.sh 172.16.134.138 3307 > /etc/greatdb-cluster/3307.cnfbash create_config.sh 172.16.134.138 3308 > /etc/greatdb-cluster/3308.cnf
初始启动节点
创建好各⾃的配置⽂件后,直接使⽤greatdb_init初始化各个节点,greatdb_init会⾃动初始化数据库节点 实例,并启动实例。
初始启动SQLNode
在sqlnode1,sqlnode2,sqlnode3上,分别进⼊ /usr/local/greatdb-cluster ⽬录,使⽤greatdb_init初始 并启动SQLNode。
▼▼▼## 在sqlnode1上初始化计算实例的数据⽬录[root@sqlnode1]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3306.cnf --cluster_user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=sqlnode## 在sqlnode2上初始化计算实例的数据⽬录[root@sqlnode2]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3306.cnf --cluster_user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=sqlnode## 在sqlnode3上初始化计算实例的数据⽬录[root@sqlnode3]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3306.cnf --cluster_user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=sqlnode
初始启动DataNode
在datanode1,datanode2,datanode3上,分别进⼊ /usr/local/greatdb-cluster ⽬录,使⽤greatdbd初始 化DataNode的数据⽬录。
▼▼▼## 在datanode1上初始化数据节点的数据⽬录[root@datanode1]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3307.cnf --cluster_user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode[root@datanode1]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3308.cnf --cluster_user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode## 在datanode2上初始化数据节点的数据⽬录[root@datanode2]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3307.cnf --cluster_user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode[root@datanode2]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3308.cnf --cluster_user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode## 在datanode3上初始化数据节点的数据⽬录[root@datanode3]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3307.cnf --cluster_user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode[root@datanode3]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3308.cnf --cluster_user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode
创建集群
使⽤ root 登陆任意⼀个SQLNode,进⾏初始化集群操作,随后进⾏添加SQLNode和DataNode的操 作,这⾥以sqlnode1作为初始化节点。
▼▼▼## 登陆sqlnode1[root@localhost greatdb-cluster]# bin/greatsql -h127.0.0.1 -P3306 -uroot## 初始化集群GreatDB Cluster> call mysql.greatdb_init_cluster('greatdb_cluster', 'greatdb', 'greatdb');Query OK, 1 row affected (4.24 sec)## 添加SQLNodesqlnode2GreatDB Cluster> call mysql.greatdb_add_sqlnode('172.16.134.134', 3306);Query OK, 1 row affected (4.24 sec)## 添加SQLNodesqlnode3GreatDB Cluster> call mysql.greatdb_add_sqlnode('172.16.134.135', 3307);Query OK, 1 row affected (4.24 sec)## 添加shard1的数据节点并初始化GreatDB Cluster> call mysql.greatdb_add_datanode('shard1', 'sd1_dn1', '172.16.134.136', 3307, 'NODE_MGR');Query OK, 1 row affected (0.03 sec)GreatDB Cluster> call mysql.greatdb_add_datanode('shard1', 'sd1_dn2', '172.16.134.137', 3307, 'NODE_MGR');Query OK, 1 row affected (0.03 sec)GreatDB Cluster> call mysql.greatdb_add_datanode('shard1', 'sd1_dn3', '172.16.134.138', 3307, 'NODE_MGR');Query OK, 1 row affected (0.03 sec)GreatDB Cluster> call mysql.greatdb_init_shard('shard1');Query OK, 1 row affected (4.24 sec)## 添加shard2的数据节点并初始化GreatDB Cluster> call mysql.greatdb_add_datanode('shard2', 'sd2_dn2', '172.16.134.136', 3308, 'NODE_MGR');Query OK, 1 row affected (0.03 sec)GreatDB Cluster> call mysql.greatdb_add_datanode('shard2', 'sd2_dn3', '172.16.134.137', 3308, 'NODE_MGR');Query OK, 1 row affected (0.03 sec)GreatDB Cluster> call mysql.greatdb_add_datanode('shard2', 'sd2_dn1', '172.16.134.138', 3308, 'NODE_MGR');Query OK, 1 row affected (0.03 sec)GreatDB Cluster> call mysql.greatdb_init_shard('shard2');Query OK, 1 row affected (4.24 sec)
创建完成查看SQL节点状态:

查看数据节点状态:


更多精彩干货分享
点击下方名片关注
IT那活儿

