




前言
大家好,今天我们来介绍一下,如何在PostgreSQL中实现LSM-Tree.
LSM-Tree介绍
按照惯例,我们先来科普一下LSM-Tree结构。我们都知道一个事情,就是磁盘的顺序读写快,随机操作慢。而LSM-Tree的一个思想就是利用磁盘的顺序写入性能要高于随机写入,将批量随机写入转化成一次顺序写入。
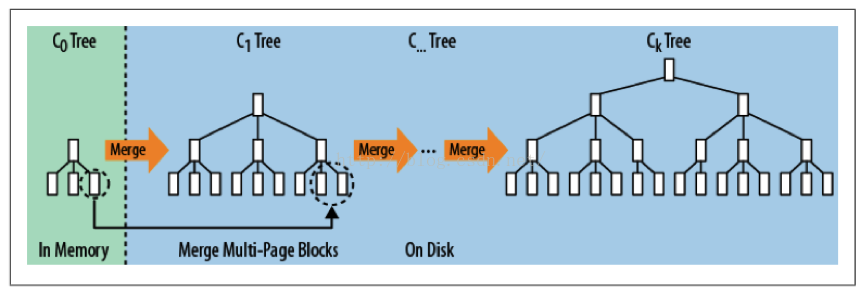
LSM-Tree设计如图所示:
首先内存中存在的树叫C0 tree,写入都从C0 tree开始。具体呈现形式可以是任意方便健值查找的数据结构,比如红黑树、Map、跳表等等。而C1 tree、C2 tree一直到Ck tree都存储在硬盘上。
当数据执行一个写入操作,会首先记录到wal日志(Write Ahead Log),也就是写前日志。该日志可以保证异常宕机后数据的恢复。同时把数据加载到C0 tree。等C0 tree达到一定的大小之后,就把C0和C1进行一个合并,类似于归并排序。整个过程就被称作Compaction。合并之后的新的C1 tree就整体顺序写磁盘,然后替换掉原来的C1 tree。当C1 tree的达到一定的大小后,会继续向下一层级进行合并,一直合并到Ck tree。
所以这里衍生了一个问题,比如你的Ck Tree有一条记录是a=5。而最新的C1 tree它的值是a=10,那么这个时候Ck Tree这条记录是一直存在的,只有当合并到时候,才会去清理老版本(a=5)这个值。所以在查询的时候,它会先查询C0 tree,如果没有再查询C1 tree,然后一直查到Ck tree。一次查询需要多次单点查询,这就会慢很多。
上述是论文中的理论,实际的设计情况略有不同,我们以Rockdb来举例(因为接下来我们也会探讨使用Rockdb作为fdw来进行访问实现LSM-tree的利与弊)。
RockDB
RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。它的架构图如下:
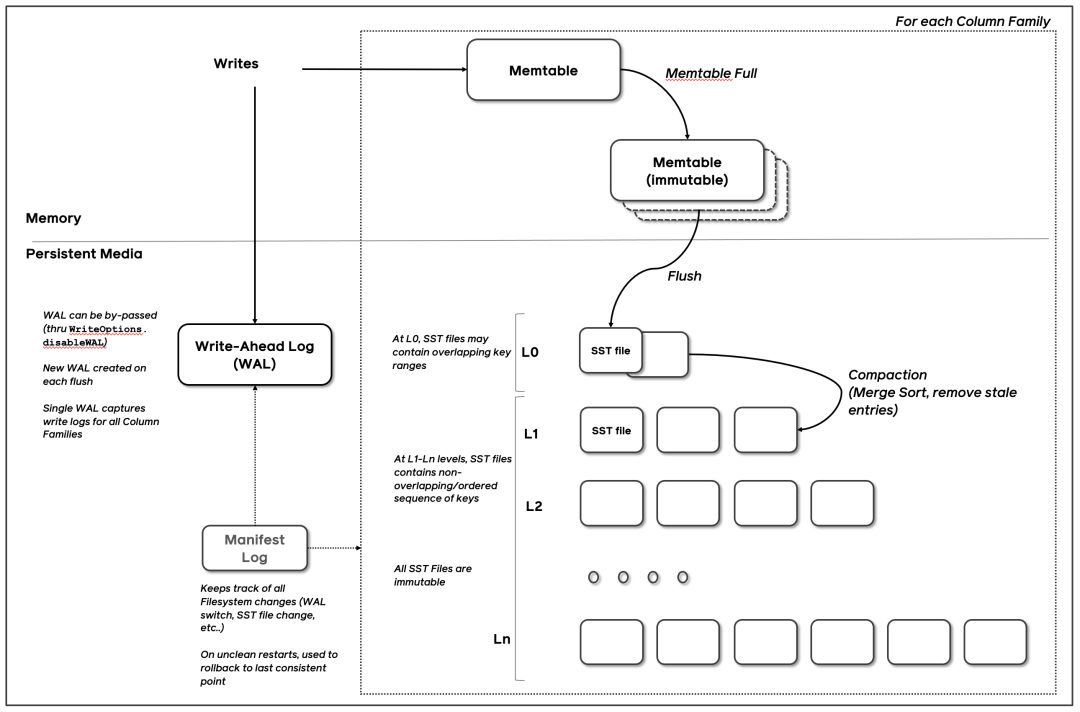
首先任何写入都会先写到WAL日志文件,前面介绍过这主要是为了方便崩溃之后的恢复。然后再写入到Memory Table(相当于C0 tree)。而Memory Table的数据结构是跳表,这里的跳表可以是多种类型,通用的就是skiplist,也可以是hashskiplist、hashlinklist、VECTOR等。这个时候写入就完成了。由于写入不需要落盘,这种速度会非常的高效。当Memory Table写满之后,就会变成Immutable Memory Table。后台进程就会把这个不可变的Memory Table落盘成一个SST文件,并把它放在Level 0层。当Level 0层的SST文件达到一定的阈值后,就会通过Compaction的策略将其放入到Level 1层,然后Level 1再继续向下合并。
PostgreSQL LSM-TREE的实现
最后我们来介绍一下PostgreSQL LSM-tree的实现。介绍的主要是社区中Konstantin Knizhnik发布的一封邮件。它首先是通过pgrocks-fdw来实现RocksDB外部存储。(注:TiDB也是通过外接RocksDB这种方式实现的)。
他自己对pgrocks-fdw进行了一些改造,具他所说,pgrocks-fdw是很有意思的东西,RocksDB是多线程嵌入式数据库引擎,而Postgres基于多进程架构。要把这两个对接起来,他们使用了一种叫"server inside server"的方法,由一个bgworker与RocksDB一起工作的进程,后端通过共享内存队列向它发送请求。
不过这个哥们也说了:在Postgres中使用基于RocksDB的想法很有用。但是这种方式违反了Postgres的ACID属性。没有原子性和一致性(RocksDB 原则上支持2PC,但这里没有使用)。说到这里,其实可以看看TiDB是怎么实现的,TiDB的底层存储引擎也是RocksDB,以下来图片自于TiDB。

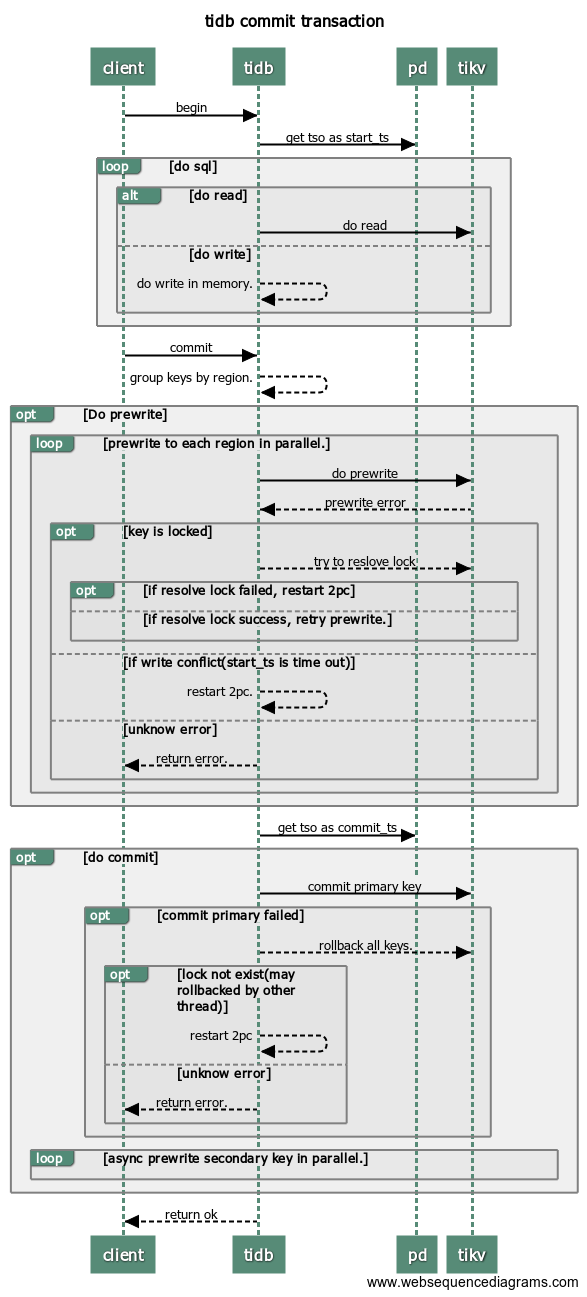
其实要实现简单的原子性就必须要使用2pc(两阶段提交来实现)。而这里按照作者的说法fdw的代码没有实现。而要实现一致性,TiDB采用的是Raft协议。所以作者就搞了一个有意思的想法。
Then I think about implementing ideas of LSM using standard Postgres nbtree.
作者使用了三个索引,两个循环使用的顶级索引(用于快速插入)和一个主索引。这个顶级索引足够小(可以存放在内存中),因此在这个索引中插入非常快。然后会定期将数据从顶部索引合并到基本索引并截断顶部索引。这里使用两个顶级索引主要是为了解决其中一个索引写满达到阈值的时候,向主索引合并会阻塞继续插入。所以就弄了一个类似Rockdb中的Immutable Memory Table概念。
不过作者提到Postgres Index AM没有bulk insert这样的操作,所以只能是正常的插入,但是插入的数据已经按key进行排序,可以提高局部访问性并解决基本索引随机读取的问题。至于读的问题,它必须在所有三个索引中进行查找并合并搜索结果。(如果在顶部索引中找到搜索值,我们可以避免额外搜索)。在合并顶部索引和基本索引期间,可能会在两者中找到相同的TID,但是在合并搜索结果期间可以轻松消除此类重复。
LSM3
接下来我们就来试用一下作者写的插件LSM3。我首先是在PostgreSQL 12上编译了一下,竟然没成功。于是我又在PostgreSQL 13上编译了一下,这次是成功的。看了一下编译的报错,12以下的版本貌似是不支持的。
make USE_PGXS=1
make USE_PGXS=1 install
postgres=# alter system set shared_preload_libraries='lsm3';
pg_ctl stop
pg_ctl start
postgres=# create extension lsm3;
CREATE EXTENSION
这样我们的LSM3就已经安装成功了。
接下来就是创建索引,在创建索引的时候要使用lsm3关键字。
postgres=# create table t(id integer, val text);
CREATE TABLE
postgres=# create index idx on t using lsm3(id);
CREATE INDEX
--后台日志:
2021-07-26 16:31:37.593 CST [3356] LOG: lsm3_build idx
2021-07-26 16:31:37.593 CST [3356] STATEMENT: create index idx on t using lsm3(id);
postgres=# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
val | text | | |
Indexes:
"idx" lsm3 (id)
"idx_top0" lsm3_btree_wrapper (id) INVALID
"idx_top1" lsm3_btree_wrapper (id) INVALID
通过查看表t,现在有三个索引,idx_top0和idx_top1就是我们所说的顶级索引,而idx就是最终合并出来的索引。
postgres=# insert into t select 1,'aaa' from generate_series (1,1000000) i;
INSERT 0 1000000
postgres=# explain analyze select * from t where id=1001;
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Index Scan using idx on t (cost=0.05..4.07 rows=1 width=8) (actual time=0.019..0.019 rows=0 loops=1)
Index Cond: (id = 1001)
Planning Time: 0.109 ms
Execution Time: 0.031 ms
(4 rows)
但是这里我有一个疑问,怎么idx_top0和idx_top1后面会显示invalid。
postgres=# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
val | text | | |
Indexes:
"idx" lsm3 (id)
"idx_top0" lsm3_btree_wrapper (id) INVALID
"idx_top1" lsm3_btree_wrapper (id) INVALID
postgres=# select pg_size_pretty(pg_relation_size('idx_top0'));
pg_size_pretty
----------------
6312 kB
(1 row)
postgres=# select pg_size_pretty(pg_relation_size('idx_top1'));
pg_size_pretty
----------------
8192 bytes
(1 row)
postgres=# select pg_size_pretty(pg_relation_size('idx'));
pg_size_pretty
----------------
8192 bytes
(1 row)
查看了一下索引的大小,证明还是在用,再添加一点数据。
insert into t select i, 'aaa' from generate_series (1000001,10000000) i;
这次增加数据,可以从后台日志看到下列信息。
2021-07-26 16:52:15.778 CST [3646] LOG: Lsm3: merge top index idx_top0 with size 8335 blocks
2021-07-26 16:52:21.887 CST [3646] LOG: Lsm3: truncate index idx_top0
2021-07-26 16:52:25.982 CST [3646] LOG: Lsm3: merge top index idx_top1 with size 8268 blocks
2021-07-26 16:52:30.853 CST [3646] LOG: Lsm3: truncate index idx_top1
2021-07-26 16:52:32.059 CST [3569] LOG: checkpoints are occurring too frequently (12 seconds apart)
2021-07-26 16:52:32.059 CST [3569] HINT: Consider increasing the configuration parameter "max_wal_size".
2021-07-26 16:52:35.283 CST [3646] LOG: Lsm3: merge top index idx_top0 with size 8268 blocks
2021-07-26 16:52:38.252 CST [3646] LOG: Lsm3: truncate index idx_top0
这次能够明显的看到它执行了merge index和truncate index的操作,三个索引的大小也跟着发生了改变。
postgres=# select pg_size_pretty(pg_relation_size('idx_top0'));
pg_size_pretty
----------------
8192 bytes
(1 row)
postgres=# select pg_size_pretty(pg_relation_size('idx_top1'));
pg_size_pretty
----------------
4800 kB
(1 row)
postgres=# select pg_size_pretty(pg_relation_size('idx'));
pg_size_pretty
----------------
194 MB
(1 row)
LSM3的限制和注意事项
不支持并行索引扫描。 不支持Array keys。 Lsm3索引不能被声明为唯一的。
Lsm3可以使用以下参数配置扩展:
lsm3.max_indexes: Lsm3 索引的最大数量(默认为 1024)。 lsm3.top_index_size: 顶部索引的大小 (kb)(默认 64Mb)。
虽然lsm3无法强制执行唯一约束,但仍然可以将索引标记为唯一,用来优化索引搜索。如果索引被标记为唯一并且在活动的顶部索引中找到了搜索键,则不会执行其他两个索引中查找。就应用程序最常搜索最近插入的数据而言,我们可以通过仅执行一次索引查找而不是 3 次来加速此搜索。可以使用索引选项将索引标记为唯一。
create index idx on t using lsm3(id) with (unique=true);
Lsm3为每个Lsm3索引创建了bgworker合并过程,所以需要我们把max_worker_processes参数调整足够大。
后记
暂时没有在生产环境找到PostgreSQL 13的数据库,所以在自己的虚拟机上稍微测试了一下,按照作者提供的压测数据,单进程tps还是很可观的,然而在并发的情况下,不如RocksDB FDW。所以作者给出的结论就是:Lsm3可以为不适合在内存中的加载的大型索引提供显著的性能改进。索引大小和RAM大小之间的比率越大,您获得的插入速度的就越大。
参考链接:
https://github.com/facebook/rocksdb/wiki/RocksDB-Overview
https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
https://www.postgresql.org/message-id/315b7ce8-9d62-3817-0a92-4b20519d0c51%40postgrespro.ru
https://github.com/vidardb/pgrocks-fdw
https://book.tidb.io/session3/chapter4/read-write-metrics.html
