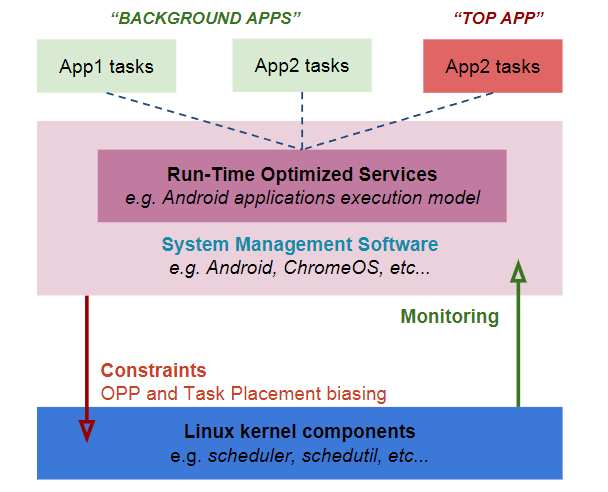
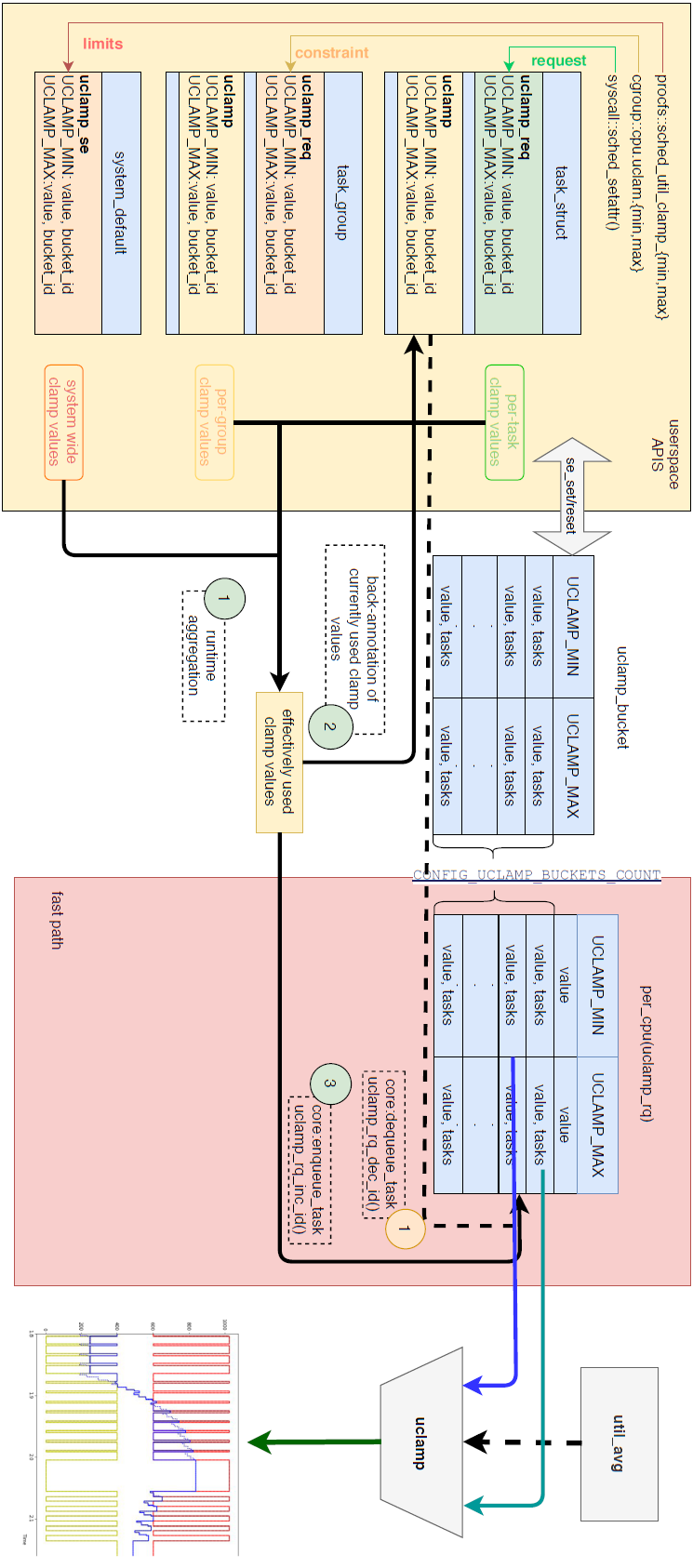
随着linux内核调度技术的不断演进,目前存在多个调度类(stop、deadline、rt、cfs、idle)以满足不同性质和要求的任务(task)的调度需求。对于用户空间来说,完全公平调度器(CFS)和实时调度器(RT)是绝大多数任务所使用的,但是基于POSIX Priority算法不足以支撑关于选核和调频的调度器特性。关于任务的性质、性能/功耗需求用户空间拥有足够的信息,那么若将用户空间关于任务的信息传递给内核任务调度器,则能够更好的帮忙调度器进行任务的调度。Utilization Clamping(uclamp)便是这样一种机制。一、Utilization Clamping(uclamp)Utilization翻译过来是利用率、使用率的意思,存在CPU Utilization和Task Utilization两个维度的跟踪信号。CPU Utilization用于指示CPU的繁忙程度,内核调度器使用此信号驱动CPU频率的调整(schedutil governor生效时);Task Utilization用于指示一个task对CPU的使用量,表明一个task是“大”还是“小”,此信号可以辅助内核调度器进行选核操作。但是用PELT负载跟踪算法得到的task util与用户空间期望有时候会出现分裂,比如对于控制线程或UI线程,PELT计算出的util可能较小,认为是“小”task,而用户空间则希望调度器将控制线程或UI线程看作“大”task,以便被调度到高性能核运行在高频点上使任务更快更及时的完成处理。同样地,对于某些长时间运行的后台task,eg:日志记录,PELT计算出的task util可能很大,认为是“大”task,但是对于用户空间来说,此类task对于完成时间要求并不高,并不希望被当作“大”task,以利于节省系统功耗和缓解发热。uclamp提供了一种用户空间对于task util进行限制的机制,通过该机制用户空间可以将task util钳制在[util_min, util_max]范围内,而cpu util则由处于其运行队列上的task的uclamp值决定。通过将util_min设置为一个较大值,使得一个task看起来像一个“大”任务,使CPU运行在高性能状态,加速任务的处理,提升系统的性能表现;对于一些后台任务,通过将util_max设置为较小值,使其看起来像一个“小”任务,使CPU运行在高能效状态,以节省系统的功耗。Android Kernel 5.4以前,存在一个schedtune feature,也提供了与uclamp类似的功能。schedtune与uclamp都是由ARM公司的Patrick Bellasi主导开发,uclamp作为schedtune的替代方案,弥补了schedtune种种不足,使得uclamp最终合入mainline kernel。用户空间进程管理服务将相关task的util clamp值通过适当接口传递到内核空间,调度器基于用户空间提供的信息通过schedutil驱动频率的调整,也可以基于该信息为task选择适当的core。proc/sys/kernel/sched_util_clamp_min
proc/sys/kernel/sched_util_clamp_max
全局设置值,用于限制per-task_group值和per-task值,使之不超过全局设置值,取值范围0 - SCHED_CAPACITY_SCALE。
cpu.uclamp.max
cpu.uclamp.min
基于cgroup实现的per-task group值,实现对相同性能/功耗需求的一组task的控制,该设置值会限制组内各个任务的per-task值。取值范围0.00 - 100.00,格式为两位小数精度的百分比值。
通过sched_setattr系统调用,每个任务都可以自主的设置各自的uclamp_min和uclamp_max,以满足自身的性能/功耗需求,但是该设置值会受制于cgroup设置值和系统全局设置值,取值范围0 - SCHED_CAPACITY_SCALE。
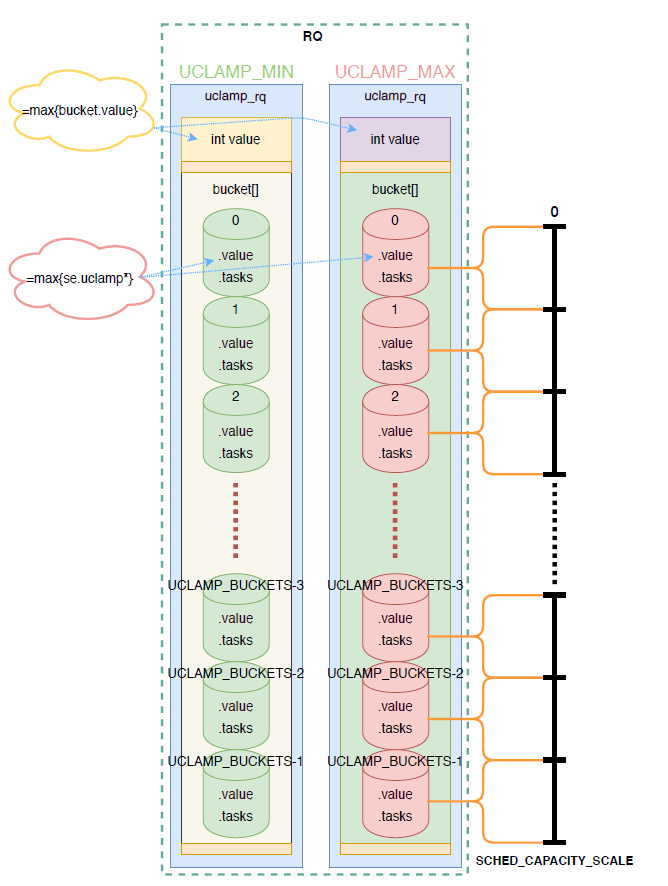
对于一个cpu来说,其运行队列rq上可能同时存在几个task(running/runnable),那么如何计算cpu的util_min和util_max则非常关键。uclmap使用桶化算法实现这种计算。将[0 SCHED_CAPACITY_SCALE]划分为UCLAMP_BUCKETS个区间,每个区间看作一个桶,桶具有两个成员value、tasks,
存在UCLAMP_MIN、UCLAMP_MAX两个桶集合,rq上所有task的uclamp_min值放入UCLAMP_MIN桶集合、uclam_max值放入UCLAMP_MAX桶集合。多个任务位于同一个桶内,桶的值按最大值聚合原则,即由uclamp值最大的task决定。桶与桶之间同样按最大值聚合原则,即cpu的uclamp值由value值最大的桶决定。这样可以保证高性能任务其性能需求始终能够得到满足。
用户通过uclamp机制可以向内核调度器提供task相关信息辅助调度器更好的执行调度任务,使得对频率的调整更加合理、对核心的选择更加贴合任务的性质,最终使得整个系统在性能和功耗上均能实现收益。https://www.linuxplumbersconf.org/event/2/contributions/128/https://lore.kernel.org/lkml/20181029183311.29175-1-patrick.bellasi@arm.com/https://lore.kernel.org/lkml/20190115101513.2822-4-patrick.bellasi@arm.com/LPC18_UtilClamp_v5.pdf