




Oracle中分组聚合函数是经常会用到的,尤其在做数据统计时,灵活运用可以满足不同的统计需求。
一、聚合函数
聚合函数比较简单,只需明白其作用即可,常用的聚合函数包括:
SUM(DISTINCT|ALL)--求和:ALL表示对所有值求和,DISTINCT表示只对不同值求和,缺省为ALLCOUNT(DISTINCT|ALL)--求数据条数:ALL对所有做统,DISTINCT只对不同值统计(相同值只取一次),缺省为ALLAVG(DISTINCT|ALL)--求平均值:ALL表示对所有值求平均值,DISTINCT表示只对不同的值求平均值,缺省为ALLMAX(DISTINCT|ALL)--求最大值:ALL表示对所有的值求最大值,DISTINCT表示对不同的值求最大值,缺省为ALL(加不加查询结果一样)MIN(DISTINCT|ALL)--求最小值:ALL表示对所有的值求最小值,DISTINCT表示对不同的值求最小值,缺省为ALL(加不加查询结果一样)STDDEV(DISTINCT|ALL)--求标准差:ALL表示对所有的值求标准差,DISTINCT表示只对不同的值求标准差,缺省为ALLVARIANCE(DISTINCT|ALL)--求协方差:ALL表示对所有的值求协方差,DISTINCT表示只对不同的值求协方差,缺省为ALLMEDIAN()--求中位数:对所有的值求中位数,没有DISTINCT选项!!!复制
二、分组函数
分组函数常与聚合函数搭配灵活使用,包括:group by、grouping sets()、rollup()、cube(),下面分别介绍其用法。
在数据库中建一张测试表,数据如图所示:
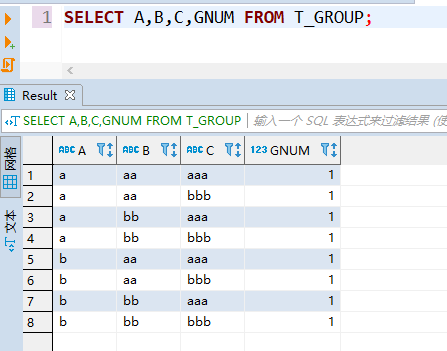
1、group by
group by是最基础的分组函数,只有一种分组情况(注意clob类型字段不能分组)。
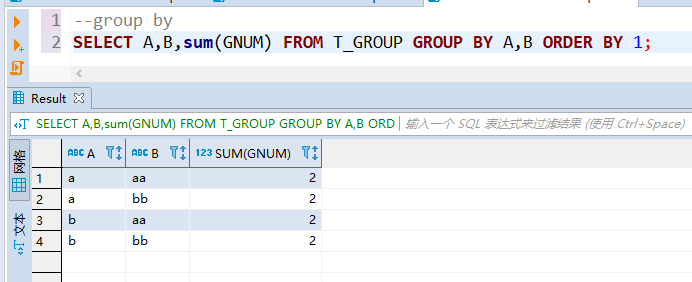
2、grouping sets()
grouping sets()是对多列单独分组,有N列则进行N次分组。
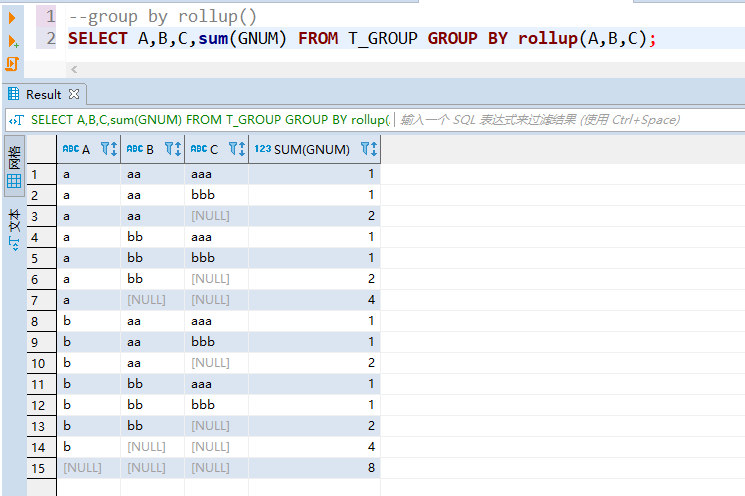
3、rollup()
rollup()是累计累加分组,有N列数据会进行N+1次分组。例如:
rollup(A,B,C) = group by A +group by A,B + group by A,B,C + group by null复制
可以看出,字段的顺序是会对结果产生影响的,即:
rollup(A,B) <> rollup(B,A)复制
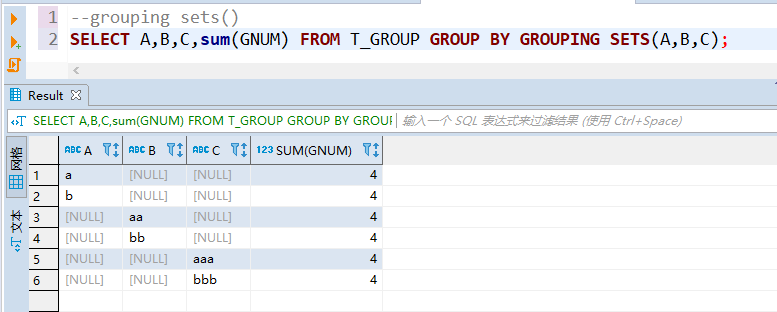
数据库中测试结果如下:
4、cube()
cube()是交叉列表分组,有N列数据会进行2^N次分组,例如:
cube(A,B) = group by A +group by B +group by A,B + group by null复制
因此cube()中字段顺序不会对结果产生影响,数据库中测试结果如下:

三、扩展列
扩展列能够方便我们对分组后的结果进行处理,在分组统计中也十分有用,主要有:GROUPING()、GROUPING_ID()、GROUP_ID(),下面分别介绍一下。
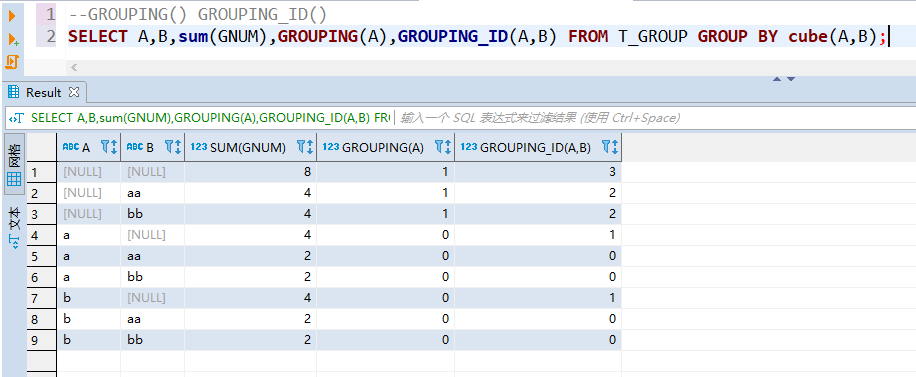
1、GROUPING()、GROUPING_ID()
这两个扩展列主要用于判断分组结果中分组列是否为空以及为空的数量(也可以理解为判断结果中该行数据是否有对指定列进行分组),grouping()值的规则为:
A列为空(未对A列分组):grouping(A) = 1A列为非空(有对A列分组):grouping(A) = 0复制
grouping_id()是对grouping()的“合计”,其计算值是二进制数,显示的是十进制数,例如某行结果中A列为空,B列为非空,则grouping(A) = 1,grouping(B) = 0,计算grouping_id(A,B) = 1 + 0 = 10,其中10是二进制数,而结果显示为2(十进制)。
在数据库中测试这两个扩展列:
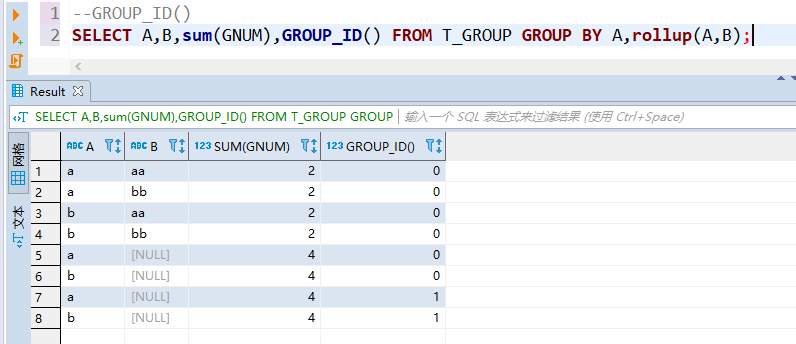
2、GROUP_ID()
group_id()没有参数,是用来标识重复分组次数,因为在一些情况下可能会对某一种分组进行了重复统计,可以通过限定group_id()<1来剔除重复分组数据。
四、用例
对于一些有层级关系的组织,常常需要根据最底层的数据统计各个层级的汇总数据,如下表所示:
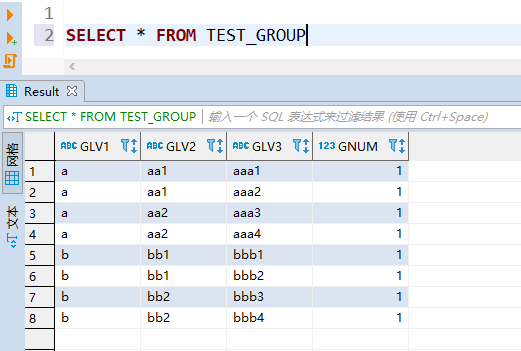
统计语句可参考如下:
SELECTCASE WHEN GROUPING(GLV2)=1 THEN GLV1WHEN GROUPING(GLV3)=1 THEN GLV2WHEN GROUPING(GLV3)=0 THEN GLV3END org_id,sum(GNUM)FROM TEST_GROUPGROUP BY rollup(GLV1,GLV2,GLV3)ORDER BY 1;复制
统计结果:

