Excel power query两表核对

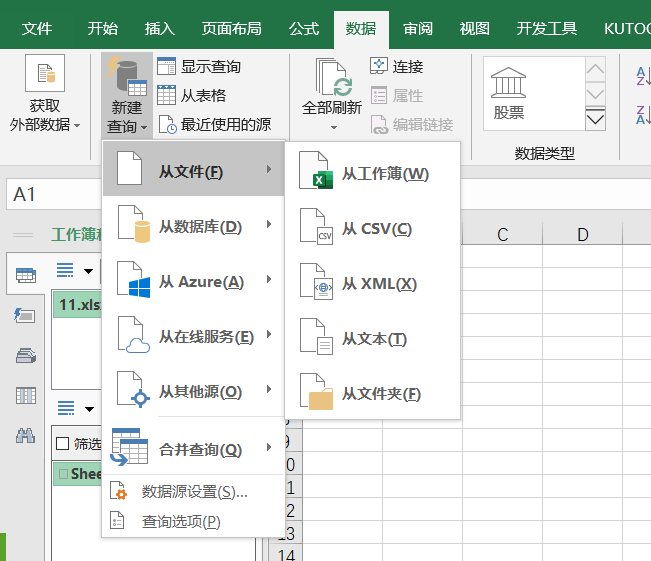
原始数据加载完后,我们选择query的主页里的组合中的合并查询

合并查询里有个合并查询、将查询合并为新查询

点击合并查询后,弹出合并设置窗口,选择两个原始表的查询,并点选连接字段。
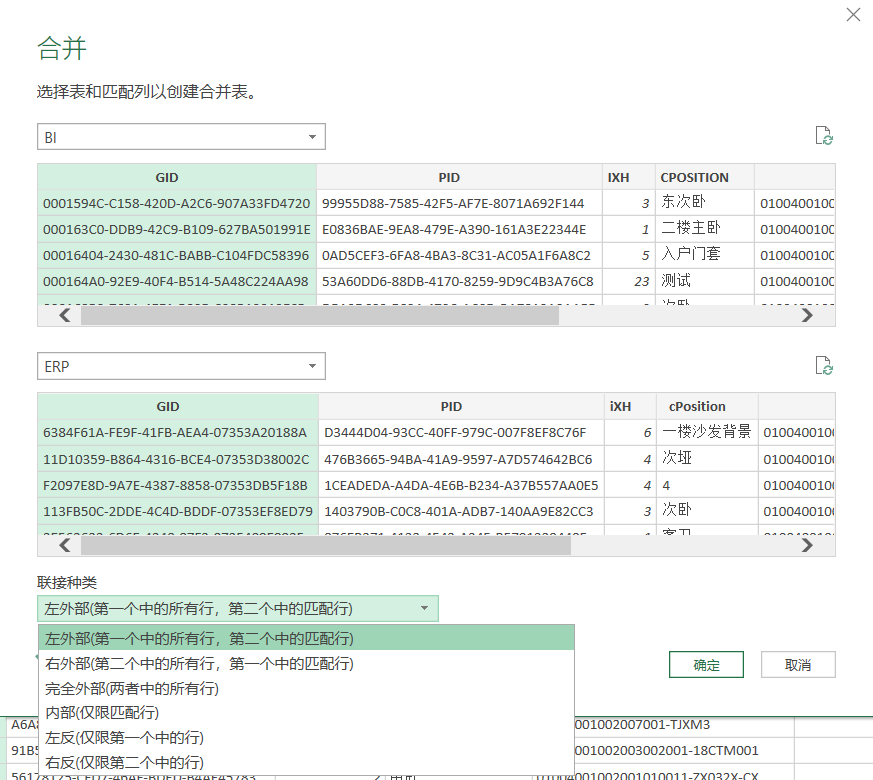
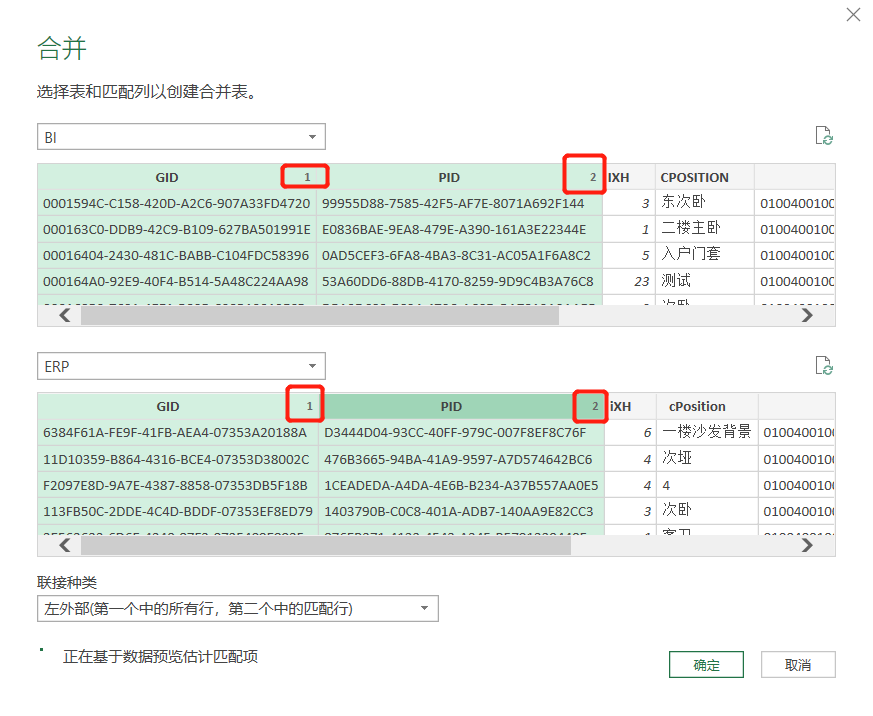
选择完连接的字段之后,我们需要设置他们的连接种类。共有6种连接设置。上面的解释也很清楚明白。
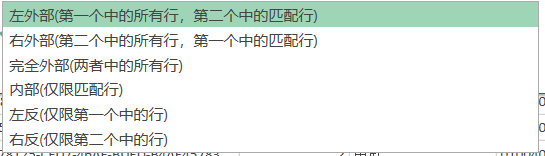
选择连接方式之后,它会显示连接的匹配行数。

两表连接完成之后,关联的数据会存储在一新的列里
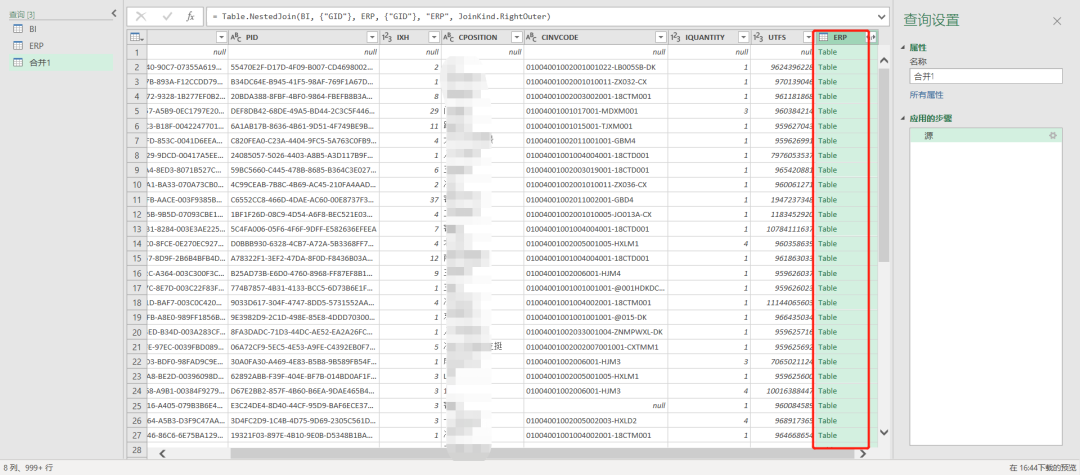
点击这个table,它会显示跟当前数据关联的数据明细
如果关联的数据有多条如下图所示
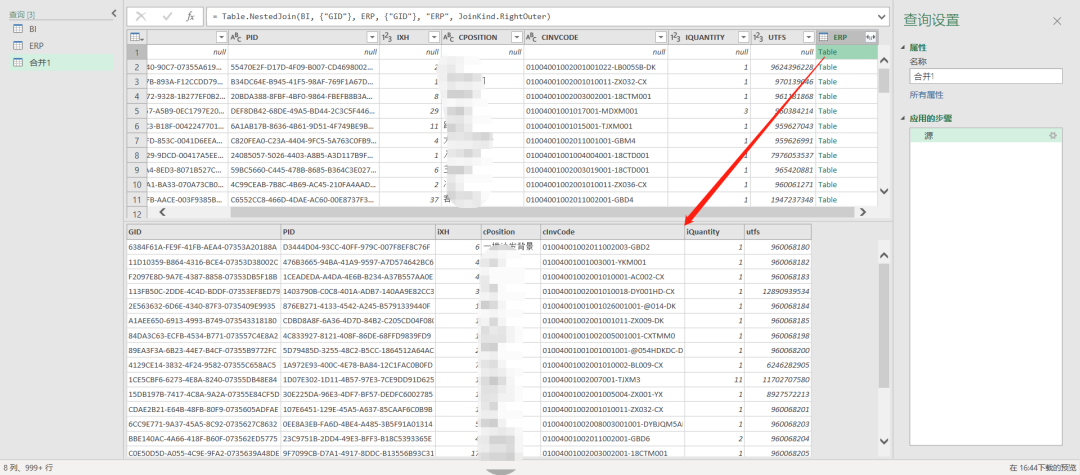
单条数据如下图所示
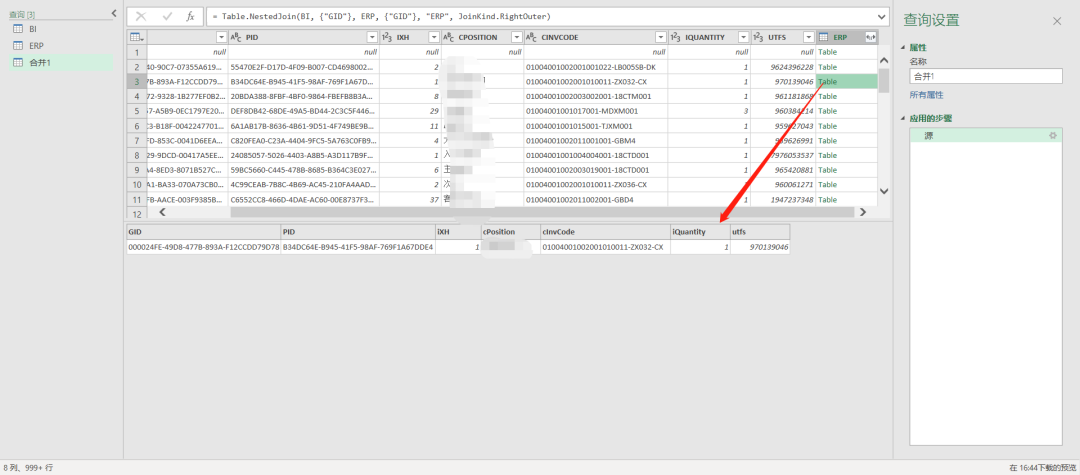
点击这个合并列的右上角的符号 ,可以对数据进行展开。
,可以对数据进行展开。
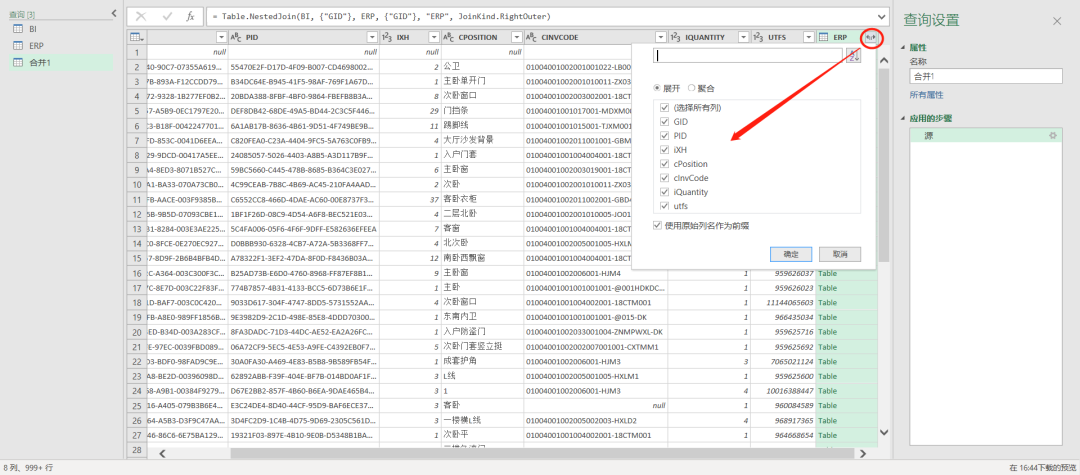
展开时可以选择展开(明细数据),聚合(汇总数据),还可以选择原始列名作为展开后的列名的前缀。
展开之后我们就可以针对要核对的列进行值比对了。
在这里我们引申一下,简单介绍下query函数
点击主页菜单里高级编辑器,或者点击右侧应用步骤里的源,我们可以看到在公式栏里的query函数。

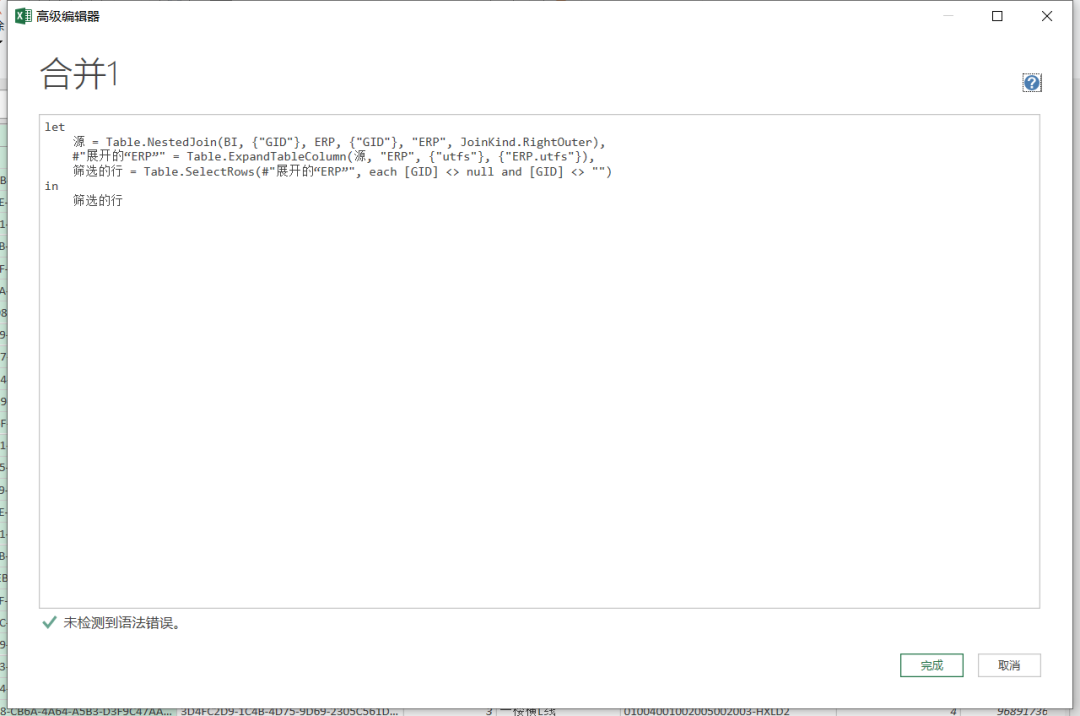
在这里它使用的是Table.NestedJoin函数
https://docs.microsoft.com/zh-cn/powerquery-m/table-nestedjoin
在官方文档里的介绍如下
Table.NestedJoin(table1 as table,
key1 as any,
table2 as any,
key2 as any,
newColumnName as text, optional
joinKind as nullable number, optional
keyEqualityComparers as nullable list) as table
= Table.NestedJoin(BI, {"GID"}, ERP, {"GID"}, "ERP", JoinKind.RightOuter)
我们对比官方介绍和我们通过视窗操作自动生成的函数来了解这个函数。
table1 as table:选择表格1(也就是查询生成的结果表),我们选择的是BI
key1 as any : 选择任意格式的关键字段。我们选择的是BI表里的GID字段。它需要用列表形式展示。{"GID"},大括号就是query的列表
table2,key2同上
newColumnName as Text :设置文本格式的新列名。它会把关联生成的数据存储在这个列里。我们的例子中就是ERP列。
optional joinKind as nullable number :可选择的连接类型。连接的在上面的截图里我们介绍过了。这里我们在介绍下它的参数名称。在query函数列表里有下面这几个
JoinKind.FullOuter :全外连接 JoinKind.Inner : 内连接 JoinKind.LeftAnti : 左反 JoinKind.LeftOuter :左外连接 JoinKind.RightAnti :右反 JoinKind.RightOuter :右外连接
pandas两表核对
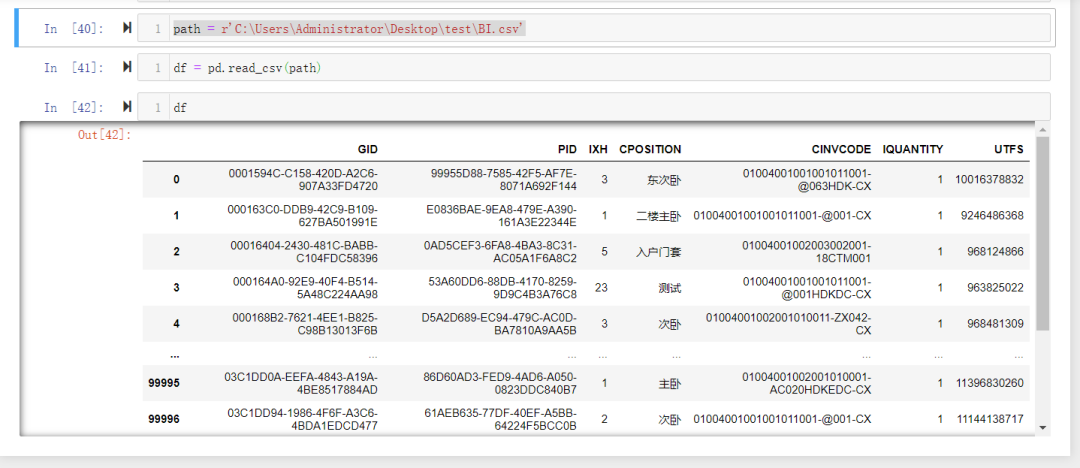
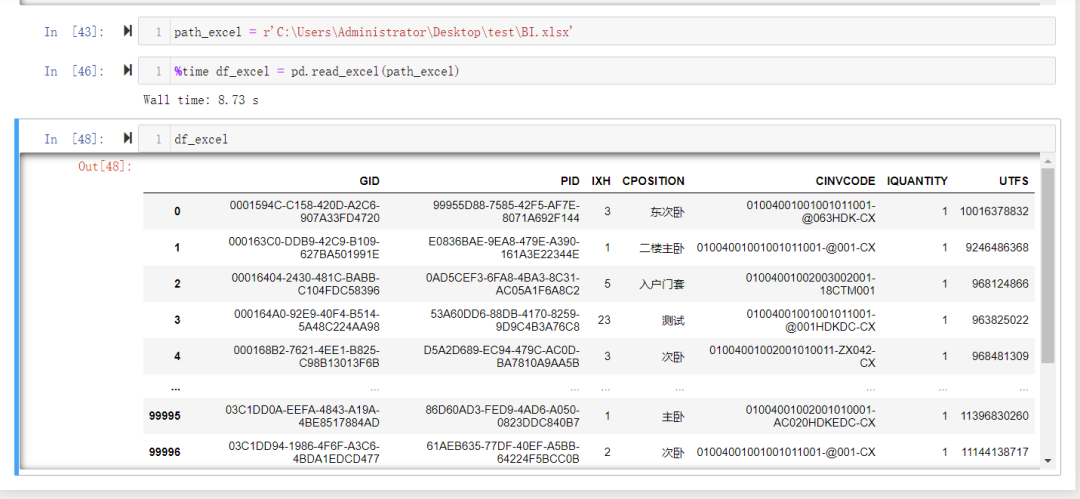


读取完数据之后我们如何去进行比较呢?
我们先来看看读取完的数据是什么类型的.
通过.info()方法可以看到数据显示为DataFrame格式。其实这正是我们用pandas的read方法读取数据的原因,它读取完就是DataFrame格式,而无需另行转换。
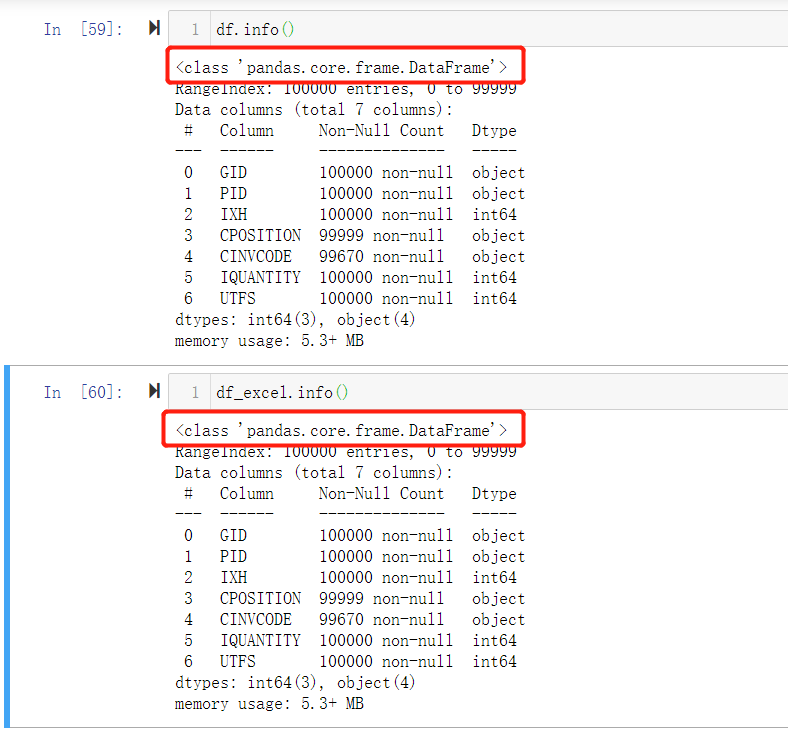
DataFrame可以简单理解为一个二维表,有行有列。
然后我们看看pandas文档对于merge方法的介绍,在第4章节里介绍的就是merge,join和concatenate。
concatenate可横向连接,也可纵向连接。功能强大,使用百变
merge是数据库风格的连接,也就是我们在query中介绍的合并查询的那几种。被介绍为类似数据库sql连接类型的功能强大、高性能的内存连接操作。
上面这是merge方法的参数
left为左侧表,right为右侧表(其实也可以是series,DataFrame类型的单维表,可以简单理解为一行或者一列)
how:是两边的连接方式。 'left'
, 'right'
, 'outer'
, 'inner'
。它这里有四种选项。
on:连接的列或者索引级别名称,是必须同时存在于两个表里的。如果没有找到连接的名称,那么左右两表的交集将被当做连接字段。
(DataFrame结构有索引和列的概念,索引可以为多层,可以简单理解为excel透视表的行分组。)
left_on和right_on:如果on参数不设置或者没有同名的存在。那么可以分别在这俩参数里指定左右两表的连接字段名称。
left_index和right_index:如果为TRUE,那么基于两表的索引建立连接
suffixes:用于设置两表重叠字段的名称的。默认是('_x','_y'),分别给左表重叠字段名称添加后缀_x,给右表添加_y
indicator:如果为True,则产生一列名为"_merge"的列,它的值为left_only(左表独有),right_only(右表独有),both(两表都有)。这3个值的出现是根据how的值来定的。
了解了merge的用法,我们就可以用它来查找左表、右表独有的内容了。
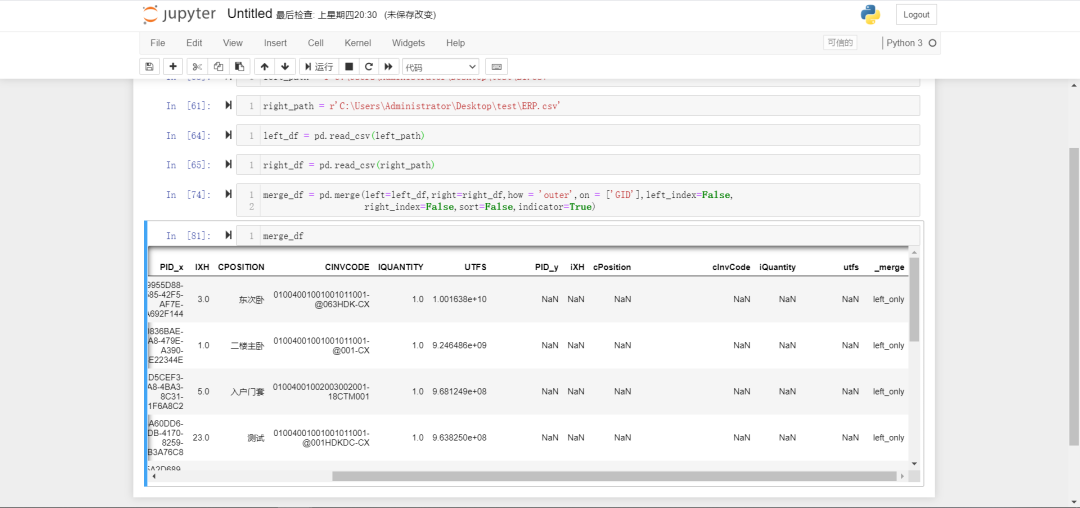
merge_df = pd.merge(left=left_df,right=right_df,how = 'outer',on = ['GID'],left_index=False,
right_index=False,sort=False,indicator=True)
这里我们只需要一行代码就完成了两表的比对。下图可见我们比对后生成的数据。PID这个重复的列名各自加了后缀。其他列名因为大小写不同而不认为相同。在最后有一个_merge列

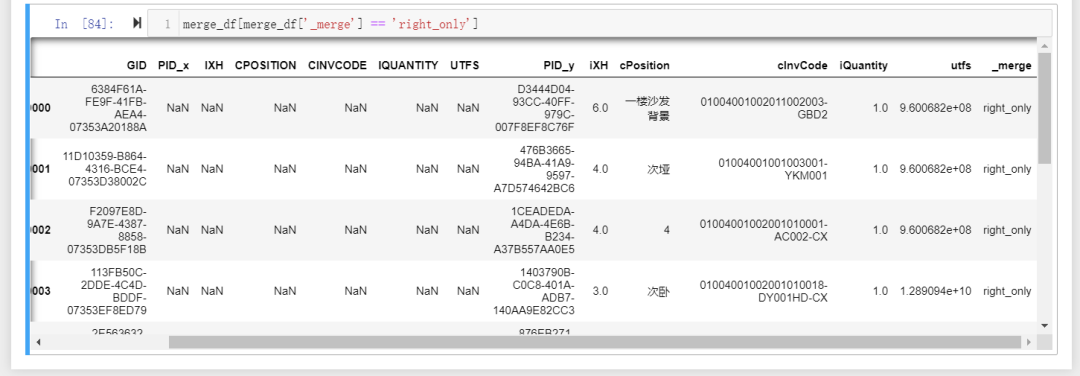
可通过merge_df[merge_df['_merge'] == 'right_only']来筛选right_only的列
merge_df[merge_df['_merge'] == 'right_only'].to_excel('right_only.xlsx')
这行代码可以将过滤结果输出为excel文件。