




具体可见↓
第零部:环境配置介绍



第一部:拆分单列到多行
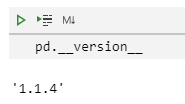
import pandas as pddata_path = r'C:\Users\11631\Desktop\data.xlsx'data = pd.read_excel(data_path,names=['产品编码','颜色编码'])print(data)复制
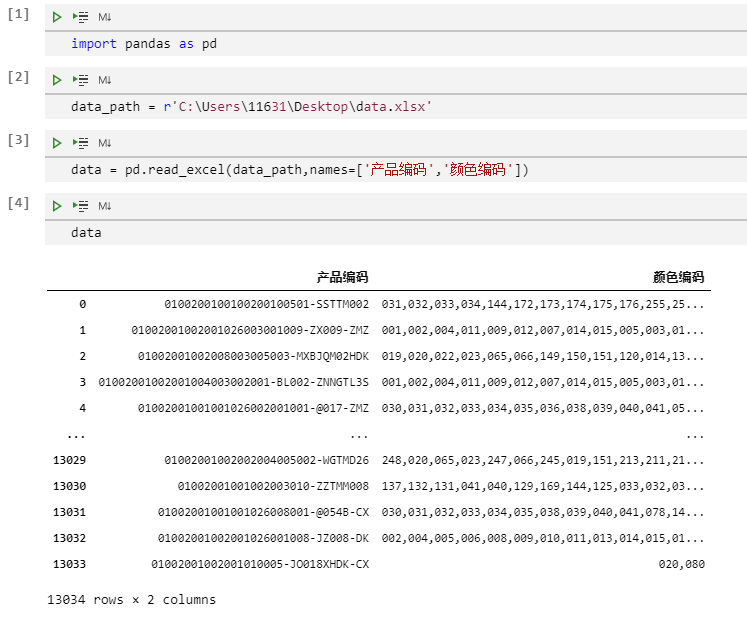
data['颜色编码'] = data['颜色编码'].str.split(',')# split 函数可以对用分隔符分割的文本进行拆分为列表。跟Excel Query 的Text.Split()函数一个作用print(data)复制
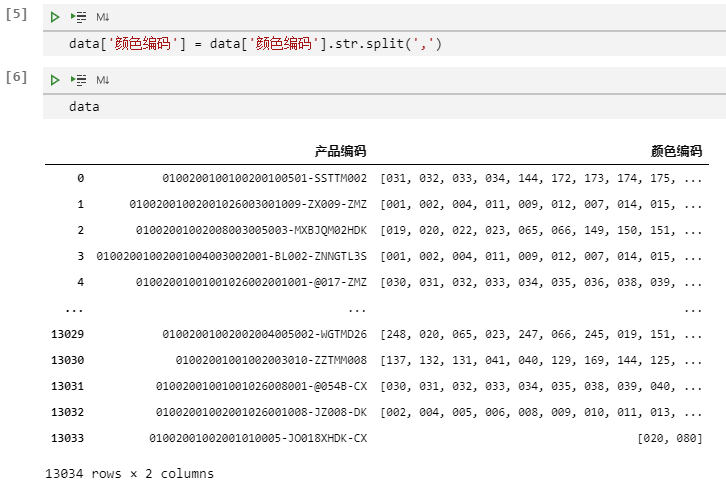
data.reset_index(inplace=True)# reset_index 重置索引列,inplace表示重置后的DataFrame替换原来的复制
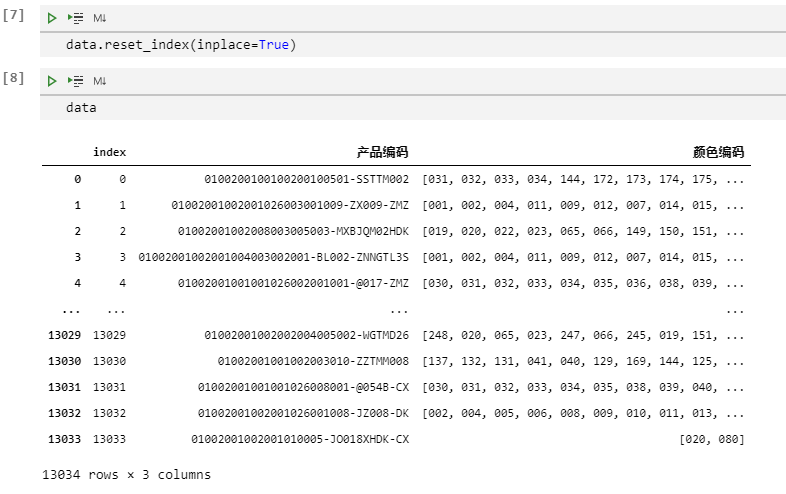
a = data.explode('颜色编码',ignore_index=True)print(a)复制
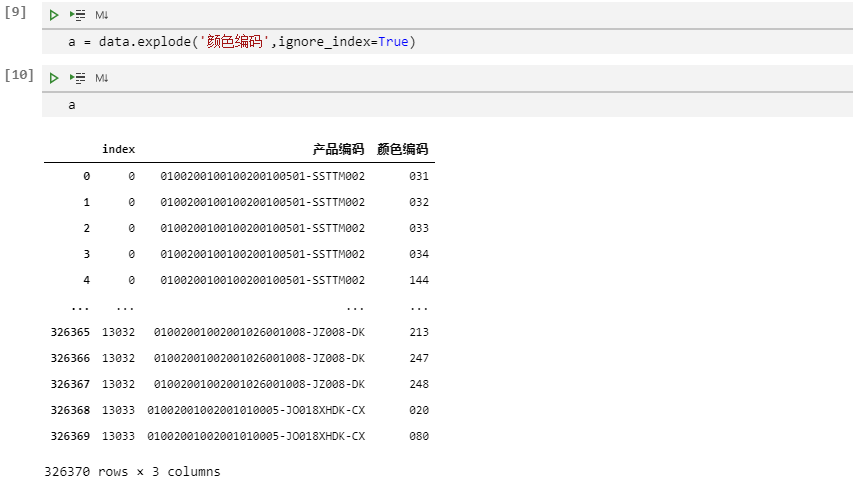
explode
https://pandas.pydata.org/pandas-docs/stable/user_guide/reshaping.html#exploding-a-list-like-column )
)
DataFrame.explode(column, ignore_index=False)
assign的操作等同于data['颜色编码'] = data['颜色编码'].str.split(',') ,它可以给DataFrame重新分配一个新列(可以是新列,也可以覆盖原来的列)

嗯。这么几行代码就搞定了拆分列到多行。
第二部:合并多行到列
b = a.groupby(by=['index','产品编码']).apply(lambda x:','.join(x['颜色编码'])).reset_index().rename(columns={0:'颜色编码'})print(b)复制

下面我们来逐步拆解下这一行代码都干了些啥!
groupby的作用,在pandas的文档中有专门的一章来介绍这个分组汇总-拆分-合并。由此可见,这个数据的分组汇总-数据拆分-数据合并的使用还是很普遍的。
https://pandas.pydata.org/pandas-docs/stable/user_guide/groupby.html
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True,group_keys=True,squeeze=<object object>, observed=False, dropna=True)
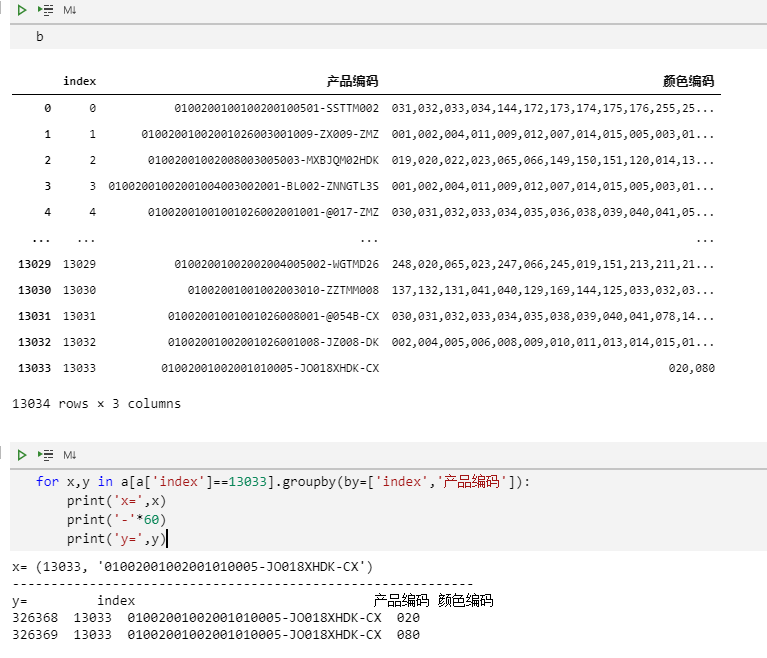
搞清楚了groupby之后的结果集的样子,我们就更好的可以理解下面这段代码执行的意思了。
.apply(lambda x:','.join(x['颜色编码']))复制
join()是字符串连接函数。它可以把列表通过分隔符串联成一个字符串。如下图所示效果
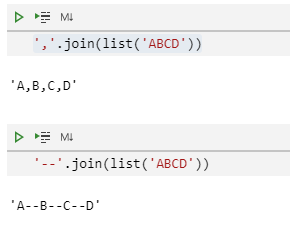
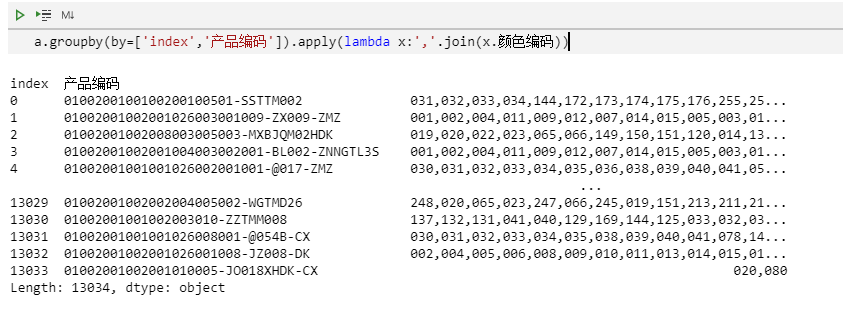
分组合并,然后把合并形成的表格子集中的颜色编码列合并成一个字符串后形成的结果集如下图所示
我们将它重建索引
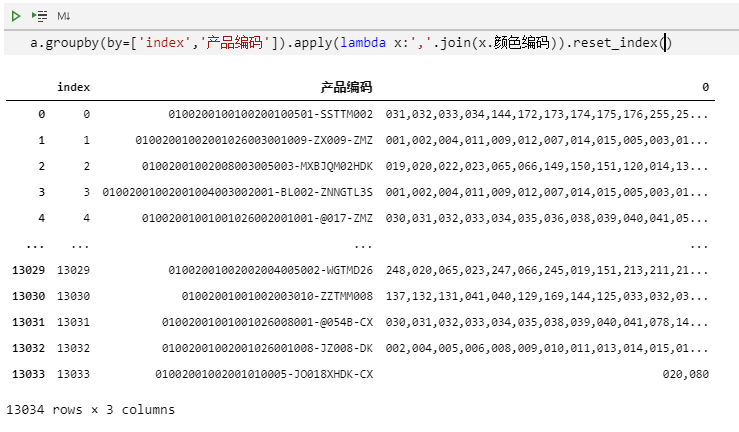
然后对重建索引后的列名进行重命名

这样我们就又把分拆之后的数据集合并回来了。
整个过程我们所写代码不过10行不到,所耗时间也不过分分钟而已!
用python来拆分数据的好处在于它的速度优势,1万多行的表拆分后变成了32万多行。如果数据集再大点,那么Excel Query就会非常卡。我之前用query拆分合并一个拆分后达到400万行的数据集耗费了我一下午时间,一直在转圈圈、圈圈、圈……而用Python来处理的话不过十分钟左右的事,这就是Python处理大数据集的速度优势。
人生苦短,我用Python!
一切皆是信息,万物源自比特!
文章转载自龙小马的数字化之路,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
