积压缓冲区的维护
积压缓冲区的创建
在Master实例的一侧,Redis会维护一段连续分配的内存作为积压缓冲区,用于存储近期被同步给Slave的命令,以便当连接断开重连时,Redis执行增量的数据同步。初始情况下,Redis不会为积压缓冲区分配内存,当有需要的时候,则会通过下面这个函数来创建一个积压缓冲区:
void createReplicationBacklog(void);
Master实例上会在下面两种情况下通过调用createReplicationBacklog
接口来创建积压缓冲区:
当第一个Slave实例通过PSYNC命令与Master开启同步时,会创建积压缓冲区。
当有Slave实例断线请求重连时,如果积压缓冲区已经被释放,则会重新创建一个积压缓冲区。
由于主从复制支持层次结构,这也就意味着,一个Slave也可能是它的下级Slave的Master,因此在Slave一端也需要维护一段积压缓冲区,当一个Slave通过readSyncBulkPayload
接口开始读取Master的同步数据时,也会通过createReplicationBacklog
来创建一段积压缓冲区。
积压缓冲区的大小通过redisServer.repl_backlog_size
来存储,不过我们可以在运行期通过CONF命令来重新调整Redis的积压缓冲区的大小,下面这个函数用来调整积压缓冲区的大小:
void resizeReplicationBacklog(long long newsize);
不过这函数会清空原有的积压缓冲区,并将关于积压缓冲区的偏移索引等数据清零重置。
积压缓冲区的释放
Redis可以通过调用freeReplicationBacklog
函数来释放积压缓冲区:
void freeReplicationBacklog(void);
在Master一端,如果长时间redisServer.repl_backlog_time_limit
没有Slave与该Master连接,那么便会通过freeReplicationBacklog
来释放自己的积压缓冲区。
而对于Slave一侧,我们知道Redis也会维护一段积压缓冲区,用于处理层次结构的主从复制模式。对于Slave实例,一旦其开始请求PSYNC的数据同步,也就意味着该实例中的所有数据都已经失效,因此对于其积压缓冲区也应该做释放处理;后续会在处理Master发来的同步数据的时候,重新创建积压缓冲区。
积压缓冲区的数据写入
在Master实例中,Master将命令转发给Slave的同时,也会将这份命令数据写入积压缓冲区之中,Redis为积压缓冲区的数据写入提供了两个函数接口:
void feedReplicationBacklog(void *ptr, size_t len);void feedReplicationBacklogWithObject(robj *o);
这两个函数分别用于将一段内存数据写入积压缓冲区以及将一个对象数据结构robj
写入解压缓冲区。由于Redis之中积压缓冲区是一个循环缓冲区,当缓冲区已经被写满,新的数据将会从积压缓冲区的起始位置重新进行写入。而这一步操作会导致Master实例之中的复制偏移量redisServer.master_repl_offset
的更新:
void feedReplicationBacklog(void *ptr, size_t len){server.master_repl_offset += len;//向循环积压缓冲区之中写入数据...if (server.repl_backlog_histlen > server.repl_backlog_size)server.repl_backlog_histlen = server.repl_backlog_size;server.repl_backlog_off = server.master_repl_offset - server.repl_backlog_histlen + 1;}
从上面的代码片段我们可以看出,如果我们把服务器启动时的命令执行的初始状态设置为0的话,那么redisServer.master_repl_offset
这个复制偏移量可以理解为Master实例上最后一条被执行的查询命令相对于服务器启动时初始状态的一个偏移量;而redisServer.repl_backlog_off
这个积压缓冲区偏移量则可以认为是积压缓冲区之中的第一个数据相对于初始状态的偏移量,二者的差值便是积压缓冲区之中数据的大小。
Master实例在向Slave实例转发查询命令的接口replicationFeedSlaves
之中,会执行前面向积压缓冲区之中追加数据的逻辑:
void replicationFeedSlaves(list *slaves, int dictid, robj **argv, int argc) {if (server.slaveseldb != dictid){//需要在积压缓冲区之中追加一条SELECT命令,用于切换数据库IDrobj *selectcmd;...if (server.repl_backlog)feedReplicationBacklogWithcObject(selectcmd);}...if (server.repl_backlog){char aux[LONG_STR_SIZE+3];aux[0] = '*';len = ll2string(aux+1,sizeof(aux)-1,argc);aux[len+1] = '\r';aux[len+2] = '\n';feedReplicationBacklog(aux,len+3);for (j = 0; j < argc; j++) {long objlen = stringObjectLen(argv[j]);aux[0] = '$';len = ll2string(aux+1,sizeof(aux)-1,objlen);aux[len+1] = '\r';aux[len+2] = '\n';feedReplicationBacklog(aux,len+3);feedReplicationBacklogWithObject(argv[j]);feedReplicationBacklog(aux+len+1,2);}}...}
积压缓冲区的数据请求
long long addReplyReplicationBacklog(client *c, long long offset);
上面这个函数用于将积压缓冲区之中从指定偏移量offset
开始的有效数据发送给指定的Slave实例,并返回发送数据的长度。这个接口用于函数masterTryPartialResynchronization
之中,用于处理Slave实例的发来的增量数据同步请求。
主从连接的建立
在积压缓冲区这个主从复制功能之中最为基础的模块了解之后,我们来看一下Master实例与Slave实例之间是如何建立连接的。
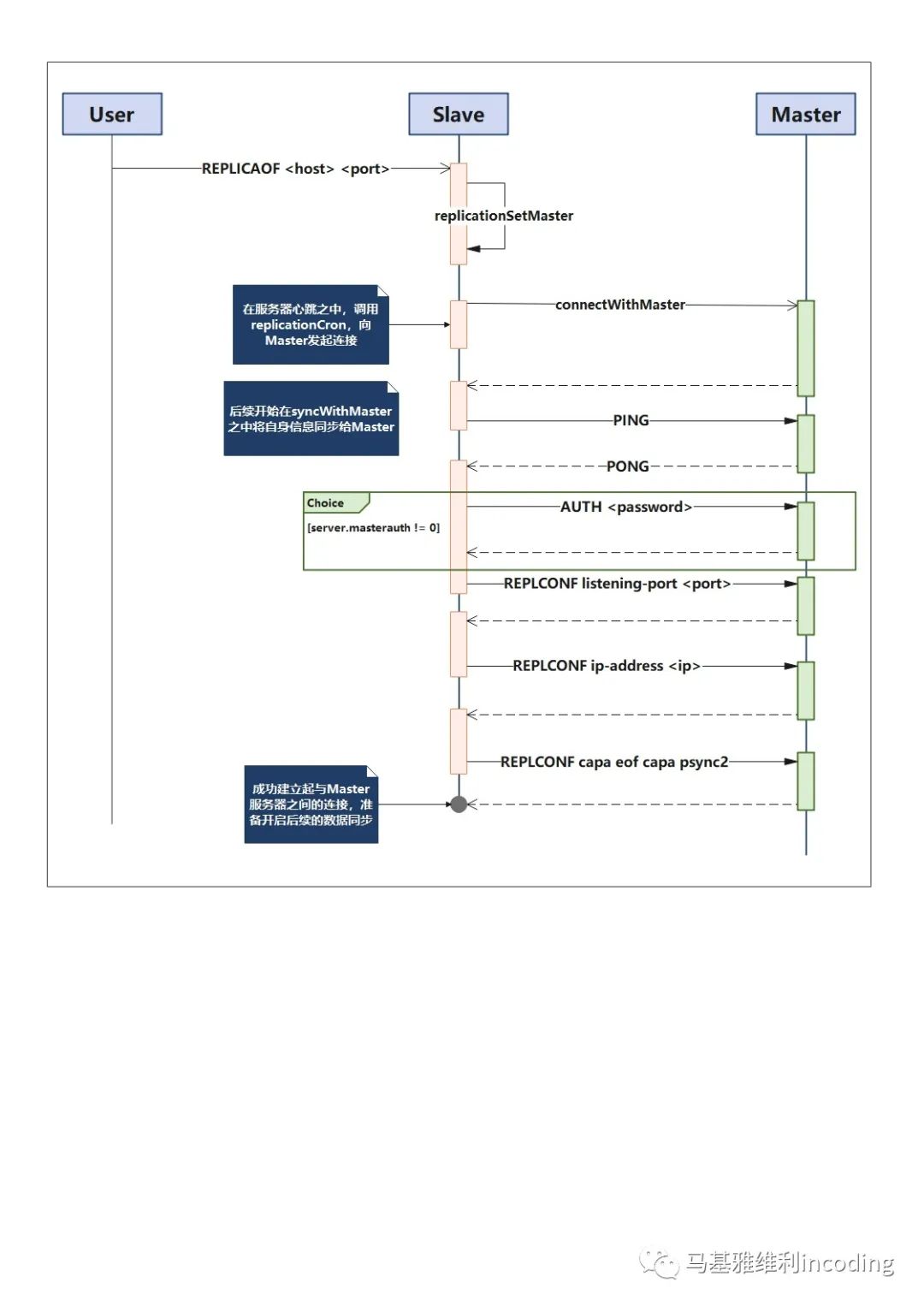
由于主从复制是Slave实例主动发起的连接,因此我们先来看Slave实例一端,Slave可以通过REPLICAOF命令来建立与Master实例的连接,这个命令有两种形式:
REPLICAOF no one
REPLICAOF <host> <port>
第一种形式,用于解除当前实例在主从复制之中的Slave角色,将其转换为一个独立的可以进行写操作的Redis服务器实例。
第二种形式,用于将一个实例设置为某一个给定Master的Slave实例。
void replicaofCommand(client *c);
上面这个命令处理函数会解析客户端命令的参数,分别处理上面的两种解除主从复制以及建立主从复制的过程。
解除主从复制,是通过下面这个replicationUnsetMaster
函数进行的:
void replicationUnsetMaster(void);
这个函数会清空服务器上记录的Master数据信息redisServer.masterhost
,同时释放在Slave一侧代表Master实例的客户端对象redisServer.master
。在这个函数接口里会调用一个shiftReplicationId
:
void shiftReplicationId(void) {memcpy(server.replid2,server.replid,sizeof(server.replid));server.second_replid_offset = server.master_repl_offset+1;//重新为实例生成server.replid复制IDchangeReplicationId();}
我们知道redisServer.replid
之中存储了Master实例的复制ID,在前面对于数据结构的介绍之中,我们发现还有两个字段分别为redisServer.replid2
以及redisServer.scond_replid_offset
,那么这两个看似是复制ID以及复制偏移量的数据是做什么的呢?
在后面我们介绍哨兵模式的时候会讲到,当一组主从复制的Redis实例中Master实例掉线,那么哨兵服务器会从所有的Slave实例之中选择一个实例将其提升为这组实例之中的Matser实例,这里redisServer.replid2
以及redisServer.scond_replid_offset
这两个字段便是为处理这种情况的。当一个Slave实例被提升至Master之后,会为这个实例重新生成一个复制ID,并把原有的上一个Master实例的复制ID转移到redisServer.replid2
上,这样一来,其他的Slave节点可以使用原来的复制ID来向这个新的Master实例来请求数据。
与Master建立连接
而REPLICAOF命令建立与Master实例之间的连接是通过replicationSetMaster
这个函数开始的:
void replicationSetMaster(char *ip, int port){int was_master = server.masterhost == NULL;sdsfree(server.masterhost);server.masterhost = sdsnew(ip);server.masterport = port;if (server.master){freeClient(server.master);}...server.repl_state = REPL_STATE_CONNECT;}
这个函数会设置服务器上记录的Master实例的地址信息redisServer.masterhost
以及redisServer.masterport
两个字段;如果这个服务器曾经是另外一个Master实例的Slave,那么释放掉这个旧的Master客户端,并将当前服务器的状态redisServer.repl_state
设置为REPL_STATE_CONNECT
。
不过这里我们发现replicationSetMaster
函数并没有建立于Master服务器的连接,只是为Slave设置了建立连接所需要的数据。而真正进行连接,建立主从复制的逻辑,是在Redis的专门处理复制机制的心跳函数中进行的:
void replicationCron(void){...if (Server.repl_state == REPL_STATE_CONNECT){connectWithMaster();}...}
这里Redis会检测当前服务器是否处于REPL_STATE_CONNECT
的状态,如果满足条件的话便会调用connectWithMaster
来与Master建立连接的。
int connectWithMaster(void){fd = anetTcpNonBlockBestEffortBindConnect(NULL, server.masterhost, server.masterport, NET_FIRST_BIND_ADDR);aeCreateFileEvent(server.el,fd,AE_READABLE|AE_WRITABLE,syncWithMaster,NULL);server.repl_transfer_lastio = server.unixtime;server.repl_transfer_s = fd;server.repl_state = REPL_STATE_CONNECTING;}
这里建立连接的过程是使用非阻塞connect
的方式发起的,由于非阻塞connect
会立即返回,而此时连接并未真正建立,因此需要监听这个连接套接字上的可读与可写事件,并注册事件处理函数syncWithMaster
;同时将当前服务的状态redisServer.repl_state
设置为REPL_STATE_CONNECTING
状态。
当异步的连接建立成功时,会触发事件处理回调函数syncWithMaster
,这个函数会完成在前面概述之中介绍的,内部发送PING命令检测连接的建立情况;执行内部REPLCONF命令将Slave的配置信息通知Master;最后根据自身的状态,向Master实例发送PSYNC命令,开启数据同步。
对于Master实例来说,这个Slave与一般的客户端没有任何的差异。在Slave实例与Master实例通过PING命令以及PONG返回确认了连接之后,Slave实例将会发起一系列的REPLCONF命令,Master实例收到REPLCONF命令后,会将相应的配置数据设置到代表这个Slave对应的客户端对象client
的相应字段上。
REPLCONF命令的格式为:
REPLCONF <option> <value> <option> <value> ...
这个命令对应的实现函数为:
void replconfCommand(client *c);
这个函数所接收的参数必须是双数,需要满足每一个<option>
就需要对应的<value>
。REPLCONF这个命令的实现函数比较简单,解析参数之中的<option>
,并根据<option>
的不同,将对应的<value>
设置到client
结构体的对应字段上。那么REPLCONF命令可以接受的<option>
有:
listening-port
,用于设置Slave实例上对应client.slave_listening_port
的字段信息,存储Slave实例监听的端口数据。ip-address
,用于设置Slave实例上对应client.slave_ip
的字段信息,存储Slave实例监听的IP数据。capa
,用于设置Slave实例上对应client.slave_capa
的字段信息,存储这个Slave实例支持的capa
数据:SLAVE_CAPA_EOFSLAVE_CAPA_PSYNC2ack
,Slave用于向Master实例发送ACK数据,用于通知当前已经处理的同步数据的数量,通知的数据会被记录到对应客户端client.repl_ack_off
字段上,另外也会更新对应客户端client.repl_ack_time
的时间戳。getack
,上面ack
是服务器内部使用的命令,由Slave实例自动发送;而这个getack
则是在Slave实例一侧被执行的,显式地要求Slave实例向Mater实例发送一次ACK数据。
之所以建立连接的过程需要在replicationCron
心跳函数之中进行,而不是执行REPLICAOF命令时立刻执行。这种方式有一个优点,一旦出现了Slave与Maste断开连接的情况,那么在replicationCron
心跳函数之中,会检测连接状态并在断开连接的情况下,重启通过调用connectWithMaster
来建立连接。
下面这个序列图所展示的,便是在主从机制之中,Slave实例是一步一步与Master实例建立连接的: