




案例:选择合适的分布列
现象描述
表定义如下:
1 2 | CREATE TABLE t1 (a int, b int); CREATE TABLE t2 (a int, b int); |
执行如下查询:
1 | SELECT * FROM t1, t2 WHERE t1.a = t2.b; |
优化分析
如果将a作为t1和t2的分布列:
1 2 | CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a); CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (a); |
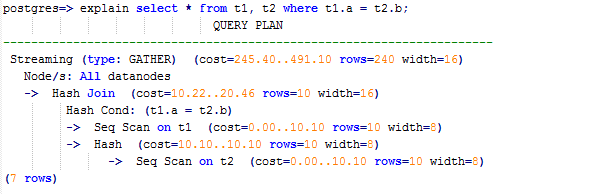
则执行计划将存在“Streaming”,导致DN之间存在较大通信数据量,如图1所示。
图1 选择合适的分布列案例(一)

如果将a作为t1的分布列,将b作为t2的分布列:
1 2 | CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a); CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (b); |
则执行计划将不包含“Streaming”,减少DN之间存在的通信数据量,从而提升查询性能,如图2所示。
图2 选择合适的分布列案例(二)
查看更多:华为GaussDB 200 实际调优案例
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
