





PandaDB:一种异构数据智能融合管理系统
沈志宏 , 赵子豪 , 王华进 , 刘忠新 , 胡川 , 周园春
摘 要: 随着大数据应用的不断深入,对大规模结构化 结构化/非结构化数据在存储管理方式、信息获取方式 本文提出了适用于异构数据融合管理和语义计算的属性图 于智能属性图模型提出异构数据智能融合管理系统 PandaDB 询机制、属性协存和 AI 算法集成机制.性能测试和应用 制对大规模异构数据的即席查询和分析具有较好的性能 融合数据管理场景。
关键词: 数据管理系统;异构数据融合;图数据模型;即席查询
中图法分类号: TP311
中文引用格式: 沈志宏,赵子豪,王华进,刘忠新,胡川,周园春.PandaDB:一种异构数据智能融合管理系统.软件学报,2021, 32(3):1-18. http://www.jos.org.cn/1000-9825/6180.htm
英文引用格式: Shen ZH, Zhao ZH, Wang HJ, Liu ZX, Hu C, Zhou YC. PandaDB: An intelligent management system for heterogeneous data. Ruan Jian Xue Bao/Journal of Software, 2021,32(3):1-18 (in Chinese). http://www.jos.org.cn/1000-9825/ 6180.htm
01
引 言
在大数据时代,随着各类应用的推广使用,数据产生速度越来越快、数据体量越来越大。一方面,数据采集技术的迅猛发展使得数据的结构更多样、种类更丰富。数据表现出多元异构的特点,非结构化数据在其中占有较大比重。有研究表明,视频、音频、图片等非结构化数据占据高达90%的比例;另一方面,近年来,数据中台、 知识图谱等数据管理分析技术得到了广泛的应用。数据中台要求结构化/非结构化数据能够在统一的环境中得到良好的治理,以便支持多种应用;知识图谱,特别是多模态知识图谱,要求对底层结构化/非结构化数据进行融合关联分析,并支持用户进行交互式查询。这些技术均提出对结构化/非结构化数据进行融合管理和分析的需求。
结构化数据通常具有较为规范、统一的形式。目前,针对结构化数据的管理和分析,已具有成熟的数据模型、查询语言和管理系统。与结构化数据相比,非结构化数据的管理方式存在着诸多差异,这给高效的结构化/非结构化数据的融合管理和分析带来了多方面的挑战:
(1) 分离的存储管理方式,给结构化/非结构化数据的统一管理带来挑战。相对于结构化数据,非结构化数据占有更大的空间,出于读写效率考虑,非结构化数据往往单独存在于文件系统,或者对象存储系统,这使得维护结构化/非结构化数据一致性的难度增大;
(2) 差异化的信息获取方式,给结构化/非结构化数据的统一分析带来挑战。相对于结构化数据,非结构化 数据内容比较复杂,为了实现高效检索和分析,往往需要预先引入模式识别、深度学习等方法实现信 息抽取和数据挖掘,从而获取非结构化数据所蕴含的内在信息;
(3) 不一致的检索方式,给结构化/非结构化数据的一致化即席查询带来挑战。与结构化数据具有较为成 熟的 SQL、类 SQL 查询语言的现状不同,非结构化数据的信息检索往往缺乏统一的操作模式和查询语法,目前采用的多是逐案的个性化方案。
为实现结构化/非结构化数据的融合管理和分析,需要从模型层面出发,设计统一的表示和查询方法。传统的关系模型、属性图模型不能有效揭示和表示非结构化数据的内在信息。有学者提出将数据和Schema表示为边标记图,以此替代非结构化数据底层类型约束的缺失。但该方法仅提出一种为非结构化数据添加Schema的方法,不能实现对非结构化数据中信息的自由检索。Li 等人提出从基本属性、语义特征、底层特征和原始数据等四个角度定义非结构化数据,但这种方法依赖于预定义,并不适用于非结构化数据的交互查询。近年来有学者提出在非结构化数据流上抽取RDF三元组的方法,该方法只实现了三元组的抽取,不能支持对非结构化数据内在信息的交互式查询,且并不具备数据管理系统的基本能力。
另外一种融合管理的路线是将非结构化数据在数据库中存储为二进制大对象(BLOB,Binary Large OBject),当应用获取数据的时候,返回一个二进制数组或者数据流。这种方法在性能和功能上都不令人满意。针对此问题,研究人员提出了一系列非结构化数据管理系统,这些系统综合考虑了非结构化数据体积大、 结构复杂的特点,设计了合适的存储模型,一定程度上解决了非结构化数据的存储和管理问题,但其提供的查询服务仅基于文件对象本身和元数据,不能提供对非结构化数据内在信息的查询能力。
由此,本文提出属性图扩展模型及其查询方法。属性图扩展模型在传统属性图的基础增加了对非结构化数据内在信息的表示能力,以及结构化和非结构化数据之间的互操作能力。在此基础上,本文继而提出基于智能属性图模型的异构数据智能融合管理系统 PandaDB。本文在第2节给出属性图扩展模型和相关概念,包括层叠属性图、智能属性图、次级属性等,并提出属性操作符和查询语法。在第3节中给出PandaDB的系统设计与具体实现。在第4节中通过实验和案例验证该系统的效率及可行性。第5节介绍与本文研究相关的工作。最后,对未来研究可能面临的挑战进行展望。
02
概念设计
传统属性图模型无法有效表示非结构化属性,本节提出属性图扩展模型,以解决非结构化属性的有效表示问题,然后介绍针对属性图扩展模型的语义操作和查询语法设计,以支持因引入非结构化属性及其内在信息所 带来的新的查询特性。
2.1 属性图扩展模型
传统属性图模型可以形式化表示为 G=(V,E,P) ,其中G表示全体数据,V表示数据中的实体集合,E表示实体间的关系集合,P 表示数据集中实体的属性集合。
针对图片、语音、文本这样的非结构化属性,属性图模型无法有效揭示其蕴含的内在信息(如:某类顶点 的 photo 属性蕴含有“车牌号”信息),内在信息通常是离线且具有结构延迟的:
离线:将非结构化属性转化为结构化、半结构化属性的信息抽取过程,属于对数据的预处理;
结构延迟:非结构化属性的内在信息不具备明确定义的结构,而是根据应用的后期需要从而选择特定的信息抽取方法,这种结构是不明确的、延迟定义的。
为增强对结构化属性、非结构化属性的统一表示能力,本文针对属性图模型进行了扩展,提出层叠属性图模型和智能属性图模型。
定义 2-1:

定义 2-2:

定义 2-3:

作为示例,图1示出一个智能属性图,图中存在一个Car类型的顶点 car1,其具有一个智能属性photo,执行展开操作后,photo 具有两个次级属性:photo->plateNumber 和 photo->model。
 Fig.1 Intelligent Property Graph Model
Fig.1 Intelligent Property Graph Model
图 1 智能属性图模型
2.2 属性操作符
基于定义 2-2,本文定义了针对智能属性的次级属性抽取操作符和语义计算操作符:
次级属性抽取操作符:次级属性抽取操作符“->”用以抽取智能属性的次级属性,如针对photo属性执行“photo->plateNumber”,即可获取到photo中的车牌号;
语义计算操作符:传统属性图查询语言中的谓词(predicate),只支持对属性进行比较,如=、>、<、正则匹配等。本文针对智能属性新增~:,::,:>等拓展谓词,以表示非结构化属性之间的相似关系、相似度、包含关系等逻辑(见表1)。
Table 1 Semantic computation operators
表1 语义计算操作符
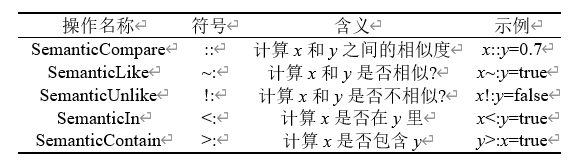
在属性图模型中,由于内在信息的不可见性,非结构化属性之间的计算操作支持有限。结合定义1~定义3中关于非结构化属性的表述和属性操作符的特性,智能属性图模型可以实现非结构化属性内在信息的在线获取,且结构是预定义的。
在线:从非结构化属性中获取结构化、半结构化信息(即次级属性)的过程是按需的,无需对非结构化属性进行专门的预处理;
结构预定义:非结构化数据内在信息依赖于schema层面的定义,而非依赖于信息抽取工具的实现。在底层查询机制的支持下,可以实现针对非结构化属性的直接运算。
2.3 查询语法
本文针对智能属性图模型,针对标准化Cypher查询语言进行扩展,形成CypherPlus语言。CypherPlus定义了BLOB属性类型,用以表示非结构化属性的值。CypherPlus同时引入了BLOB字面值、次级属性抽取操作符、语义计算操作符等新特性,从而支持对非结构化属性的表示和语义操作。
(1) BlobLiteral
用于表示非结构化属性的字面值,格式如áschema://pathñ,其中,schema可以为FILE,HTTP(S),FTP(S), BASE64等多种类型.如图2所示.

Fig.2 Grammer definition of BlobLiteral
图2 BlobLiteral语法定义
(2) SubPropertyExtractor
用于表示次级属性的抽取操作,如图3所示,其中,PropertyKeyName为次级属性的名称;
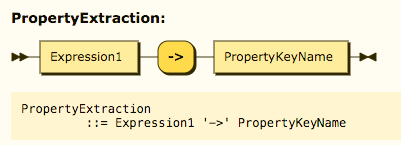
Fig.3 Grammer definition of SubPropertyExtractor
图3 SubPropertyExtractor语法定义
(3) SemanticComparison
语义计算操作符,包括SemanticCompare,SemanticLike,SemanticUnlike,SemanticIn,SemanticContain等操作符。以SemanticLike为例,它用以指示两个属性的值是否相似,语法定义如图4所示,其中,AlgorithmName为指定计算的算法名称,Threshold为阈值,AlgorithmName和Threshold为可选项,该情况下执行引擎则采用默认的比较器和阈值。

Fig.4 Grammer definition of SemanticLike
图4 SemanticLike语法定义
例如,针对图1的数据模型,可以查找与车牌号为HHMF442的车相似的车,查询语句如下:

查询语句Q2用以计算两个文本的相似度。
03
系统实现
为实现结构化、非结构化数据的融合管理和关联查询分析,本文采用智能属性图模型,基于Neo4j开源版本,设计并实现了异构数据智能融合管理系统PandaDB。本部分第2.1节介绍PandaDB的总体架构,第2.2节~第2.5节分别介绍各模块的设计思路和实现细节。
3.1 总体架构
PandaDB基于智能属性图模型组织数据,底层数据被分为图结构数据、结构化属性数据和非结构化属性数据这3部分。其中,图结构数据指图的节点和边等描述图结构的数据;结构化属性数据指数值、字符串、日期等类型的数据;非结构化属性数据泛指除结构化数据之外的数据,如视频、音频、图片、文档等。PandaDB以BLOB对象的形式存储非结构化数据,并将其表示为实体(节点)的属性。根据上述3类数据的应用特点,PandaDB设计了分布式多元存储方案。
分布式图数据存储:基于传统的图数据库保存图结构数据和属性数据,在每个节点上保存相同的数据副本;
结构化属性协存:基于ElasticSearch,Solr等外部存储实现大规模结构化属性数据的存储和索引构建;
BLOB存储:基于Hbase,Ceph等存储系统实现非结构化属性数据的分布式存储。
PandaDB总体架构如图5所示,重要模块描述如下。
存储引擎:维护本地的图结构数据,调度外部属性存储,按需为查询引擎提供服务;
外部存储:包括基于ElasticSearch的结构化属性协存和基于HBase的BLOB存储两部分;
查询引擎:解析并执行CypherPlus查询;
AIPM:AI模型服务框架,通过模型和资源管理,实现AI模型的灵活部署、高效按需运行;同时,有效屏蔽AI模型之间的依赖。
PandaDB集群采用了无主架构设计,图5中,PandaNode是其中的节点,包含查询引擎和存储引擎两部分.属性数据和非结构化数据存储在外置分布式存储工具中,PandaNode只保存图结构数据,通过属性存储接口与外置存储交互.
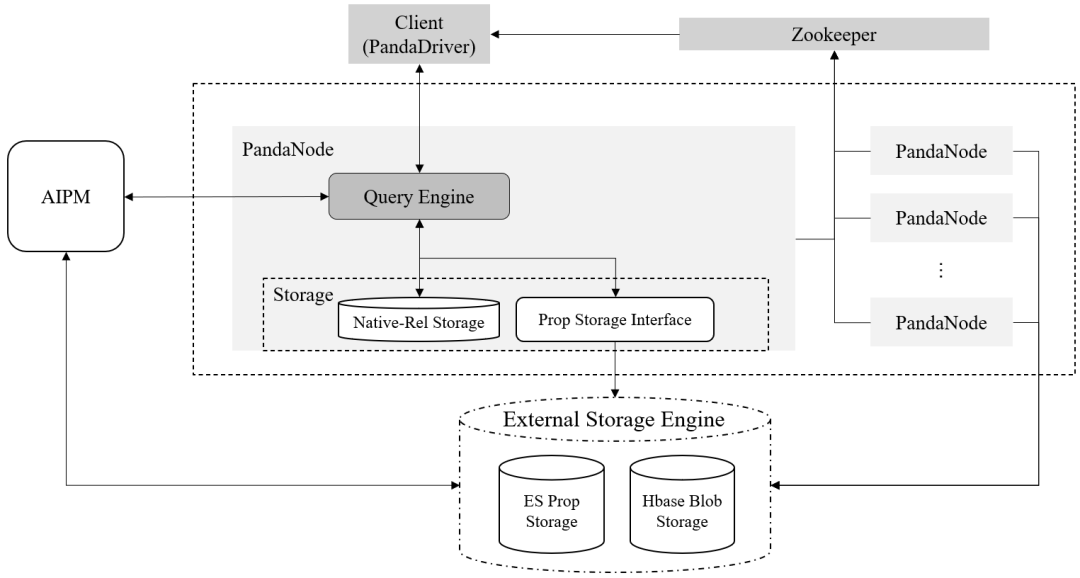
Fig.5 Architecture of PandaDB
图5 PandaDB总体架构设计
3.2 存储机制
PandaDB将BLOB引入了Neo4j的类型系统,同时对Neo4j的存储结构进行了改造。存储结构如图6所示,除了Neo4j保留区,BLOB的属性字段同时记录了BLOB的元数据,包括唯一标识blobid、长度length和MIME类型。
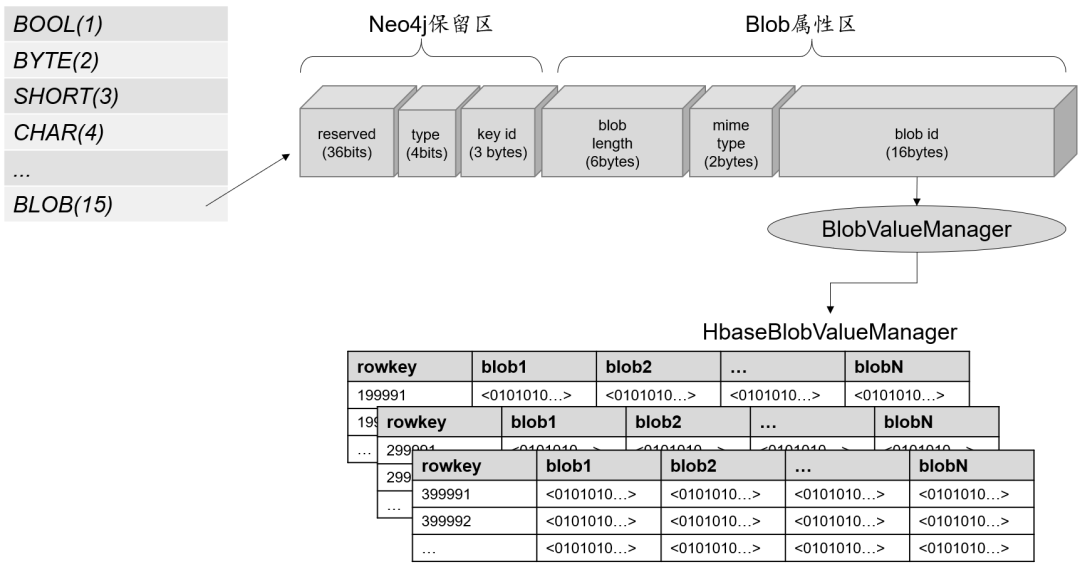
Fig.6 Design of BLOB storage structure
图6 BLOB存储结构设计
为实现对外部BLOB存储系统的调用,PandaDB中设计了BlobValueManager接口,定义了getById(×)/ store(×)/discard(×)等操作方法。作为BlobValueManager的一个实现,HBaseBlobValueManager基于HBase集群实现BLOB数据的存取。在该方案中,为支持大规模BLOB的存储,HBase被设计成包含N列的宽表,采用blobid/N作为HBase表的rowkey,blobid%N对应于HBase的某一列。
为加速BLOB的读取,BLOB的内容读取被封装为一个InputStream,在用户通过Bolt协议获取BLOB内容或进行语义计算的时候,这种流式读取的机制提高了运行的性能。
多元存储带来了存储事务保证的复杂性,客户端在写入数据时,将写操作请求发送到PandaDB的Leader节点,然后由Leader节点执行具体的写入操作。eader节点的具体操作流程如下:
Leader节点开启事务,执行Cypher解析,翻译成具体的执行操作;
向BLOB存储引擎发送请求,执行BLOB数据的写入操作。若执行失败,则向上回滚,标记事务失败;
若BLOB数据写入成功,则执行图结构数据和结构化属性数据的写入操作;若执行失败,则向上回滚,标记事务失败;
将结构化属性数据的修改,同步到协存。若执行失败,则向上回滚,标记事务失败;
执行事务提交;
关闭事务,返回操作成功。
3.3 查询机制
PandaDB查询引擎主要实现查询语句的解析、逻辑计划的生成与优化、物理计划的优化与执行.基于Neo4j,PandaDB查询引擎主要改进如下几个部分。
解析阶段:增强Cypher语言的解析规则,支持BLOB字面常量(BlobLiteral)、BLOB次级属性的抽取操作符(SubPropertyExtractor)以及属性语义操作符(SemanticComparison);
语法检查阶段:针对BlobLiteral,SubPropertyExtractor,SemanticComparison执行形式检查,如发现非法的BLOB路径、非法的语义算子和阈值等;
计划优化阶段:针对BlobLiteral的操作进行优化,针对大规模属性过滤情形,采用谓词下推策略等;
计划执行阶段:充分调度属性协存模块、AIPM模块以及BLOB存储模块,实现高效的属性优先过滤、BLOB获取与语义计算。图7示出了一个典型的查询过程,该查询要求返回所有与photo0中人脸相似,且age值大于30的节点。
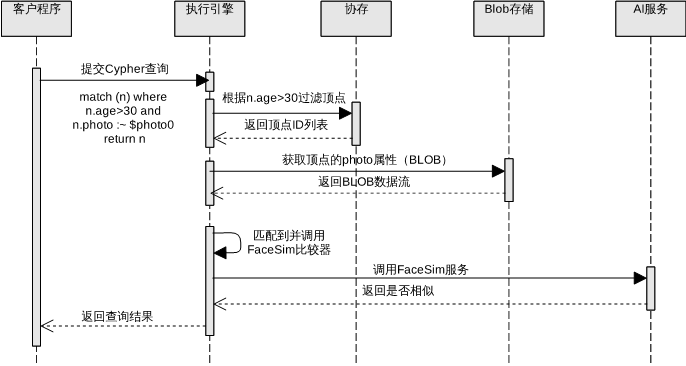
Fig.7 CypherPlus query process
图7 CypherPlus查询流程
图8从查询语法、查询计划、执行引擎这3个层面示出了PandaDB查询机制的设计。解析引擎将查询语句中的符号转化为语义算子,执行引擎根据规则集选择AI模型处理对应的数据,并将结果返回。
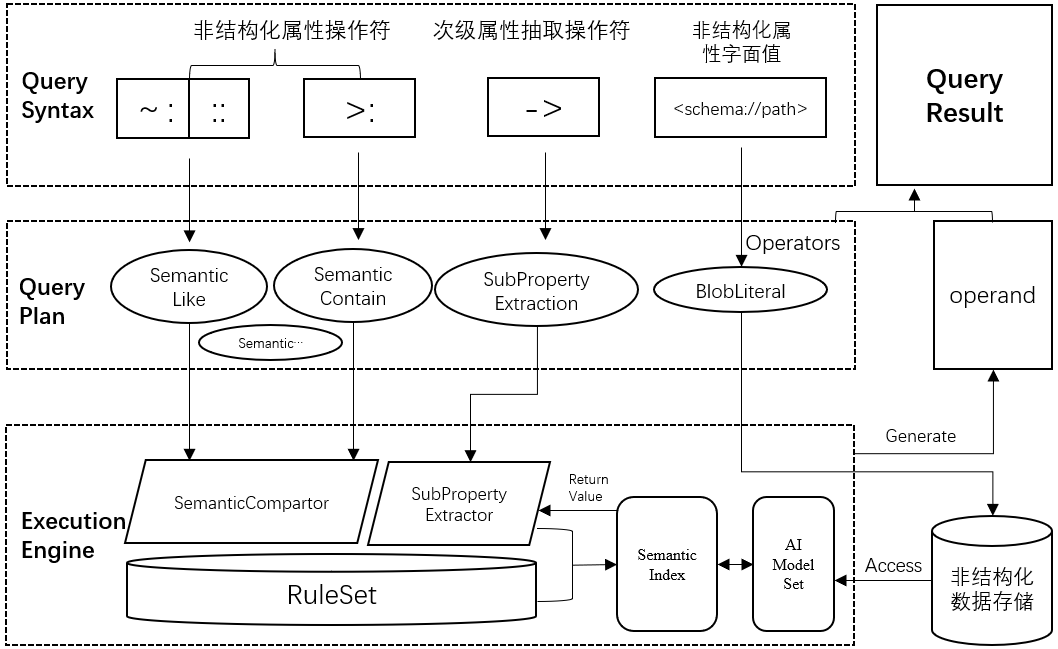
Fig.8 Query mechanism of intelligent property graph
图8 智能属性图查询机制
为加速非结构化数据的查询,PandaDB实现了语义索引功能。非结构化数据中的信息被认为是一种语义信息,如图片中的人脸、图片中汽车的车牌号、录音中所包含的文字信息等。AI模型从非结构化数据中抽取信息的过程可以看作是数据从高维空间到低维空间的映射,在低维空间映射的结果可以作为数据在该场景下的语义索引。
如在人脸比对查询的过程中,需要比较不同图片中人脸的相似度,通常的做法是利用人脸识别模型抽取人脸特征,比较两个特征的相似度。在PandaDB中,以向量形式表示的人脸特征被视为该非结构化在当前查询场景下的语义索引。系统处理涉及人脸比对的查询时,优先检查是否有对应的语义索引,若该查询对应的语义索引存在,则不向AIPM发起处理请求,直接比较语义索引得到结果。
语义索引可以减少查询引擎对AI服务的请求次数,从而避免了重复的数据传输,有利于提高系统效率。
3.4 属性数据协存
PandaDB引入属性数据协存机制,用于实现结构化属性数据的全文索引,提高节点属性的过滤查询效率。目前,PandaDB支持ElasticSearch作为协存引擎。
图9示出PandaDB协存模块的写入流程,协存机制的关键设计如下。
属性数据在ElasticSearch中的存储结构:每个Neo4j图数据库对应协存引擎(ElasticSearch)中一个独立的索引,每个节点的属性数据和标签数据均组织成ElasticSearch中的一个文档,其中,节点在Neo4j数据库中的ID作为文档的ID,节点属性名作为文档的属性标签,节点属性值作为文档的属性数据,节点的标签数据表示为特殊设置的属性标签.数值、字符串、坐标、日期、时间等结构化属性数据类型分别转换为ElasticSearch中的对应数据类型;
属性写入及更新:为了维持Neo4j数据库中的本地数据和ElasticSearch中数据的一致性,PandaDB对Neo4j中事务操作执行模块(operations)中的节点更新部分进行了扩展,设计了ExternalPropertyStore用于存储在Neo4j事务中执行的所有操作。当Neo4j数据库执行插入节点、添加标签、设置属性、删除节点等操作的同时,也将对应的操作数据缓存到ExternalPropertyStore中,当Neo4j数据库执行事务提交操作的同时,将缓存的操作数据同步到ElasticSearch中;
属性过滤:为了基于协存实现节点属性过滤,PandaDB对Neo4j的Cypher查询执行计划进行了改造,将节点属性过滤谓词下推到协存管理模块。根据谓词过滤条件生成ElasticSearch的检索请求,最后将命中的文档(节点)列表返回给查询引擎做进一步筛选。为了避免大量查询结果增大网络传输延迟,PandaDB采用了异步分批的方式传递的查询结果。

Fig.9 Write progress of property co-store module in PandaDB
图9 PandaDB协存模块的写入流程
3.5 AI算法集成与调度
AI算法集成与调度主要包括本地算法驱动管理和AI算法服务框架。
(1) 本地算法驱动管理
为了对不同的抽取器(SubPropertyExtractor)和语义比较器(SemanticCompartor)进行统一管理,PandaDB制定了驱动管理规则库。图10是对规则库中部分内容的展示,其中,DogOrCatClassifier用以抽取宠物类型,适用于blob/image类型的属性。CosineStringSimilarity用以计算两个文本串的余弦相似度,仅适用于两个string类型的属性。

Fig.10 Extractor and semantic comparator matching rule set
图10 抽取器和语义比较器匹配规则库
(2) AI算法服务框架
PandaDB中的信息抽取能力通过AI服务方式实现,AIPM为PandaDB提供AI服务,它可以屏蔽不同AI模型之间的依赖冲突问题,降低人工智能模型的部署和维护难度,便于PandaDB按需扩展AI算子。图11给出了AIPM与系统之间的交互逻辑。系统以HTTP请求的方式向AIPM发出查询请求,请求的路径与AI算法具有对应关系,AIPM接受到查询请求,调用对应的AI算法处理数据,以JSON字符串的形式返回结果。为了增强AI算子的可扩展性,AIPM设计了统一的集成接口,并要求算子提供对这些接口的支持。图12是AI模型管理框架的示意图。
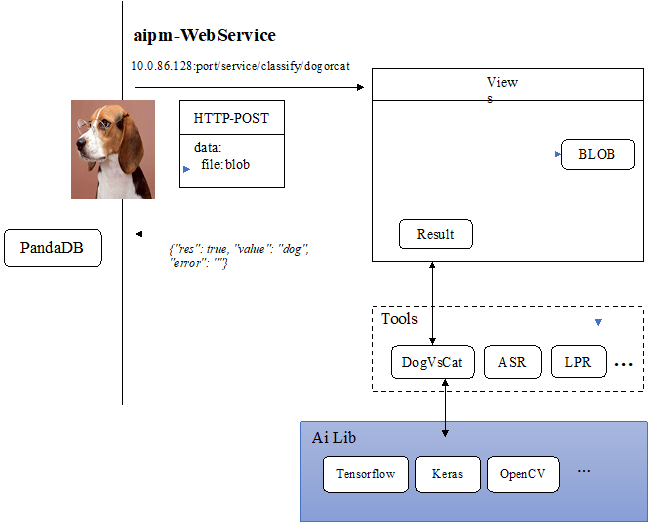
Fig.11 Interaction of PandaDB and AIPM
图11 AIPM与PandaDB交互框架

Fig.12 AI model management Framework
图12 AI模型管理框架
04
系统效果评估
为验证模型设计及PandaDB实现的有效性,本文针对属性协存、分布式方案、非结构化数据信息查询进行了测试;同时,通过应用案例验证PandaDB对结构化和非结构化数据的融合管理能力。
4.1 属性协存性能测试
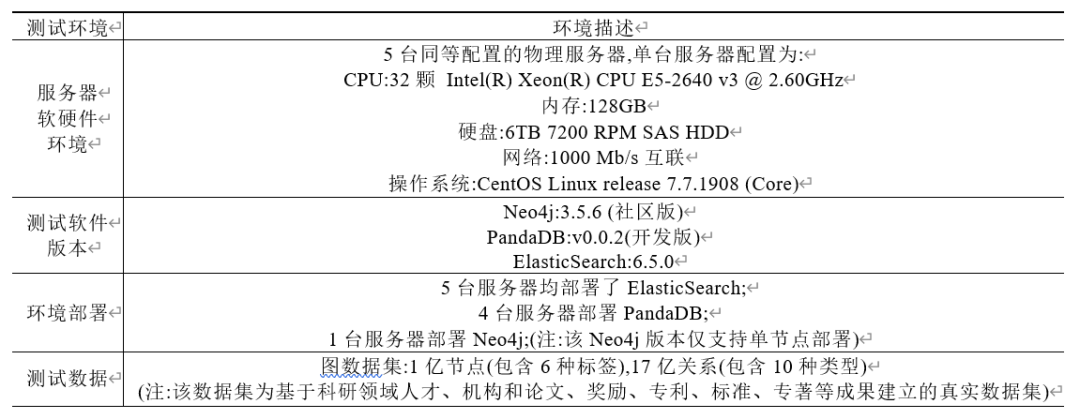
本测试验证基于ElasticSearch属性协存方案的性能,对Neo4j和引入协存方案后的PandaDB的查询性能进行对比,测试环境见表2。
Table 2 Information about test environment
表2 测试环境信息
实验中使用的Cypher查询语句见表3。实验中对每条查询语句分别进行多次测试并取执行时间的平均值(如表4、图13所示)。为避免冷启动带来的性能影响,测试前对系统进行了预热。
Table 3 Query statement in propery co-store test
表3 协存方案验证测试的查询语句

Table 4 Test result for property co-store
表4 协存方案验证测试结果

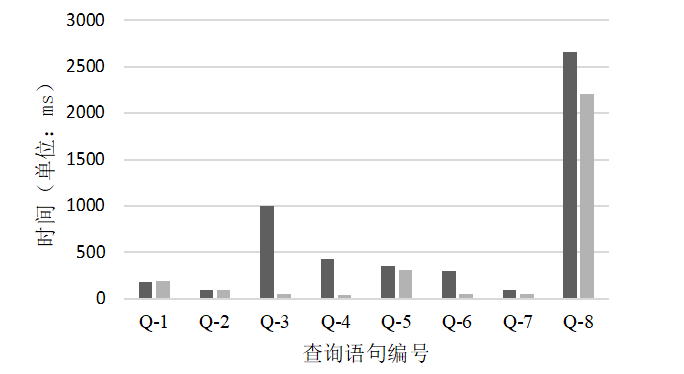
Fig.13 Comparison of query time in co-store
图13 协存方案查询响应时间对比
从测试结果可看出:由于采用了ElasticSearch作为节点属性的协存和索引,在上述查询语句执行测试中,PandaDB占据明显优势;尤其在节点多属性过滤查询和模糊匹配查询中,性能平均提升2~6倍。
4.2 分布式性能测试
为验证分布式架构带来的查询响应能力的提升,本文在物理机集群上(物理机配置见表2)部署了PandaDB和Neo4j单机版,对并发查询请求的吞吐率进行评估。因Neo4j社区版仅支持单机,故其中PandaDB部署在3台物理机,Neo4j部署在一台物理机。
本文选择了图计算分析中的常见查询作为测试用例,如计算节点出度和入度。将超时阈值设定为300s,在满足90%查询不超时的前提下,Neo4j的吞吐量为每秒15次查询,PandaDB的吞吐量为每秒40次查询。PandaDB的吞吐量接近Neo4j的3倍。
4.3 非结构化数据查询加速测试
为实现对非结构化数据查询的加速,PandaDB采用了构建语义索引的方式,减少数据传输和调用AI服务的次数。本小节基于人脸检测场景,使用LFW数据集构建对比实验,通过对比各种方案下的查询耗时,验证语义索引方案的加速效果。
本实验的任务目标为:从样本集中找到与目标人脸图片相似度最高的人脸图片。本实验共分4组对比,各组实验内容及实验条件细节如下。
NOOP:无优化,PandaDB向AIPM发出图片相似度对比请求,逐个将图片以BLOB流的形式发送给AIPM;AIPM接收请求后抽取特征,将比对结果返回给PandaDB;
DLOC:数据本地化方案,PandaDB与AIPM部署在同一台服务器上,减少BLOB传输的网络开销;
AIIDX:AI服务缓存方案,PandaDB向AIPM请求数据,AIPM利用本地缓存的特征数据响应请求。模仿数据流水线工具的实现;
SEMIDX:语义索引方案,PandaDB中构建非结构化数据的语义索引(人脸特征向量),执行查询时,直接调用本地索引数据比较。
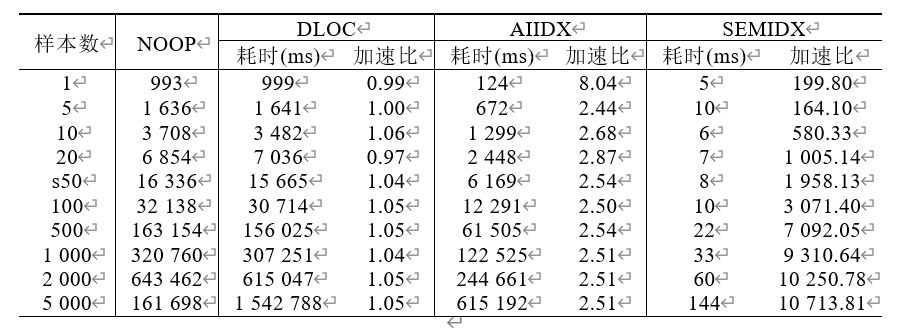
表5给出了在不同样本数下,各方案执行同一个查询的耗时。SEMIDX方案相比于其他方案减少了数据传输和重复的数据抽取,故理论上该方案在4个方案中速度最快。
从表5中可以看出:在样本数相同的条件下,SEMIDX方案具有最短的查询时间。在样本数超过2000的检索性能对比中,加速比超过1万倍。
Table 5 Comparison of query time under different methods
表5 不同方法的查询耗时对比
4.4 案例:学术图谱实体消歧与可视化
学术图谱泛指以学术内容为主体的领域知识图谱,典型应用如AMiner和AceKG。本文基于KDD2020的参会人员信息构建了一个小型的学术图谱,其中包含论文、作者、机构等3类节点,根据论文创作关系和学者与机构间的隶属关系,将作者照片、论文的PDF全文等非结构化数据作为属性直接保存在PandaDB中。
图14是KDD2020数据的可视化展示(基于开源项目InteractiveGraph:https://github.com/grapheco/ InteractiveGraph),其中,头像属性存储在PandaDB,且在PandaDB的基础上提供了“以图找图”的功能,即实现了基于头像的快速匹配。
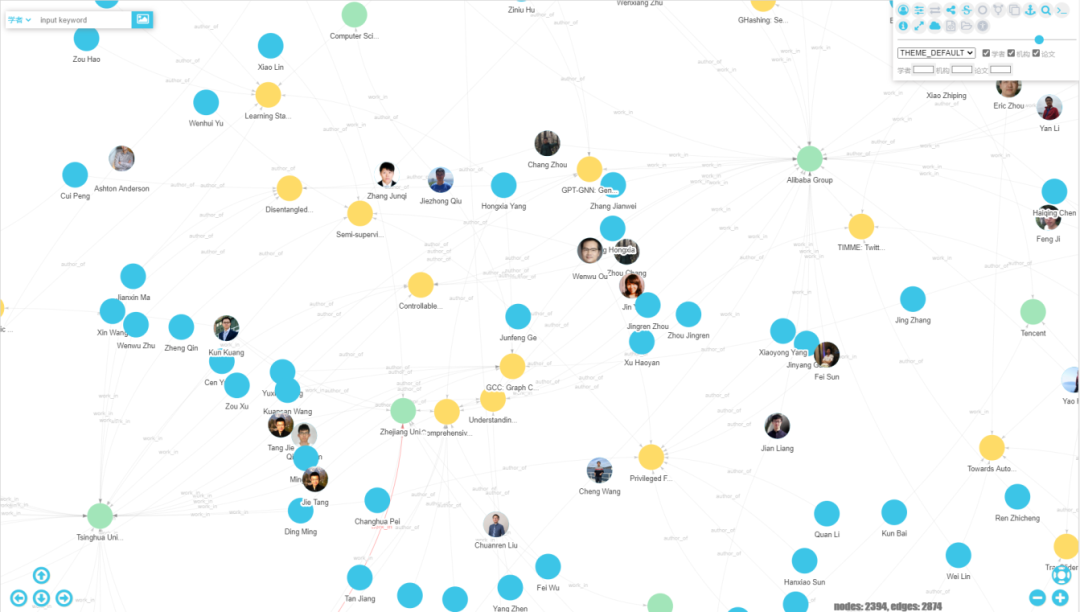
Fig.14 Visualization of KDD2020
图14 KDD2020数据的可视化展示
学术图谱原始数据中通常会出现学者重名、不同机构的简称或缩写相同等情况,因此,图谱创建过程中通常面临实体消歧问题。目前,大多数实体消歧方法都以聚类为基础,文献[15-17]使用表层特征值计算实体间相似度,但这种方法不能充分利用上下文特征。因为基于表层特征的方法面临信息不足的问题,有学者尝试引入外部信息,如WikiPedia中的信息,将这些知识资源作为实体的扩展特征,辅助提升聚类准确性,代表工作如文献[18,19]。文献[20,21]使用图计算的方法,充分利用网络数据的结构信息,但并不具有很好的普适性。近年来,随着深度学习技术的巨大进步,有学者利用embedding技术[22]和神经网络技术[23],这类方法相比于传统方法具有更好的效果,但准确性方面仍不能满足人们的预期。本案例基于PandaDB,提出了一种融合结构化属性和非结构化属性的消歧方法。如图15所示,某学术图谱中有两个姓名分别为Park Bill和Tom Green的人物节点以及一个名为Data Vis的论文节点,需要判断T.Green和Tom Green是否为同一实体,从而判断Park Bill和Tom Green之间是否存在合作关系。由于论文中存在的属性数据不足,消歧很有困难。基于PandaDB对非结构化信息抽取及语义比较能力,可以充分利用Tom Green的照片以及论文作者照片列表,从而达到消歧目的.图15下半部分给出了完成该操作的CypherPlus语句,其中,<:操作符表示包含关系,只需要找到对应的节点,判断n.photo<:p.screenshot成立与否,即可计算出二者之间是否存在合作关系。
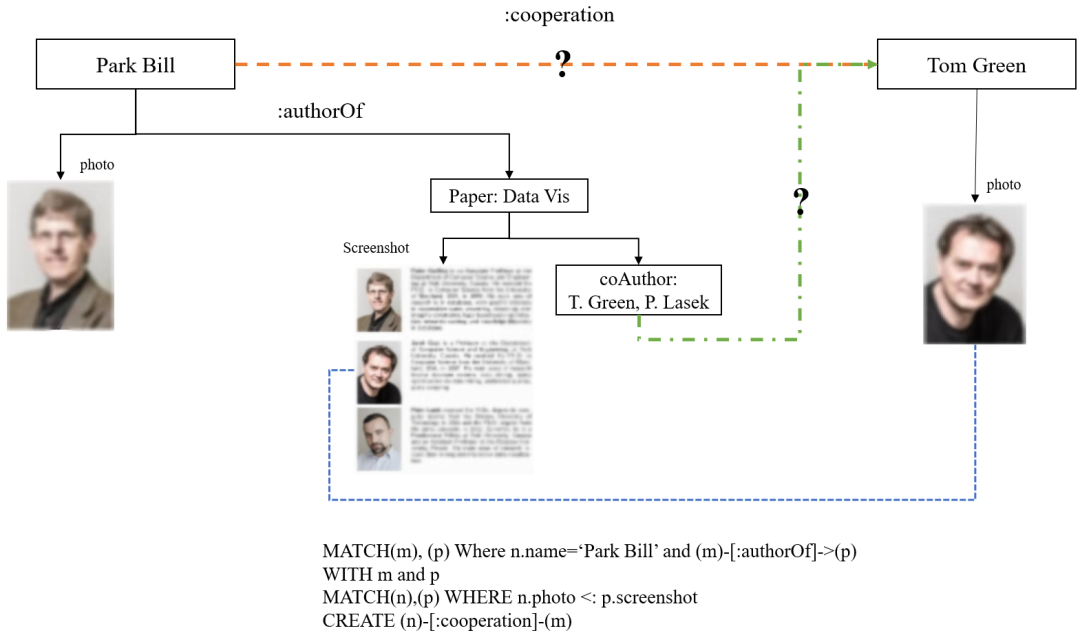
Fig.15 Diagram of entity disambiguation based on PandaDB
图15 基于PandaDB实现实体消歧示意图
05
相关工作
为实现数据应用中的多元异构数据的统一管理和分析,一种方法是通过 ETL 工具,采用某种统一的形式处理异构数据。但这种方法成本较高,而且数据和分析需求的变化会使原本的 ETL 流程失效[24]。异构数据管理可以支持对多模型数据的存储和统一查询。学术界在上世纪 80 年代就提出了联邦数据库的解决概念,Multibase[25]是其中的代表系统,这类系统的特点是定义全局 schema 和基于映射的查询语言,用户基于全局 schema 查询,系统将查询映射到分区 schema.另一类以 Spark SQL[26]为代表的系统提供统一的 API,允许用户以关系模型使用数据,在提升效率和简化查询方面有较好的效果。BigIntegator[27],Forward[28],D4M[29]等系统整 合了 NoSQL,其中 Forward 以基于 json 的数据模型组织数据,D4M 使用关联阵列(associative-array)数据模型,这种较为灵活的模型使系统可以在异构数据上执行查询。在数据管理领域,属性图模型[30]是一种常用的管理图数据的数据模型,属性图中的节点和关系都可以被 赋予标签和关联任意键值对形式的属性[31]。属性图增加了节点和边的信息,同时又没有改变图的整体结构。目前,属性图模型被图数据库业界广泛采用[32][33],包括著名的图数据库 Neo4j[34]、Titan[35]等。Neo4j是目前应用较为广泛的一款开源图数据库,其具有从原生图数据存储到可视化插件,再到图数据分析插件的丰富生 态。JanusGraph[36]是在 Titan 基础上开发的一种基于属性图的分布式图数据库。JanusGraph 采用存储层和查询引擎分离的设计,可以使用 Cassandra 或 HBase 作为存储层。JanusGraph 通过使用第三方分布式索引库 ElasticSearch、Solr和Lucene 实现检索功能。其他的图数据库还包括:Amazon的Neptune[37]、微软的Azure CosmosDB[38]、TigerGraph[39]、OrientDB[40]等。人工智能技术已经广泛的应用到图像识别、语音识别、机器翻译等领域中。为了实现对语音、图片等多种信息的理解,多模态机器学习的研究尝试在机器学习的角度整合模型对非结构化数据的理解能力[41][42]。人工智能与数据库的交叉研究一直是学术界研究的热点内容。人工智能与数据库的融合存在AI4DB(AI for 沈志宏 等: PandaDB:一种面向异构数据的智能融合管理系统 20 Database)和 DB4AI(Database for AI)两个方向[43]。AI4DB 旨在通过 AI 技术提高 DB 的效率和能力,如自动化数据库参数调优[44] [45]、基数估计[46]、索引推荐[47]、查询优化[48][49]等。DB4AI,是以数据库为AI算法提供数据服务,供算法进行训练和学习。例如,借助数据库的统一 SQL 接口,为用户提供自定义的函数协助构建模型;通过数据库张量计算协助模型训练;通过持久化AI模型以重复使用。随着大数据时代的来临,海量数据的存储与计算使得单机服务已经无法满足需求,越来越多的任务需要分布式系统支持。保证分布式系统的可靠性和一致性至关重要。解决这个问题的一个著名算法是由 Lamport 提出 的 Paxos 算法[50][51]。此后为了适应不同的工程环境,研究人员在 Paxos 的基础上提出了很多新的算法[52]。比较著名的有 Multi-Paxos[51][53]、Liskov等人提出的 VR (viewstamped replication)算法[54][55]、雅虎公司设计的 ZAB(Zookeeper’s atomic broadcast)算法[56]、Ongaro 等人提出的 Raft 算法[57]等。
06
总结与展望
本文从结构化/非结构化数据的融合管理和即席查询需求角度出发,分析了目前多元异构数据融合管理方面统一表示和交互式查询等难点。在此基础上提出具备对异构数据实现统一表示能力的属性图扩展模型,并提出针对在线查询和计算的属性操作符与查询语法。在第3节,本文提出基于智能属性图模型的分布式数据融合管理系统PandaDB,该系统实现了结构化/非结构化数据的高效存储管理,并提供了灵活的 AI 算子扩展机制,具备对多元异构数据内在信息的即席查询能力。测试实验和案例证明,PandaDB在大规模属性过滤查询和高并发查询响应上具备较好的性能表现。同时PandaDB可应用在学术图谱实体消歧与可视化等多元异构数据融合管理的场景。目前PandaDB还存在着一些不足,一方面,AIPM模块与系统相对独立部署,这种模式降低了系统的耦合性,有利于扩展和维护,但面对大规模的非结构化数据信息查询请求时,模块间信息传输的开销较大。未来应研究更为合理的 AI 功能集成机制,结合多元异构数据即席查询的场景特性设计任务调度方法,提升系统性能。另一方面,从智能属性中抽取内嵌式属性的操作,目前还缺乏有效的缓存和预测机制,造成即席抽取的过程延时较 大。PandaDB将进一步结合应用,进一步提升系统的性能和稳定性,从而提升多元异构数据融合管理的能力。
阅读原文
