




TiKV 里值得学习、研究的组件非常多,这里列出几个相对重要的知识点,做一个汇总和回顾。
LSM-Tree
更新模式
1. 原地更新:
MySQL 的 B+ tree 就是典型的原地更新模式。
读友好
写性能略差
2. 非原地更新:

LSM-Tree 属于非原地更新,优劣性如下:
写友好(直接append)
读性能略差(不知道准确位置,需要找多个地方)
需要定期重新组织数据
与 SSD 的关系
NAND Flash 是以页 page 为单位进行写入的,而且只能写入空闲的 page ,不能覆盖原先有内容 page。
page 是最小单位,多个 page 组成 block。
在删除做 gc 的时候,因为电压高只能以 block 为担心进行擦除。
所以 LSM-Tree 追加写入的原理就不会出现这种性能浪费。
LSM-Tree 结构
把一棵大树拆成 N 颗小树,第一层是在内存里构建一颗有序小树,随着小树越来越大,内存里的小树会 flash 到磁盘上。磁盘中的树也会不断做 compaction 操作,最终合成一颗大树,最终弥补了读性能一般的问题。
LSM-Tree 会有很多层,每一层的容量都是成倍增长的,越往下容量越大。
RocksDB
RocksDB 是基于 levelDB 优化的
是持久化的 key-value 单机存储引擎
是基于 LSM-Tree (Log-Structured-Merge Tree)
支持 MVCC 多版本并发控制
基础操作包括:
Get key
Put key
Delete Key
Seek key
scan
Write Ahead Log
WAL 简单来说就是会先写入磁盘 log,然后再写入内存,流程如下:
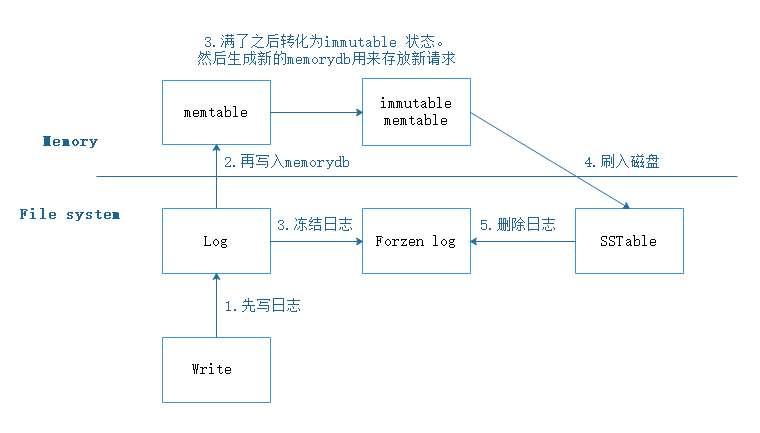
在写 memtable 之前会将该次操作的内容先写入 WAL;
如果进程发生了异常,或者是宿主机发生了异常,都可以通过 redo WAL 来恢复;
每个 memtable 都有对应的 WAL,当 memtable flush 成一个 sstable 文件并持久化完成后,与之对应的 WAL 会被删除;
SSTable:LSM-Tree 里核心的数据结构就是 SSTable,全称是 Sorted String Table。
SSTable是一种拥有持久化,有序且不可变的的键值存储结构,它的key和value都是任意的字节数组,并且了提供了按指定key查找和指定范围的key区间迭代遍历的功能。
RocksDB 后台线程与 compact
RocksDB 中,将内存中的 MemTable 转化为磁盘上的 SST 文件,以及合并各个层级的 SST 文件等操作都是在后台线程池中执行的。后台线程池的默认大小是 8,当机器 CPU 数量小于等于 8 时,则后台线程池默认大小为 CPU 数量减一。通常来说,用户不需要更改这个配置。如果用户在一个机器上部署了多个 TiKV 实例,或者机器的读负载比较高而写负载比较低,那么可以适当调低 rocksdb/max-background-jobs 至 3 或者 4。
WriteStall
Write Stall 是 RocksDB 的流控机制。
RocksDB 的 L0 与其他层不同,L0 的各个 SST 是按照生成顺序排列,各个 SST 之间的 key 范围存在重叠,因此查询的时候必须依次查询 L0 中的每一个 SST。为了不影响查询性能,当 L0 中的文件数量过多时,会触发 WriteStall 阻塞写入。
Write Stall 相关参数:
memtable 数量过多
数量达到 max-write-buffer-number
L0 文件过多
达到 level0-slowdown-writes-trigger 减缓写入
达到 level0-stop-writes-trigger 停止写入
pending compaction bytes 过多
达到 soft_pending_compaction_bytes 减缓写入
达到 hard_pending_compaction_bytes 停止写入
相关参数
max-background-jobs:进行后台任务的最大线程数,后台任务包括 compaction 和 flush;
max-sub-compactions:同时进行一个 compaction 任务的最大线程数;
max-manifest-file-size:MANIFEST 文件的大小限制;
max-open-files:能够打开的最大文件句柄数;
block-size:数据块大小,RocksDB 是按照 block 为单元对数据进行压缩的,同时 block 也是缓存在 block-cache 中的最小单元;
compression-per-level:RocksDB 每一层数据的压缩方式;
write-buffer-size:RocksDB memtable 的大小;
target-file-szie-base:RocksDB SST 文件的大小;
block-cache-size:block-cache 的大小
键值分离思想
TiKV 的 key 和 value 被设计成了分离的模式,实际写入 LSM-Tree 的是 key+index ,这个 index 指向 value。这种设计主要还是为了应对 compaction 下的写放大。
通过将大 value 分离出 LSM-Tree 以减少写放大
对于查询需要额外的 I/O 消耗
因为 value 被存放在其他单独的文件中
LSM-Tree 整体更小,可以更多节点被 cache 在内存中
范围查询需要随机 I/O
利用 SSD 的并行性
顺序 IO 和随机 IO 的性能差距在减小
于是 Titan 出现了。
Titan 简介
Titan 是基于 RocksDB 的高性能单机 key-value 存储引擎插件。它是基于 WiscKey 设计理念开发的,相比 Titan ,WiscKey 没有 WAL 这类功能所以需要大幅改造。
Titan 设计目标
将大 value 分离出 LSM-Tree 到 Blob 文件中以减少写放大,并可以选择性内联小value 以便提供更好的读性能。
可以无缝从现有的 RocksDB 实例中升级,不需要额外操作,也不会影响在线业务。
100% 兼容 TiKV 现有使用的 RocksDB 特性。
Titan 架构
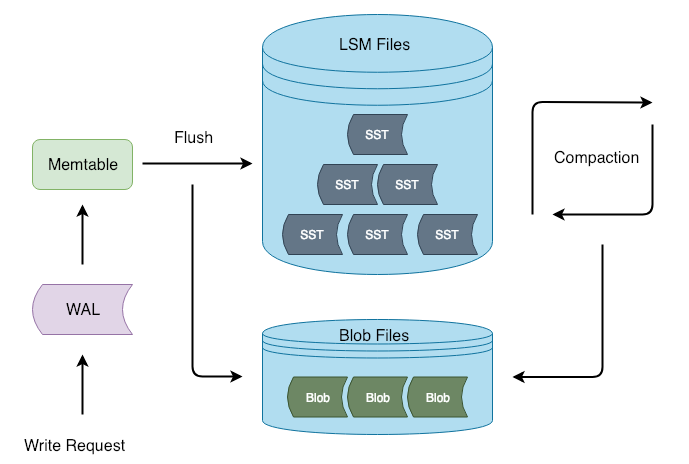
Titan 在 Flush 和 Compaction 的时候将 value 分离出 LSM-tree,这样写入流程可以和 RocksDB 保持一致,减少对 RocksDB 的侵入性改动。
Titan 适用场景
前台写入量较大,RocksDB 大量触发 compaction 消耗大量 I/O 带宽或者 CPU 资源,造成 TiKV 前台读写性能较差。
前台写入量较大,由于 I/O 带宽瓶颈或 CPU 瓶颈的限制,RocksDB compaction 进度落后较多频繁造成 write stall。
前台写入量较大,RocksDB 大量触发 compaction 造成 I/O 写入量较大,影响 SSD 盘的寿命。
Titan GC流程
Compaction 完成后根据统计信息更新 Blob 文件被删除 value 的大小并计算 GC score;
根据score 从大到小选择多个 Blob 文件作为 GC 的候选目标;
对这些候选目标进行采样,排除那些被删除 value 比例未达到阈值(DISCARD_RATIO)的文件;
遍历候选文件归并所有有效的 value 成一个新的 Blob;
将新增的 Blob 文件记录在 MANIFEST 日志中;
将所有有效的(key,blob-index)回写 LSM-Tree;
将 GC 删除的 Blob 文件记录在 MANIFEST 日志中;
