




在信息技术领域,自动化对我们大多数人来说并不是什么新鲜事。事实上,大多数组织根据其工作类型和目标将其用于各种目的。例如,数据分析师使用自动化来生成报告,系统管理员使用自动化来完成诸如清理磁盘空间之类的重复性任务,而开发人员使用自动化来自动化他们的开发过程。
如今,由于 DevOps 时代,有很多可用的 IT 自动化工具可供选择。哪个是最好的工具?答案是可预测的“视情况而定”,因为这取决于我们要实现的目标以及我们的环境设置。一些自动化工具是Terraform、Bolt、Chef、SaltStack,一个非常流行的工具是Ansible。Ansible 是一个开源的无代理 IT 引擎,可以自动化应用程序部署、配置管理和 IT 编排。Ansible 成立于 2012 年,用最流行的语言 Python 编写。它使用剧本来实现所有自动化,其中所有配置都是用人类可读的语言 YAML 编写的。
在今天的文章中,我们将学习如何使用 Ansible 进行 Postgresql 数据库部署。
是什么让 Ansible 与众不同?
- 之所以使用ansible,主要是因为它的特点。这些特点是:
- 任何事情都可以通过使用简单的人类可读语言 YAML 实现自动化
- 不会在远程机器上安装代理(无代理架构)
- 配置将从您的本地机器推送到您本地机器的服务器(推送模式)
- 使用 Python(目前使用的流行语言之一)开发,并且可以选择很多库
- 由 Red Had 工程团队精心挑选的 Ansible 模块集合
Ansible 的工作方式
在 Ansible 可以对远程主机运行任何操作任务之前,我们需要将其安装在一台主机上,该主机将成为控制器节点。在这个控制器节点中,我们将把我们想做的任何任务编排到远程主机(也称为托管节点)中。
控制器节点必须有托管节点的清单和 Ansible 软件来管理它。Ansible 使用的所需数据(如受管节点的主机名或 IP 地址)将放置在此清单中。如果没有适当的清单,Ansible 就无法正确执行自动化。请参阅此处了解有关库存的更多信息。
Ansible 是无代理的并使用 SSH 推送更改,这意味着我们不必在所有节点中安装 Ansible,但所有托管节点都必须安装 python 和任何必要的 python 库。控制器节点和受管节点都必须设置为无密码。值得一提的是,所有控制器节点和被管节点之间的连接都很好,并且经过了正确的测试。
对于这个演示,我使用 vagrant 配置了 4 个 Centos 8 虚拟机。一个将充当控制器节点,另外两个 VM 将充当要部署的数据库节点。我们不会在这篇博文中详细介绍如何安装 Ansible,但如果您想查看指南,请随时访问此链接。请注意,我们使用 3 个节点来设置流式复制拓扑,其中一个主节点和 2 个备用节点。如今,许多生产数据库都处于高可用性设置中,而 3 节点设置是一种常见的设置。
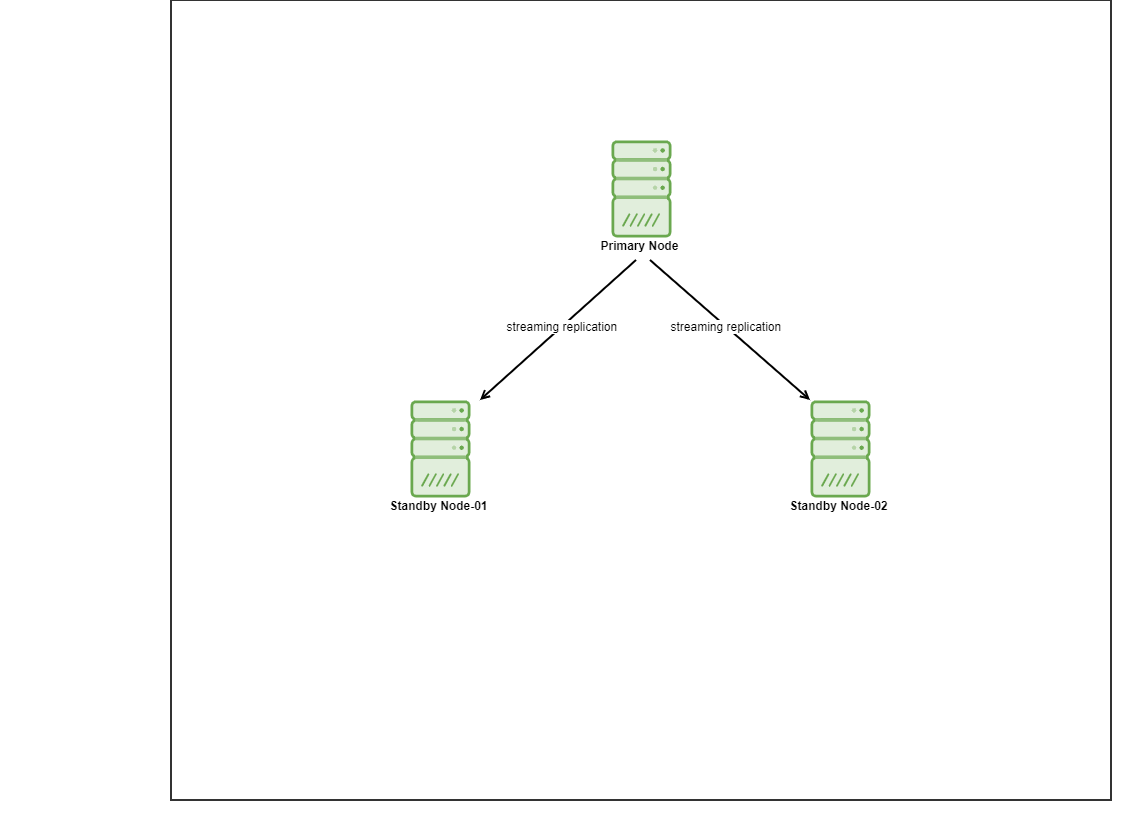
安装 PostgreSQL
有几种使用 Ansible 安装 PostgreSQL 的方法。今天,我将使用 Ansible Roles 来实现这个目的。简而言之,Ansible 角色是一组任务,用于配置主机以满足特定目的,例如配置服务。Ansible 角色是使用 YAML 文件定义的,该文件具有可从 Ansible Galaxy门户下载的预定义目录结构。
另一方面,Ansible Galaxy 是 Ansible 角色的存储库,可直接放入 Playbook 以简化自动化项目。
对于这个演示,我选择了dudefellah维护的角色。为了让我们利用这个角色,我们需要将它下载并安装到控制器节点。该任务非常简单,只要 Ansible 已安装在控制器节点上,就可以通过运行以下命令来完成:
$ ansible-galaxy install dudefellah.postgresql
在控制器节点中成功安装角色后,会看到以下结果:
$ ansible-galaxy install dudefellah.postgresql<font></font>
- downloading role 'postgresql', owned by dudefellah<font></font>
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz<font></font>
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql<font></font>
- dudefellah.postgresql (0.1.0) was installed successfully
为了让我们使用这个角色安装 PostgreSQL,需要完成几个步骤。Ansible Playbook 来了。Ansible Playbook 是我们可以编写 Ansible 代码或希望在托管节点上运行的脚本集合的地方。Ansible Playbook 使用 YAML,由按特定顺序运行的一个或多个 play 组成。可以定义主机以及要在分配的主机或受管节点上运行的一组任务。
所有任务都将以登录的 ansible 用户身份执行。为了让我们以不同的用户(包括“root”)执行任务,我们可以使用 become。下面我们来看看pg-play.yml:
$ cat pg-play.yml<font></font> - hosts: pgcluster<font></font> become: yes<font></font> vars_files:<font></font> - ./custom_var.yml<font></font> roles:<font></font> - role: dudefellah.postgresql<font></font> postgresql_version: 13
如此,我已将主机定义为pgcluster 并使用 become 以便 Ansible 以 sudo 权限运行任务。用户 vagrant 已经在 sudoer 组中。我还定义了我安装 dudefellah.postgresql 的角色。pgcluster 已在我创建的主机文件中定义。如果你想知道它的样子,可以看看下面:
$ cat pghost<font></font> [pgcluster]<font></font> 10.10.10.11 ansible_user=ansible<font></font> 10.10.10.12 ansible_user=ansible<font></font> 10.10.10.13 ansible_user=ansible
除此之外,我还创建了另一个自定义文件 ( custom_var.yml),其中包含了我想要实现的 PostgreSQL 的所有配置和设置。自定义文件的详细信息如下:
$ cat custom_var.yml<font></font> postgresql_conf:<font></font> listen_addresses: "*"<font></font> wal_level: replica<font></font> max_wal_senders: 10<font></font> max_replication_slots: 10<font></font> hot_standby: on<font></font> <font></font> postgresql_users:<font></font> - name: replication<font></font> password: r3pLic@tion<font></font> privs: "ALL"<font></font> role_attr_flags: "SUPERUSER,REPLICATION"<font></font> <font></font> <font></font> postgresql_pg_hba_conf:<font></font> - { type: "local", database: "all", user: "all", method: "trust" }<font></font> - { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }<font></font> - { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }<font></font> - { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }
要运行安装,我们所要做的就是执行以下命令。如果没有创建剧本文件(在我的例子中是pg-play.yml),你将无法运行 ansible-playbook 命令。
$ ansible-playbook pg-play.yml -i pghost
执行此命令后,它将运行角色定义的一些任务,如果命令成功运行,将显示此消息:
PLAY [pgcluster] *************************************************************************************<font></font>
TASK [Gathering Facts] *******************************************************************************<font></font>
ok: [10.10.10.11]<font></font>
ok: [10.10.10.12]<font></font>
<font></font>
TASK [dudefellah.postgresql : Load platform variables] ***********************************************<font></font>
ok: [10.10.10.11]<font></font>
ok: [10.10.10.12]<font></font>
<font></font>
<font></font>
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***<font></font>
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12
ansible 完成任务后,我登录到从站(n2),停止 PostgreSQL 服务,删除数据目录( /var/lib/pgsql/13/data/)的内容并运行以下命令以启动备份任务:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1<font></font>
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:<font></font>
$ sudo -u postgres psql<font></font>
postgres=# SELECT * FROM pg_replication_slots;<font></font>
-[ RECORD 1 ]-------+-----------<font></font>
slot_name | slaveslot1<font></font>
plugin |<font></font>
slot_type | physical<font></font>
datoid |<font></font>
database |<font></font>
temporary | f<font></font>
active | t<font></font>
active_pid | 63854<font></font>
xmin |<font></font>
catalog_xmin |<font></font>
restart_lsn | 0/3000148<font></font>
confirmed_flush_lsn |<font></font>
wal_status | reserved<font></font>
safe_wal_size |
我们还可以在启动回 PostgreSQL 服务后使用以下命令检查备用复制的状态:
$ sudo -u postgres psql<font></font>
<font></font>
postgres=# SELECT * FROM pg_stat_wal_receiver;<font></font>
<font></font>
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------<font></font>
pid | 229552<font></font>
status | streaming<font></font>
receive_start_lsn | 0/3000000<font></font>
receive_start_tli | 1<font></font>
written_lsn | 0/3000148<font></font>
flushed_lsn | 0/3000148<font></font>
received_tli | 1<font></font>
last_msg_send_time | 2021-05-09 14:10:00.29382+00<font></font>
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00<font></font>
latest_end_lsn | 0/3000148<font></font>
latest_end_time | 2021-05-09 13:53:28.209279+00<font></font>
slot_name | slaveslot1<font></font>
sender_host | 10.10.10.11<font></font>
sender_port | 5432<font></font>
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=any
如您所见,尽管我们已经自动化了一些任务,但为了为 PostgreSQL 设置复制,还需要做很多工作。让我们看看如何使用 ClusterControl 来实现这一点。
使用 ClusterControl GUI 部署 PostgreSQL
现在我们知道如何使用 Ansible 部署 PostgreSQL,让我们看看如何使用 ClusterControl 进行部署。ClusterControl 是一个用于数据库集群的管理和自动化软件,包括 MySQL、MariaDB、MongoDB 以及 TimescaleDB。它有助于部署、监控、管理和扩展您的数据库集群。有两种部署数据库的方法,在这篇博文中,我们将向您展示如何使用图形用户界面 (GUI) 部署它,前提是您的环境中已经安装了 ClusterControl。
第一步是登录您的 ClusterControl 并单击 Deploy:
接下来将看到下面用于下一步部署的屏幕截图,选择 PostgreSQL 选项卡以继续:
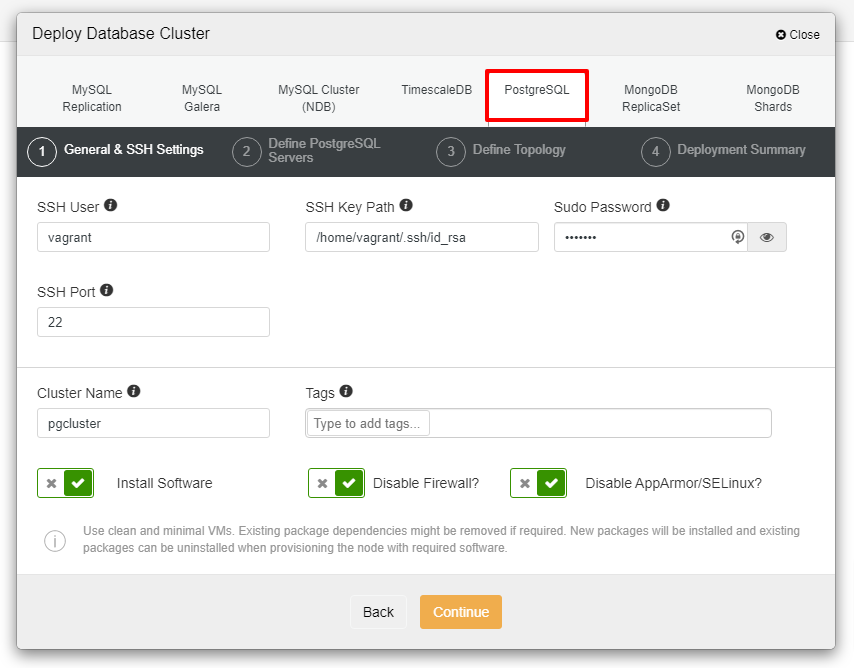
再我们继续之前,我想提醒你, ClusterControl 节点和数据库节点之间的连接必须是无密码的。在部署之前,我们需要做的就是从 ClusterControl 节点生成 ssh-keygen,然后将其复制到所有节点。根据您的要求填写 SSH 用户、Sudo 密码和集群名称的输入,然后单击继续。
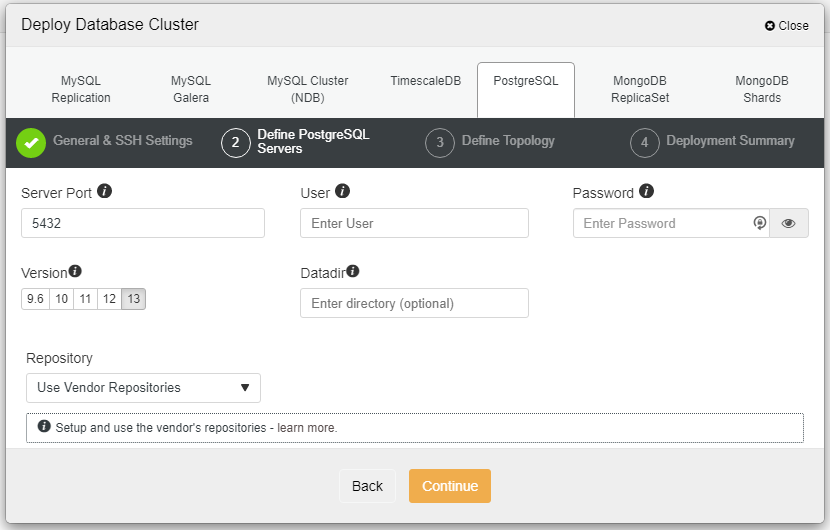
在上面的屏幕截图中,您=需要定义服务器端口(以防您想使用其他人)、想使用的用户以及密码和想安装的版本。
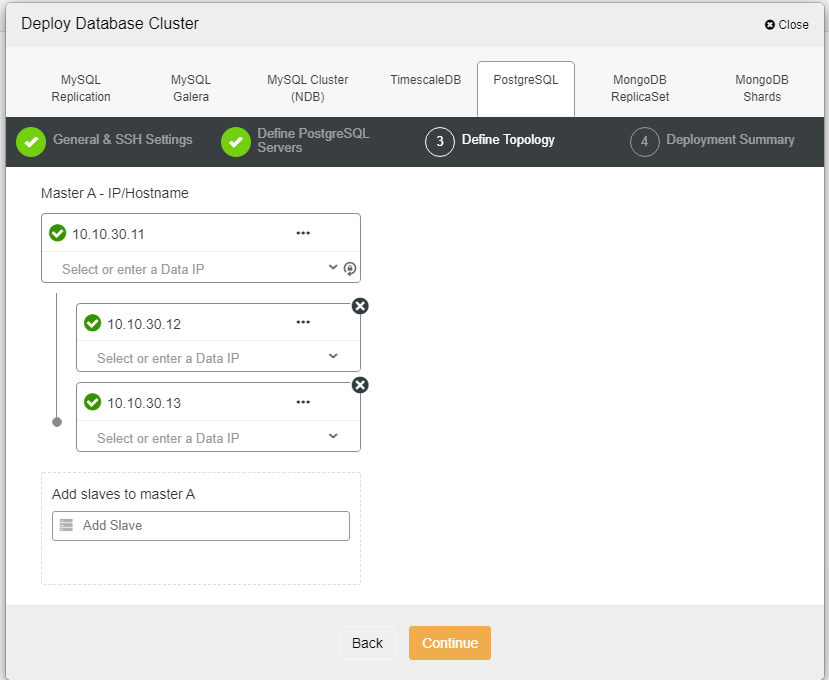
在这里,我们需要使用主机名或 IP 地址来定义服务器,例如在本例中为 1 个主站和 2 个从站。最后一步是为我们的集群选择复制模式。
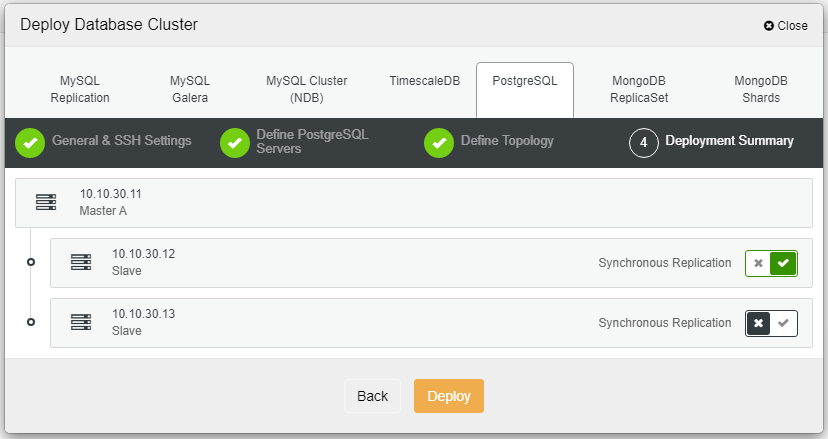
单击“部署”后,部署过程将开始,我们可以在“活动”选项卡中监控进度。
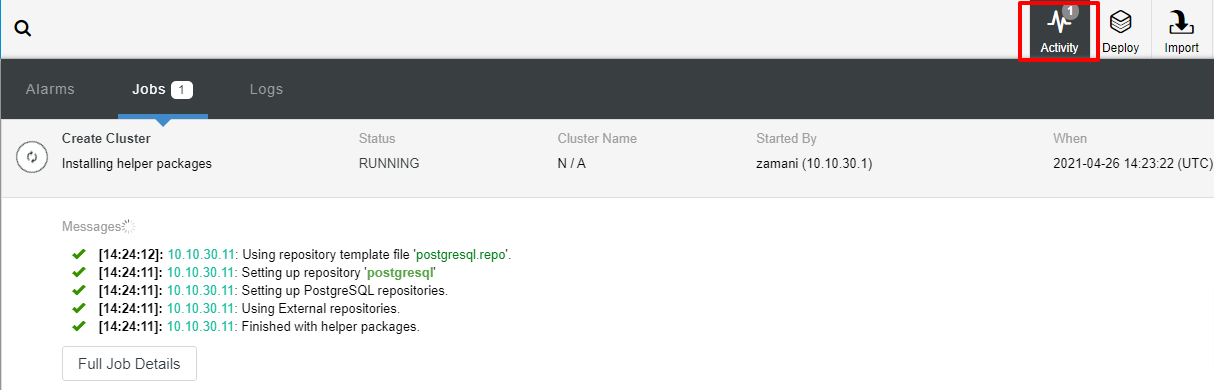
部署通常需要几分钟,性能主要取决于网络和服务器的规格。

现在我们已经使用 ClusterControl 安装了 PostgreSQL。
使用 ClusterControl CLI 部署 PostgreSQL
另一种部署 PostgreSQL 的方法是使用 CLI。如果我们已经配置了无密码连接,我们可以执行以下命令并让它完成。
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="P@$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --log
该过程成功完成后,您应该会看到以下消息,并且可以登录 ClusterControl Web 进行验证:
...<font></font>
Saving cluster configuration.<font></font>
Directory is '/etc/cmon.d'.<font></font>
Filename is 'cmon_1.cnf'.<font></font>
Configuration written to 'cmon_1.cnf'.<font></font>
Sending SIGHUP to the controller process.<font></font>
Waiting until the initial cluster starts up.<font></font>
Cluster 1 is running.<font></font>
Registering the cluster on the web UI.<font></font>
Waiting until the initial cluster starts up.<font></font>
Cluster 1 is running.<font></font>
Generated & set RPC authentication token.
结论
在这篇文章中,我们学习了如何使用 Ansible 以及我们的 ClusterControl 部署 PostgreSQL 。这两种方法都很容易遵循,并且可以通过最小的学习曲线来实现。借助 ClusterControl,流复制设置可以与HAProxy、VIP和 PGBouncer 相辅相成,以将连接故障转移、虚拟 IP 和连接池添加到设置中。
请注意,部署只是生产数据库环境的一方面。保持其正常运行、自动故障转移、恢复损坏的节点以及其他方面(如监控、警报、备份)都是必不可少的。
原文地址:https://severalnines.com/database-blog/how-automate-deployment-postgresql-database?yw
