




1、Redis数据类型
面试的时候关于Redis有哪些数据类型的问题,基本上是最常问的,五种基本数据类型string、list、set、zset、hash也是信手拈来。
不过随着Redis版本的更新迭代,还有四种数据类型不为大家所知,它们分别是bitmap、GEO、HyperLogLog,以及Redis5.0中的Streams。
Redis中的数据类型及底层的数据结构是以编码的方式标识的,下面看看五种基本数据类型的底层数据结构到底有哪些。
1.1、五种基本类型编码表
注意:type命令用于查看键的类型。
| redis类型(type命令输出 ) | 类型编码 |
| string | REDIS_STRING |
| list | REDIS_LIST |
| set | REDIS_SET |
| zset | REDIS_ZSET |
| hash | REDIS_HASH |
1.2、底层数据结构编码表
注意:object encoding命令用于查看键的底层数据结构。
| 底层数据结构 | 底层数据结构编码 | object encoding命令输出 |
| long类型的整数 | REDIS_ENCODING_INT | int |
| embstr编码的简单动态字符串 | REDIS_ENCODING_EMBSTR | embstr |
| 简单动态字符串 | REDIS_ENCODING_RAW | raw |
| 双向链表 | REDIS_ENCODING_LINKEDLIST | linkedlist |
| 压缩链表 | REDIS_ENCODING_ZIPLIST | ziplist |
| 整数集合 | REDIS_ENCODING_INTSET | intset |
| 跳跃表和字典 | REDIS_ENCODING_SKIPLIST | skiplist |
| 字典 | REDIS_ENCODING_HT | hashtable |
1.3、五种基本类型与底层数据结构关联表
| redis类型编码 | 底层数据结构编码 |
| REDIS_STRING | REDIS_ENCODING_INT |
| REDIS_STRING | REDIS_ENCODING_EMBSTR |
| REDIS_STRING | REDIS_ENCODING_RAW |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST |
| REDIS_SET | REDIS_ENCODING_INTSET |
| REDIS_SET | REDIS_ENCODING_HT |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST |
| REDIS_ZSET | REDIS_ENCODING_SKIPLIST |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST |
| REDIS_HASH | REDIS_ENCODING_HT |
2、Redis数据类型的编码转换时机
从1.3中的表我们可以看到,redis的某种数据类型可能对应多种数据结构。通过编码这种机制来将类型与数据结构关联起来,大大提高了Redis的灵活性。一个类型可以有多种数据结构,这样设计的好处归根结底是为了节省空间、提高效率。
下面介绍一下Redis五种基本数据类型的编码转换时机,以及简单介绍一下底层数据结构。
2.1、简单动态字符SDS
由于Redis是C语言编写的,那么先来了解一下C语言的字符串。
C语言使用长度为N+1的字符数组来表示长度为N的字符串,并且字符数组的最后一个元素总是空字符'\0'。
C语言这种简单的表示字符串的方式,并不能满足Redis对字符串在安全性、效率以及功能等方面的要求,因此Redis自己构建了SDS抽象数据类型。
Redis在一些对字符串值无须修改的地方才会使用C字符串,比如打印日志。
比起C字符串,SDS有以下优点:
常数复杂度获取字符串长度;
杜绝缓冲区溢出;
减少修改字符串长度时所需的内存重分配次数;
二进制安全;
兼容部分C字符串函数;
2.2、string类型三种编码的转换
string类型有int、embstr和raw三种编码。
如果一个string类型的值是整数,且这个整数在long范围内,则采用int编码;如果一个string类型的值是字符串且小于32字节,则采用embstr编码,大于32字节则采用raw编码。
embstr是专门用于保存短字符串的一种编码。
2.3、list类型两种编码的转换
list类型有ziplist和linkedlist两种编码。
当list中每个元素都小于64字节,且总长度小于512时,使用ziplist,否则使用linkedlist。
压缩列表是为了节约内存。
2.4、set类型两种编码的转换
set类型有intset和hashtable两种编码。
当set中每个元素都是整数,且总长度小于512时,使用intset,否则使用hashtable。
使用hashtable时,hashtable的key就存储的是set的元素,而hashtable的value恒为null。
2.5、zset类型两种编码的转换
zset类型有ziplist和skiplist两种编码。
当zset中每个元素都小于64字节,且总长度小于128时,使用ziplist,否则使用skiplist。
那么ziplist是如何存储有序集合的呢?
首先有序集合除了元素本身之外,每个元素还有一个分值,ziplist是按分值排序的,具体存储方式如下所示。
| 苹果 | 5.5 | 香蕉 | 6.5 | 西瓜 | 8.0 |
skiplist这种编码其实包含了两种数据结构:跳跃表和字典dict,本文第3节简单介绍了跳跃表这种数据结构。
跳跃表按分值从小到大的顺序存储了zset所有元素,而字典dict存储的是元素与分值的映射,这两种数据结构通过指针共享元素和分值,因此不会产生内存重复的浪费。
那为什么要用两种数据结构表示呢?
字典dict能在O(1)时间内根据元素查找分值,这一点跳跃表办不到;
跳跃表是有序的,因此能快速进行范围查找,而字典dict是无序的,因此这一点字典办不到;
因此结合两种数据结构的优点就是提升性能。
2.6、hash类型两种编码的转换
hash类型有ziplist和hashtable两种编码。
当hash中每个key和value都小于64字节,且总长度小于512时,使用ziplist,否则使用hashtable。
用ziplist存储时具体的存储结构如下所示。
| name | 张三 | age | 10 | sex | 男 |
3、跳跃表
普通单链表查询一个元素的时间复杂度为O(n),即使该单链表是有序的,我们也不能通过2分的方式缩减时间复杂度。
跳跃表是一种有序数据结构,跳跃表平均时间复杂度O(logn)、最坏时间复杂度O(n),大部分情况下,跳跃表效率可以与平衡二叉树相提并论,并且比平衡二叉树更简单。
一个理想的跳跃表如下图所示,每一层的结点数都是下面一层的二分之一,这跟二分法差不多。
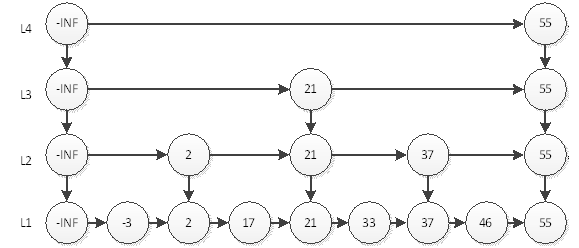
但是如果要在理想的跳跃表上增删元素,调整一个理想的跳跃表将是一个比调整平衡二叉树还复杂的操作,因此在使用编程语言去实现的时候,并不会实现一个理想的跳跃表。
当Redis的有序集合中元素比较多的时候,会采用跳跃表这种数据结构。

