




背景
在生产环境中,经常会遇到这样的情况:客户在主实例对一个没有索引的表执行大批量数据的update或delete操作。如果主从采用ROW模式复制,主库只需要全表扫描一次,从库却需要对主库影响的每一行数据都做一次全表扫描,往往会造成从库非常大的同步延迟,这种情况一般不能被业务所容忍。
MySQL 5.6.6开始引入参数slave_rows_search_algorithms,用于指示只读实例apply_binlog_event时使用的算法,在一定程度上可以解决(缓解)同步延迟问题。下面重点介绍该参数的原理及使用。
问题现象
线上场景
主实例配置:
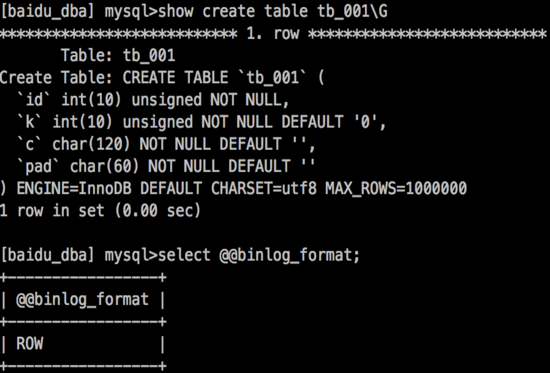
只读实例配置:
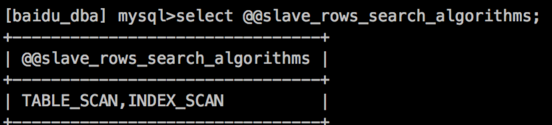
主实例执行:

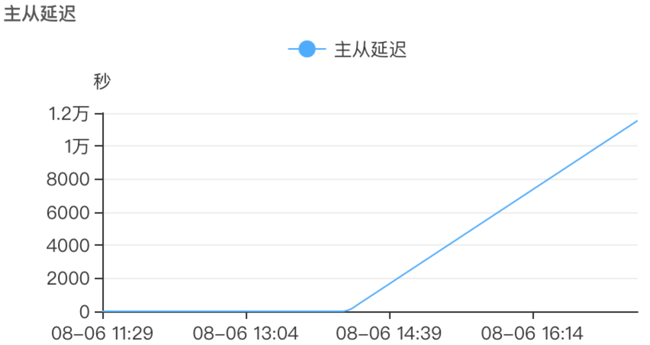
只读实例同步延迟,趋势图如下:
slave_rows_search_algorithms参数的影响
主实例表结构:
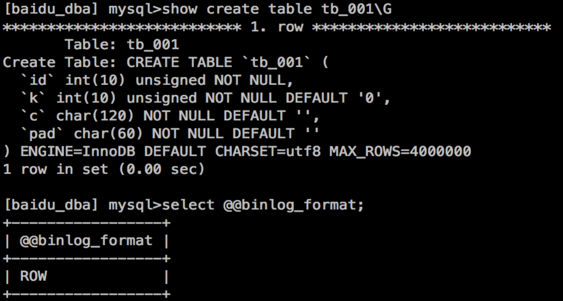
其中表tb_001有400万条数据。
主实例执行SQL:
update tb_001 set k=k+12345 limit {$LIMIT_NUM};
测试结果——只读实例的最大延迟时间:
更新行数 TABLE_SCAN,INDEX_SCAN TABLE_SCAN,INDEX_SCAN,HASH_SCAN 10000 28s 4s 20000 144s 17s 30000 325s 35s 40000 576s 64s 由测试结果可以看出,修改参数slave_rows_search_algorithms加入HASH_SCAN后,对于无主键且无其他索引的表,同步延迟有很大改善。
原因分析
首先,假定binlog_format_image采用默认值FULL,这样可以将所有操作的before_image和after_image全都记在event中。slave_rows_search_algorithms
默认值为TABLE_SCAN,INDEX_SCAN。下面我们进行详细分析。
有主键或唯一索引
测试的表结构和执行的update语句:
对于这个update语句:主库执行时会首先利用主键,只需要一次索引定位,然后顺序扫描接下来的数据进行更新就可以了。大概的流程如图:
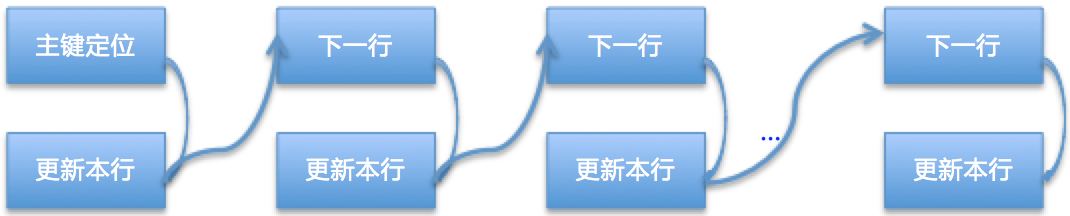
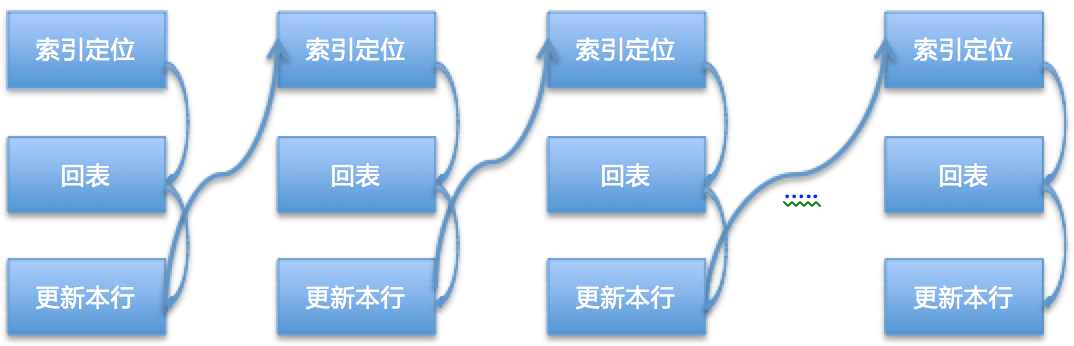
这条SQL更新的20条数据的before_image都会记录到Update_rows_event里,从库应用的时候会重新评估应该使用哪个索引,优先使用主键和唯一键。因为测试的表含有主键,从库执行的时候对于Event中的每条数据都需要通过主键进行定位到具体的行,然后进行相应行的更新即可。
对于主库来说,只需要一次数据定位即可;从库需要对影响的所有行都做一次数据定位,因为表有主键(唯一索引也可以),将从库数据定位的代价降到了最低。
无主键和唯一索引
测试的表结构和update语句:
对于这个update语句,更新20条数据,主库会首先利用索引key进行一次性定位,然后顺序更新接下来的数据行即可。大概的流程如图:
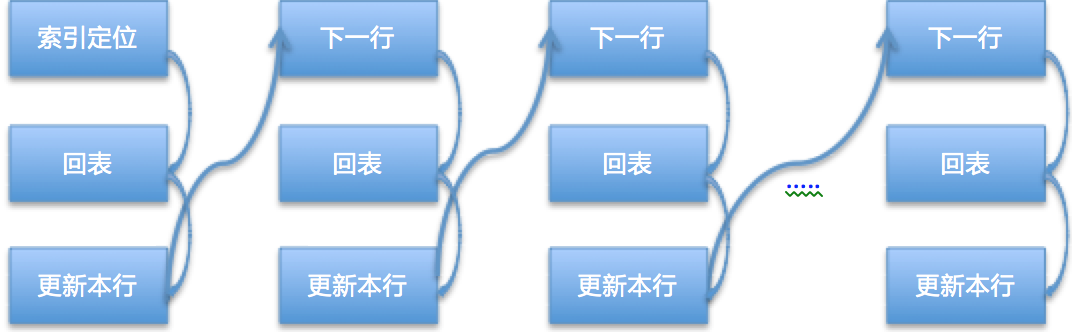
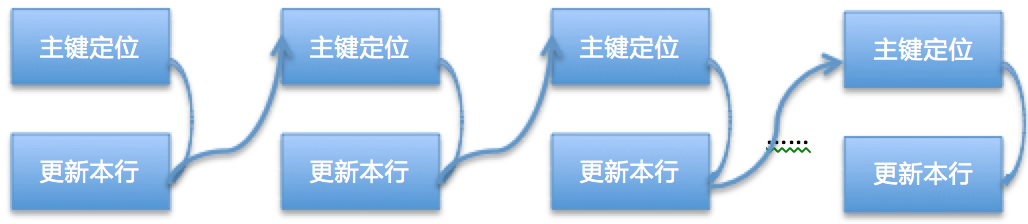
这条SQL更新的20条数据的before_image都会记录到Update_rows_event里,从库应用的时候会重新评估应该使用哪个索引,优先使用主键和唯一键。因为表只有一个普通索引key,对于Event中的每条数据都需要进行索引定位操作,并且对于非唯一索引来讲第一次返回的第一行数据可能并不是删除的数据,可能还需要继续扫描下一行。大概的流程如图:
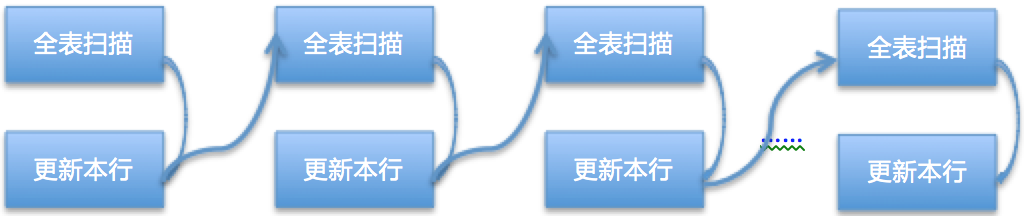
如果表上一个索引都没有的话,从库执行的每个event都要进行全表扫描,代价非常大,这也是表上没有索引从库会有比较大同步延迟的关键原因。大概的流程图:
无索引的优化
slave_rows_search_algorithms有以下4种组合:
- TABLE_SCAN,INDEX_SCAN(默认值)
- INDEX_SCAN,HASH_SCAN
- TABLE_SCAN,HASH_SCAN
- TABLE_SCAN,INDEX_SCAN,HASH_SCAN(同INDEX_SCAN,HASH_SCAN)
参数组合,Decision table:
- I --> Index scan / search
- T --> Table scan
- Hi --> Hash over index
Ht --> Hash over the entire table
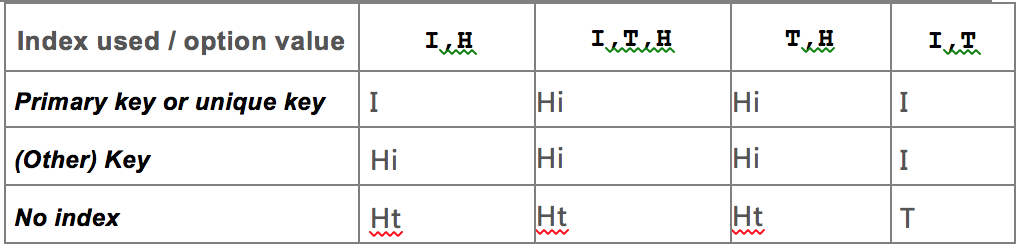
- 默认值 TABLE_SCAN,INDEX_SCAN ,意味着如果有可用的索引则使用索引搜索,否则使用全表扫描。INDEX_SCAN,如果有可用的索引,则使用索引进行搜索。TABLE_SCAN,没有索引,也没有配置HASH_SCAN的情况下,采用全表扫描。
- 只读实例定位数据可选项INDEX_SCAN、HASH_SCAN、TABLE_SCAN,优先级是依次递减的。如果有主键或索引,走INDEX_SCAN,没主键则根据设置走 HASH_SCAN 或者 TABLE_SCAN(而且如果两者都配了,则优先HASH_SCAN)。
源码:sql/ log_event.cc
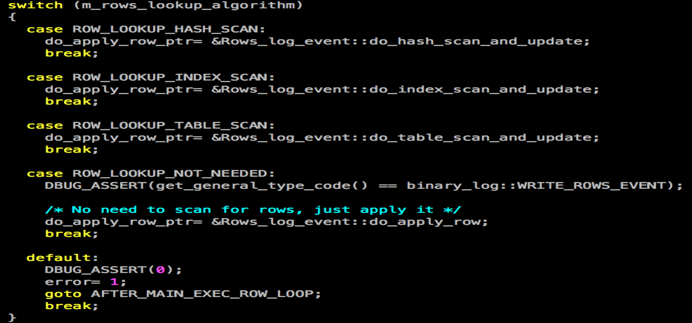
其中,我们只关注ROW_LOOKUP_HASH_SCAN,其包含两种数据查找的方法:
- Hi -> Hash over index
- Ht -> Hash over the entire table
只读实例在apply rows_log_event时,会将 log_event 中每一行数据读取出来更新缓存在两个结构中,分别是:m_hash和m_distinct_key_list。
- m_hash:用来缓存更新行记录起始位置的hash表;
- m_distinct_key_list:如果有索引,则将索引的值push 到m_distinct_key_list,作为索引扫描依据,即Hi(每EVENT都会查询m_distinct_key_list进行定位)。
如果表没有索引,则不使用这个List结构,则直接使用全表扫描,即Ht(每个EVENT都会查询m_hash进行定位);
需要注意的是:对于Hi --> Hash over index,每次update/delete的数据重复值很少的话,依然需要很多的索引定位,如果每次update/delete的数据重复值比较多,可大大减少索引定位的代价。
结论建议
建议每张表都有主键或唯一键。可以使用下面SQL确认您的库表是否都含有主键:
select table_schema,table_name,engine from information_schema.tables where (table_schema,table_name) not in( select distinct table_schema,table_name from information_schema.columns where COLUMN_KEY='PRI' ) and table_schema in ('${dblist}');
其中${dblist}为以逗号分割的数据库列表。
- 从库索引的利用是自行判断的,顺序为主键->唯一键->普通索引,建议每张表都设置主键或唯一键
就算设置了HASH_SCAN也不一定就能提升性能,需要满足下面任一条件:
(1) 表中没有任何索引
(2) 表中有索引,但是update/delete的数据key重复值较多
- 每个update/delete语句只修改少量的数据(比如每个语句修改一行数据)并不能提高性能
- 建议将线上环境slave_rows_search_algorithms的默认值设置为INDEX_SCAN,HASH_SCAN(8.0.2以后改成了默认值)
- 如果slave_rows_search_algorithms参数没有设置HASH_SCAN,并且没有主键/唯一键那么性能将会急剧下降造成延迟。如果连索引都没有那么这个情况更加严重,因为更改的每一行数据都会引发一次全表扫描。




