




ICP介绍
Index Condition Pushdown(ICP)是MySQL 5.6中新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式。ICP可以减少存储引擎访问基表的次数以及MySQL服务器访问存储引擎的次数。
当MySQL使用索引从表中检索行时,索引条件下推(ICP)是一种优化。
-
在禁用ICP的情况下,
存储引擎遍历索引以定位基表中的行,并将它们返回给Server层,Server层再去为这些数据行进行where条件的过滤。 -
在启用ICP的情况下,
如果只使用索引中的列就可以计算WHERE条件的部分内容,那么MySQL服务器将WHERE条件的这部分内容下推到存储引擎。存储引擎然后通过使用索引条目来计算推入索引条件,只有满足了这个条件才从表中读取行。
实现方式
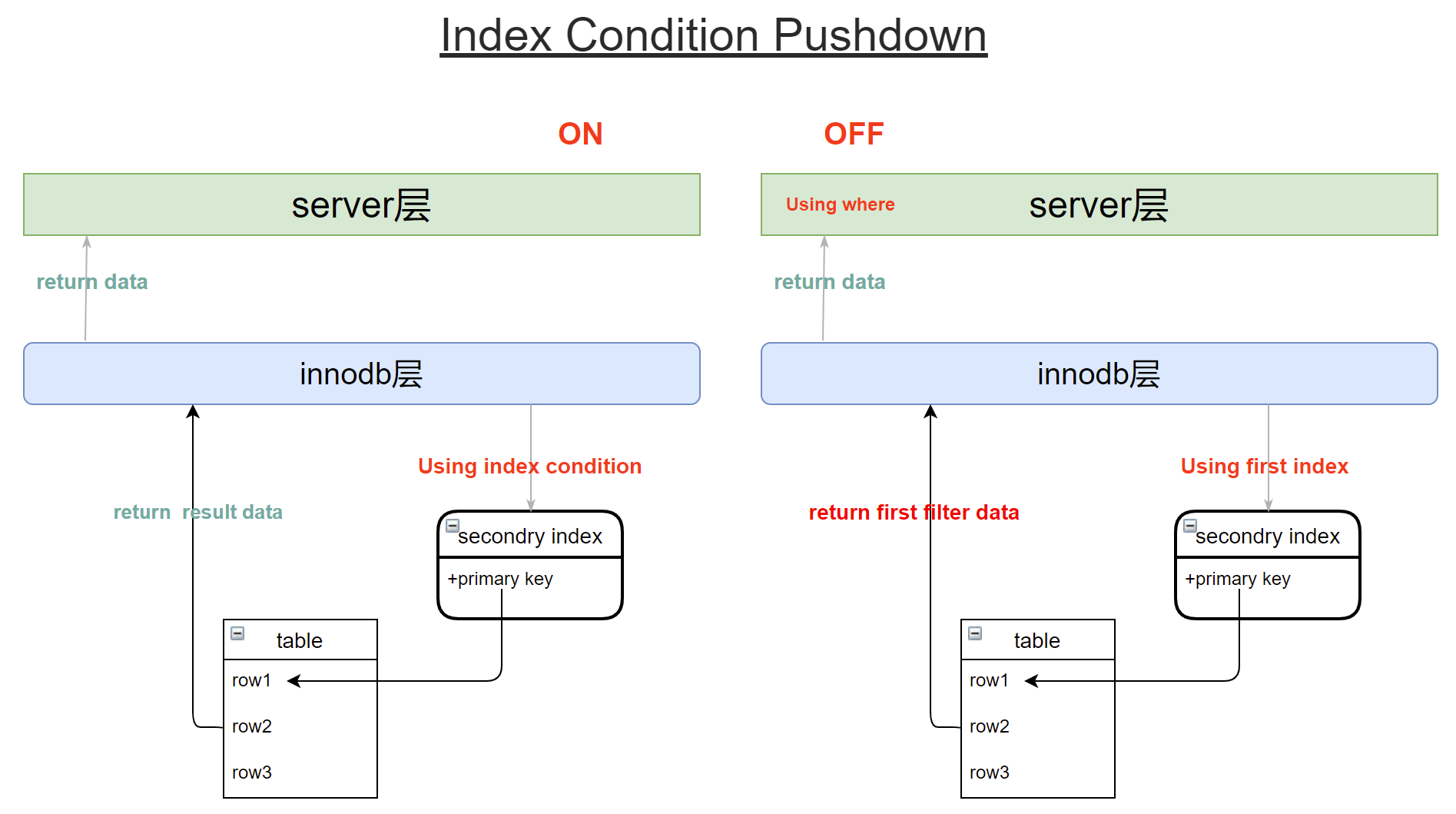
备注:
ICP的目标是减少整行读取的数量,从而减少I/O操作。同时减少server层和innodb层的数据交互,并且避免server层数据处理,server层更多的资源用在协调上。
执行计划
通过EXPLAIN上通过Extra信息里 Using index / Using index condition 进行区分。
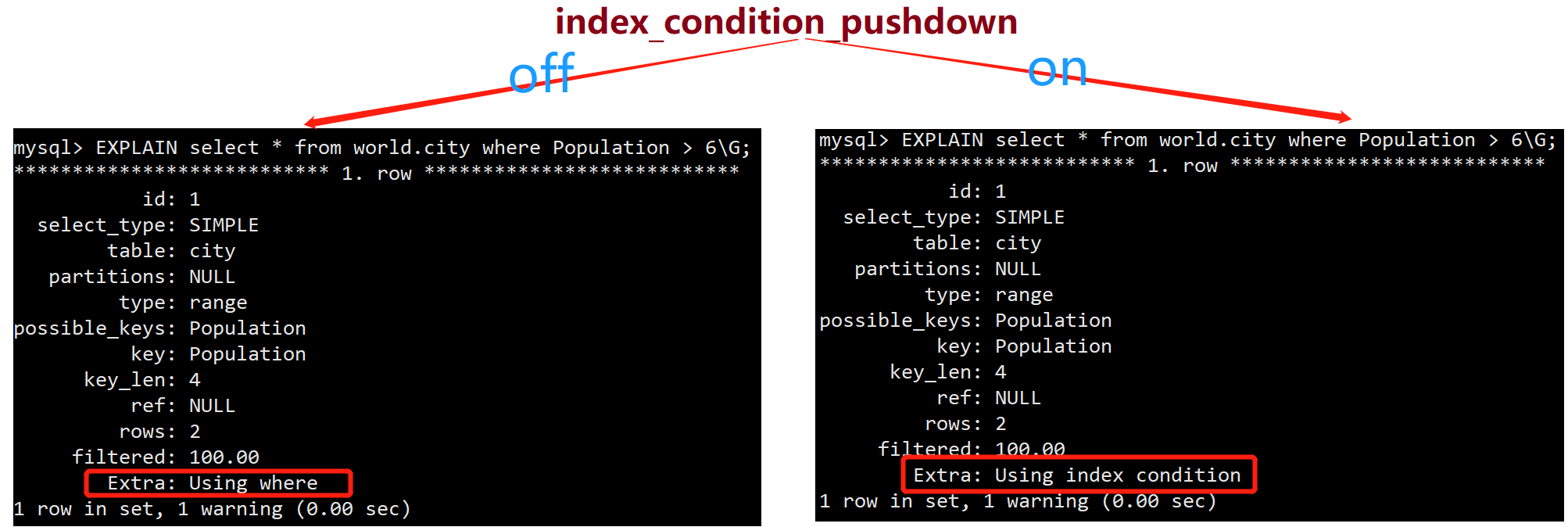
控制参数
mysql> SHOW VARIABLES LIKE 'optimizer_switch'\G;

ICP使用条件:
- ICP用于range、ref、eq_ref和ref_or_null访问方法。
- ICP可以用于InnoDB和MyISAM表,包括分区表。
- 对于InnoDB表,ICP只用于二级索引
- 虚拟生成的列上创建二级索引时,不支持ICP。
- 引用存储函数的条件不能下推
- 无法下推触发的条件
- 引用子查询的条件不能下推。
ICP对于IO影响,通过STATUS观察
#创建表
CREATE TABLE `tuser` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` tinyint DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_age_name` (`age`,`name`)
) ENGINE=InnoDB;
#模拟数据
DELIMITER //
DROP PROCEDURE IF EXISTS proc_batch_insert;
CREATE PROCEDURE tuser_batch_insert()
BEGIN
DECLARE pre_name BIGINT;
DECLARE ageVal INT;
DECLARE i INT;
SET pre_name=139;
SET ageVal=100;
SET i=1;
WHILE i <= 2000 DO
INSERT INTO tuser(`name`,age,create_time,update_time) VALUES(CONCAT(pre_name,'@qq.com'),(ageVal+1)*rand()%30,NOW(),NOW());
SET pre_name=pre_name+100;
SET i=i+1;
END WHILE;
END //
DELIMITER ;
#执行模拟数据
call tuser_batch_insert();
#测试语句
FLUSH STATUS; #刷新统计计数
SHOW STATUS LIKE '%Handler_read%';
SET optimizer_switch="index_condition_pushdown=off";
SET optimizer_switch="index_condition_pushdown=on";
SELECT * FROM tuser WHERE age > 29 AND name LIKE '%639@qq.com';
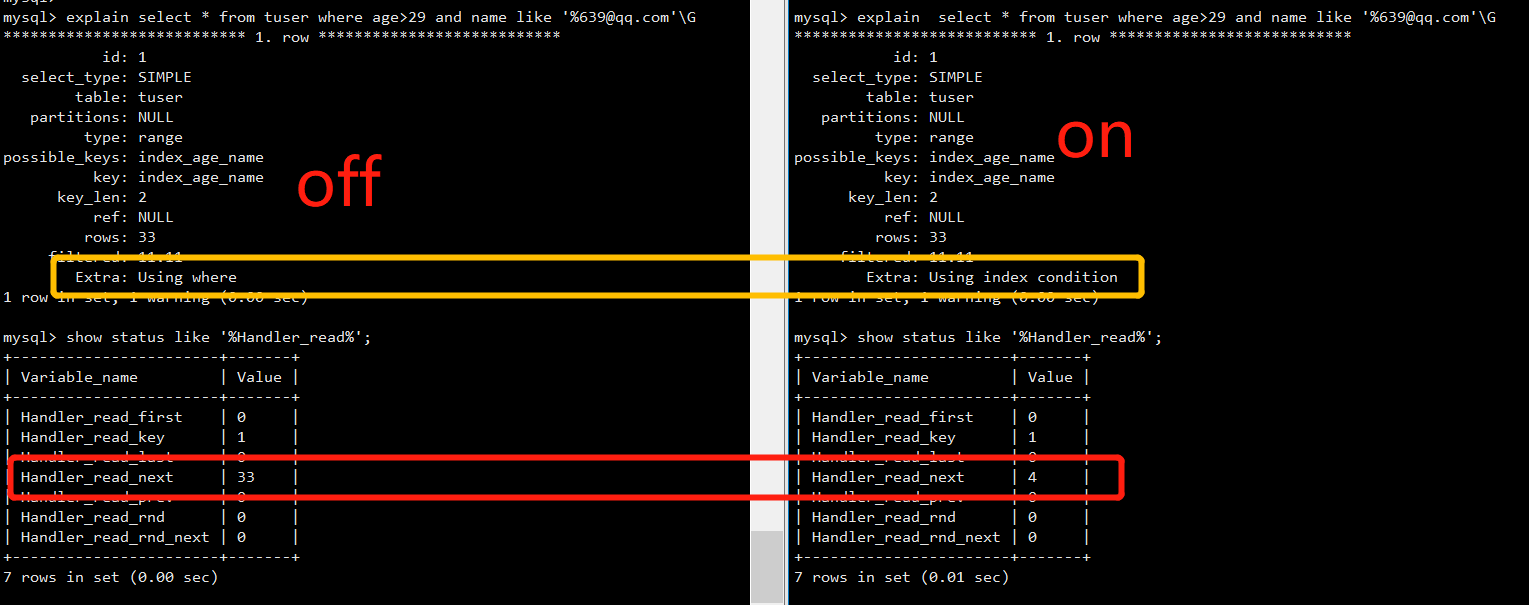
指标观察:
- Handler_read_first:此选项表明SQL是在做一个全索引扫描,注意是全部,而不是部分,所以说如果存在WHERE语句,这个选项是不会变的。
- Handler_read_key:此选项数值如果很高,那么恭喜你,你的系统高效的使用了索引,一切运转良好。
- Handler_read_next:此选项表明在进行索引扫描时,按照索引从数据文件里取数据的次数。
- Handler_read_prev:此选项表明在进行索引扫描时,按照索引倒序从数据文件里取数据的次数,一般就是ORDER BY … DESC
- Handler_read_rnd:就是查询直接操作了数据文件,很多时候表现为没有使用索引或者文件排序。
- Handler_read_rnd_next:此选项表明在进行数据文件扫描时,从数据文件里取数据的次数。
备注:这里Handler_read_next索引扫描时,按照索引从数据文件里取数据的次数,明显差距非常大。
OPTIMIZER_TRAC进行观察:
refine_plan:
该阶段展示的是改善之后的执行计划,如执行计划中没有需要再优化的地方,可直接应用:
SHOW VARIABLES LIKE 'optimizer_switch';
SET OPTIMIZER_TRACE="enabled=on";
SELECT * FROM tuser WHERE age > 29 AND name LIKE '%639@qq.com';
SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE limit 30 \G;
SET OPTIMIZER_TRACE="enabled=off";
mysql> SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE limit 30 \G;
*************************** 1. row ***************************
。。。
{
"refine_plan": [
{
"table": "`tuser`",
"pushed_index_condition": "((`tuser`.`age` > 29) and (`tuser`.`name` like '%639@qq.com'))",
"table_condition_attached": null
} ]
}
- table:涉及的表名及其别名
- pushed_index_condition:可使用到ICP的条件句
- table_condition_attached:在attaching_conditions_to_tables阶段添加了附加条件的条件语句
- access_type:优化后的索引访问类型
总结
ICP是使用场景是二级索引,ICP的加速效果取决于筛选掉的数据的比例
- 减少了回表的IO
- 降低了innodb引擎层传递到server层的成本
- 比如 select for update更新数据 ,ICP大大减少行锁的数量,因为行锁是在引擎层。
最后修改时间:2022-12-27 13:43:48
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
目录
