编码
编码的介绍
程序开发经常会遇到编码的问题,在学习Python这门语言之前,我们先来搞清楚编码是什么以及你未来会遇到什么样的编码问题。
首先我们来看一下计算机语言中最常见的几种编码格式:
1.ASCLL (American Standard Code for Information Interchange) 美国标准信息交换代码,为美国英语通信所设计,由128个字符组成,包括大小写字母、数字、打印字符及控制字符组成,Python2源码文件默认使用ASCLL编码。
2.GB2312(GuoBiao) GBK(GuoBiao Kuozhan) GB2312是国家标准总局在1980年发布的适用于汉字处理、通信等系统之间信息交换的编码格式,共收录汉字6763个,同时兼容ASCLL编码。GBK属于GB2312的扩展,由于中国的文字太多了,GB2312完全满足不了一些人的需求,所以在GB2312的基础上增加了新汉字、少数民族文字、繁体字等,同时兼容GB2312编码。再后来我们又增加了一些少数民族文字,于是就有了GB18030。
3.Unicode Unicode又被称为统一码,万国码。世界上的大多数国家都有自己的编码格式,像中国的GBK,日本的EUC-JP,泰国的TIS-620等等,这些国家在制定标准的时候肯定也就是涵盖了本国的字符,不会闲的去制定别国的标准(此处@美利坚),这样各个国家之间的字符并没有关联性,导致最常见的问题就是乱码,就这样Unicode应运而生了。世界上所有的字符在Unicode码里面都有单独对应的关系,全世界的人都可以使用这种编码且不用考虑语言上的区分了。
4.UTF-8 (8-bit Unicode Transformation Format) UTF-8是针对Unicode的一种可变长度字符编码,它可以用来表示Unicode标准中的任何字符,简单来说就是因为Unicode太占内存了,为了解决存储和传输效率的问题,然后诞生了UTF-8。它同时兼容ASCLL编码,但是它不兼容GB为前缀的编码格式,Python3源码文件默认使用UTF-8编码,其中英文占用1字节的位置,中文占用3-4字节的位置。
编码的转换
虽然我们有了Unicode和UTF-8,但是由于一些原因,各个国家依然在使用自己的编码,就像我们国家的windows的默认编码依然是GBK。假如我们的GBK编码的软件出口到其他国家,就会显示乱码,因为在他们的操作系统上并没有GBK的编码格式。那如果想让中国出口的软件在其他国家的操作系统上正常运行,该如何解决呢?
1.在全世界的操作系统装上GBK编码。
2.把GBK的软件转编成UTF-8软件。
第一种方法,虽然我们国家的文字在世界范围内影响颇深,但是别人不一定愿意这么做,就算愿意,微软可能也不愿意付出这个成本和精力。你要知道这个世界上的计算机是数以百亿计算的,还有很多没有联网的计算机是很难通过打补丁的形式来解决这个问题的。
第二种方法,这个方法比较简单,但是如果这个软件的代码量是上百万行的,重新转编成UTF-8也是非常耗费时间和金钱的。
以上的两种方法都没有很容易的解决这个问题,那就没有别的方案了吗?还记得我们前面提过的Unicode编码吗,所有的系统、编程语言都支持Unicode编码,只需要将GBK软件的数据从硬盘读取到内存里,转成Unicode来显示,中文就可以正常显示啦~
编码的设置
在Python中有两种常用设置编码的方法:
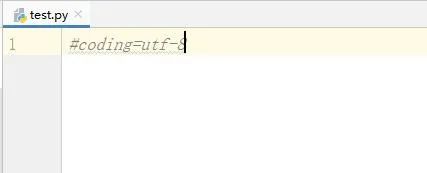
1.代码设置
在代码文件第一行加上
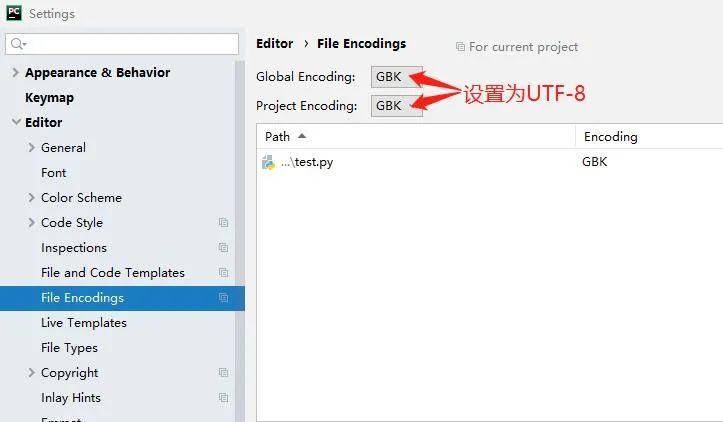
2.IDE设置
打开File->setting->Editor->File Encodings
编码的常见问题
1.SyntaxError: Non-UTF-8 code starting with '\xc4' in file ... on line 1, but no encoding declared;
这种问题可以通过上面的设置来解决。
2.UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 1: invalid start byte
这种问题一般会出现在读取GBK编码的文件时候发生,只需将open()的encoding设置为GBK即可,当然也可以把源文件转编成UTF-8格式。
文件的编码鉴别
在这里教大家一个Python鉴别编码格式的方法
import chardet
f_1 = open('test.txt', 'rb') # 注意此处打开方式 'rb'
str_1 = f_1.read()
chardet_1 = chardet.detect(str_1)
print(chardet_1)
#打印结果
{'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}复制
相信看完这篇文章,你对编码格式也有了一些了解,如果你遇到了更为复杂的问题,欢迎给川哥私信留言。