




1、Mysql索引数据结构详解
1.1 索引数据结构介绍
什么是索引
1. 索引是排好序的数据结构,相当于教科书的目录
2. mysql是b+树的数据结构, 每查一次索引都查一次磁盘IO,索引的组成相当于key是索引,value是文件指针指向下一个叶子节点
3.

数据结构网址
1. https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
2.

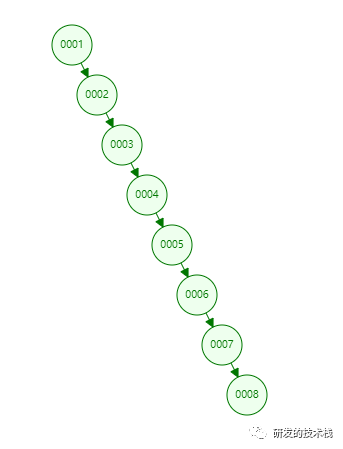
二叉树特性
1. 右边子元素大于父元素,左边子元素小于父元素
2. 缺点:如果字段是递增,一直向右增长,变成线性链表了,查询就很慢,相当于全表扫描了
3. 效果图:
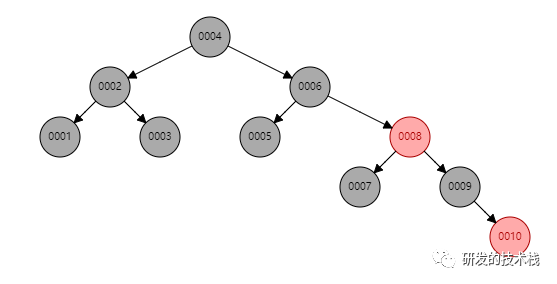
红黑树特性
1. 也叫二叉平衡树, 通过左旋和右旋进行自旋转平衡, 解决二叉树“线性链表”的问题
2. 缺点:在大量数据,例如500w数据, 每个节点只存储一个键值和数据的,树深,高度为2的N次方,树高仍然不可控
3. 效果图:
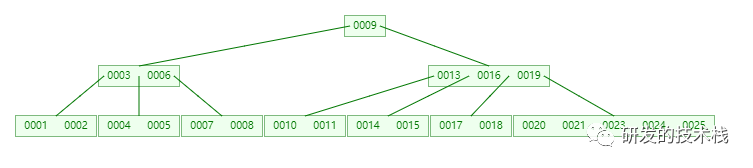
B-树特性
1. 红黑树进行横向扩容就是b-树,每一个节点存储空间变大,横向扩展,降低树的高度
2. 所有索引元素不重复
3. 节点中的数据索引从左到右递增排列
4. 缺点:mysql节点中innerDB存储引擎存储的是字段,存储空间占用会很大,mysql每个节点容量推荐是16K,字段会导致横向存储索引变少,数据量很大时, 这样树的高度还是会很高
5. 效果图:
a. 设置每个节点存5个字段,超过5个字段会从中间进行分裂
b.
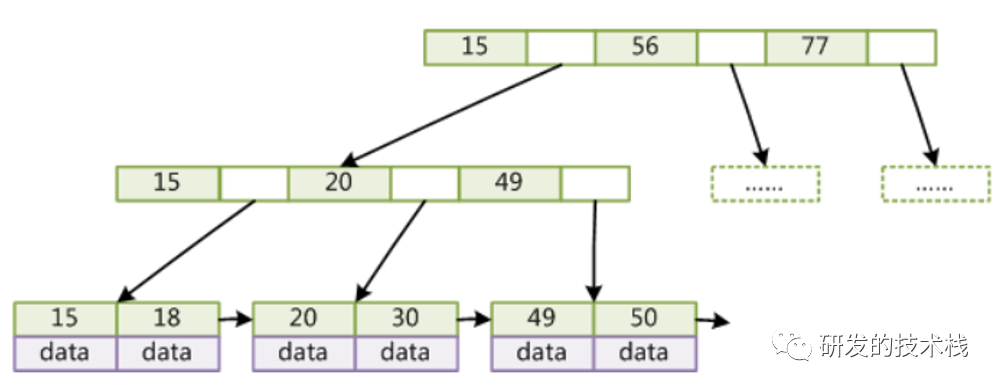
B+树特性(多路平衡树)
1. B-树变种
2. 非叶子节点不存字段,只存索引(冗余),可以放更多索引,相当于中间叶子节点做冗余放到非叶子节点
3. 叶子节点包含所有索引和字段
4. 叶子节点用指针连接,提高区间访问的性能(b+树底层是单向指针,mysql做了改进是双向的指针,好处:可以很好的做范围查找)
5. 查找到的叶子节点加载到内存中进行查找
6. 效果图:
a. 设置每个节点存5个字段,超过5个字段会从中间进行分裂

1.2 B+树索引怎么⽀撑千万级表的快速查找
1. 每个节点默认可以存16KB数据, 除以14B(索引8Byte + 文件指针地址6Byte)=1170个单索引元素和1170个指针
2. 3层高的树存储数据计算
a. 第一层是一个非叶子节点存储1170个索引
b. 每一个索引对应一个第二层的非叶子节点, 那么第二层1170个非叶子节点
c. 第三层就是1170个索引乘以1170个非叶子节点等于1368900个叶子节点,第三层的每个叶子节点就可以存储16kB的索引加数据
3. 结论: 3层高的树,1170*1170*16约等于两千多万kb的数据,假设1kb就是一条数据,就是两千多万条数据,经历3次磁盘io就查询出来,叶子节点的16kb数据在加载到内存中进行快速查找
4. B+树一般有2到4级,但很少用到4级,大多数是小于等于3,所以一般超过2千万以后,就要做分库分表了
5. 图示:
1.3 mysql的MyISAM和InnerDB存储引擎区别
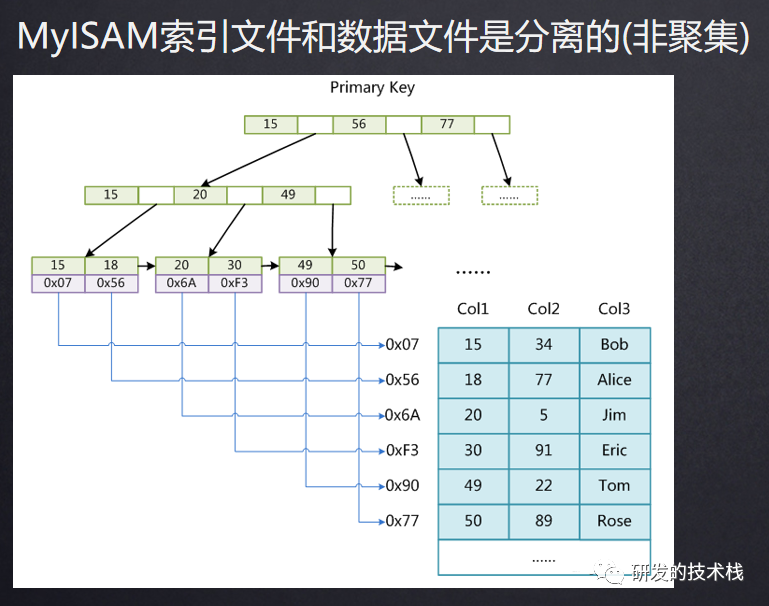
MyISAM:⾮聚集索引
1. 索引和数据分开存储
2. 通过索引查找到指针加载到内存,在到表数据行直接拿到数据
3. 主键索引和非主键索引结构一样
4. 由于MyISAM存储引擎不支持事务,也不支持行级锁,如果频繁插入和更新的话,因为涉及到数据全表锁,效率并不高,所以我们通常选择使用InnerDB存储引擎, 如果表中绝大多数都只是读查询,可以考虑MyISAM
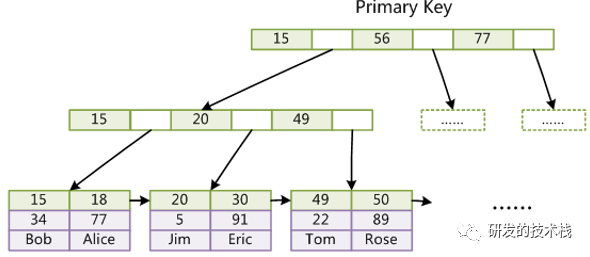
InnerDB:聚集索引
1. 索引和数据放到一起,把指针和数据全都放在了叶子节点,主键索引会和数据放在一起
2. 所以表数据文件本身就是B+Tree组织的一个索引结构文件
3.
思考: 为什么inndb表必须有主键,并且推荐使用整型的自增主键
1. 原因就是主键是用B+树来组织存储,如果mysql在表中找不到主键,会自己建一个rowid自增的字段
2. 推荐使用整型做主键,不用uuid做主键,因为查找索引需要大量的索引比较,int类型比较最快,字符串比较会很慢,而且字符串占用存储空间很大
3. 推荐使用主键自增插入,如果不是自增的新主键数据,比如uuid主键, 可能会在已经存储满的节点强行存储就会导致大量树分裂,效率低下,而主键自增按顺序往后扩展就可以了,分裂频率低
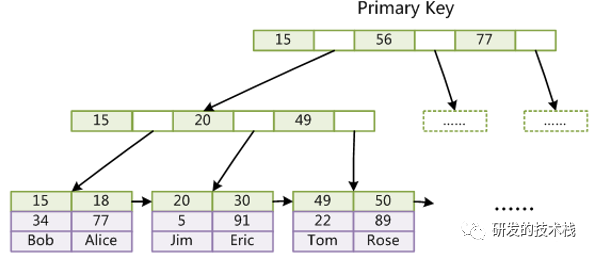
innerdb的非主键索引的底层存储原理
1. 非主键索引结构叶子节点存储的是主键值
2. 非主键索引在查找出来的是对应的主键元素后,在根据主键元素再重新遍历一次,查找两边导致性能相对于主键低一些
a. 这么设计的原因是为了保证数据一致性和节省存储空间
b. 数据新增的时候只插入到主键索引对应的数据里,但如果在非主键索引也插入数据可能会导致数据不一致的问题,空间也会浪费,完整的数据只需要存一份就可以了
3. 主键索引存储图
4. 非主键索引存储图
2、Mysql执⾏计划与索引详解
2.1 explain命令⼯具介绍
1. 遇到慢查询时,可以用explain分析查询语句与性能瓶颈
2. 用法: explain+sql语句
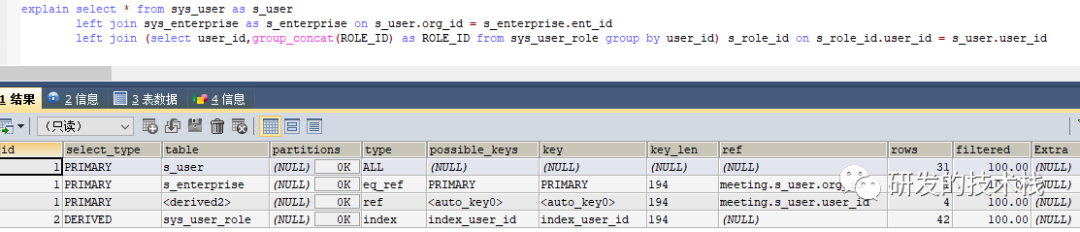
explain执⾏结果具体参数介绍
1. id:代表几个select查询语句,顺序排序,id值越大优先级越高,如果相等则谁先出现谁先执行,id为null最后执行
2. select_type:代表简单查询还是复杂查询
a. simple:代表简单的 select 查询,查询中不包含子查询或者UNION

b. primary:代表查询中若包含任何复杂的子部分,最外层查询则被标记为Primary

c. subquery:代表在SELECT或WHERE列表中包含了子查询

d. derived:from后面的子查询,衍生查询类型

e. union:union后面的表类型
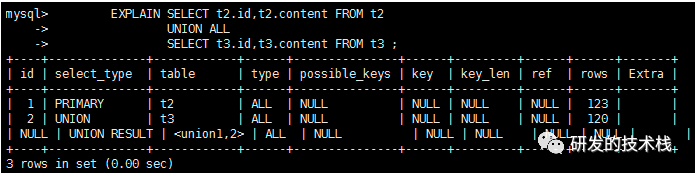
3. table:显示查询的那张表名,如果是`<derived2>`代表衍生出来的表,其中的id代表被衍生表的id
4. partitions:用分区表显示,基本不用,分库分表给替代了
5. type(重要): 常用结果集性能由高到低system>const>eq_ref>ref>range>index>all
a.system:属于const特例, 系统表,少量数据,往往不需要进行磁盘IO

b.const:结果集查询小于等于1

c.eq_ref:主键key或uniquekey唯一索引被连接查询
user表的id是主键索引,user_balance表的uid也是主键索引
 d.ref:使用普通索引或唯一索引部分前缀
d.ref:使用普通索引或唯一索引部分前缀
user表的id是主键索引,user_balance表的uid是普通索引
 e.range:范围查找in,between,>等走索引查找
e.range:范围查找in,between,>等走索引查找
 f.index:扫描全表索引,查询所有但所有字段都在索引里面,比all快
f.index:扫描全表索引,查询所有但所有字段都在索引里面,比all快
user_id是主键索引,查询所有user_id就会走index类型,也就是覆盖索引
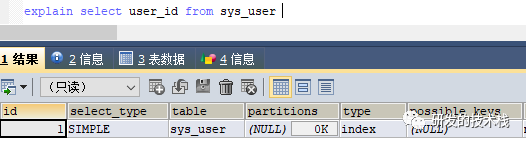 g.all:全表扫描,最慢
g.all:全表扫描,最慢
id上没建索引,所以全表扫描
 h.尽量保证所有type优化在range以上,如果是查询表中所有尽量走index覆盖索引,而不走all类型
h.尽量保证所有type优化在range以上,如果是查询表中所有尽量走index覆盖索引,而不走all类型
6. possible_keys:可能会用到索引字段名称
a. 举例:
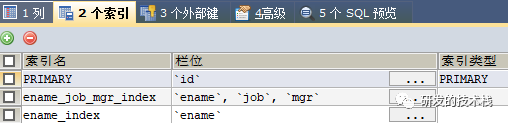

7. key:确定用到的索引字段名称
8. key_len:推断联合索引用到哪几个字段的长度总和
9. ref:显示key列记录的索引中,表查找值用的是常量值或字段名,常见有:const(常量,例如:where id=1),字段名(例如:id=user.id)
10.rows:mysql估计检测的行数,并不是结果集里的行数(rows是预估值并不一定准确)
11.filtered:按表条件过滤的行百分比,一般用不到, 不做重点了解
12.Extra:展示额外的附加信息,情况有很多,可能设计的不好,仅供参考
a. usingindex:覆盖索引,查询出的字段结果集都使用了索引。

b. usingwhere:where语句处理结果,查询的列未被索引覆盖。
comm列并没有加索引

c. usingtemporary:临时表,例如:distinct去重,优化加覆盖索引变成usering index。


d. usingfilesort:排序没索引需要优化。
comm列没加索引

2.2 联合索引最左前缀法则
什么是联合索引
1. 联合索引又叫复合索引。对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。
2.
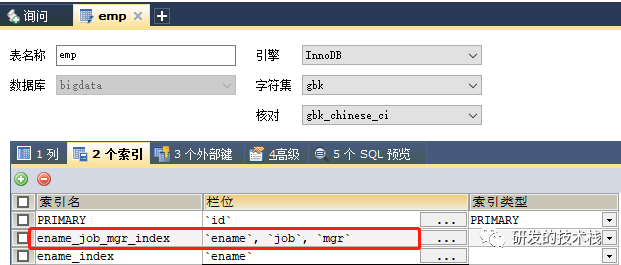
3. 数据存储结构图示:
联合索引不按照最左前缀法则会失效,比对逻辑:
1. 如果是3个字段a,b,c来联合建索引,查询顺序为从左到右,先查找第一列字段,在查找第二列,在查找第三列
2. 有效范围:(a) (a,b) (a,b,c)
a. 如果where条件直接从第二列或第三列开始查,那就要扫描所有索引,扫描全表
b. 如果where条件查第一列和第三列,那么只有第一列走了索引,第三列不走索引查找

c. 如果where条件后面三列都有,但是没有按照索引顺序去筛选,mysql会自动优化顺序

在索引列上加一些函数,索引还会生效么
1. 会失效,强调不要在索引列上做任何操作(例如:计算,函数,(自动or手动)类型转换),会导致索引失效而转向全表扫描
a. 例如:where date(hiredate)='2020-08-23' , hiredate字段加了索引
效果:

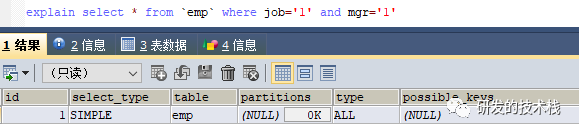
联合索引中部分索引加了范围条件后,右边的列索引会失效
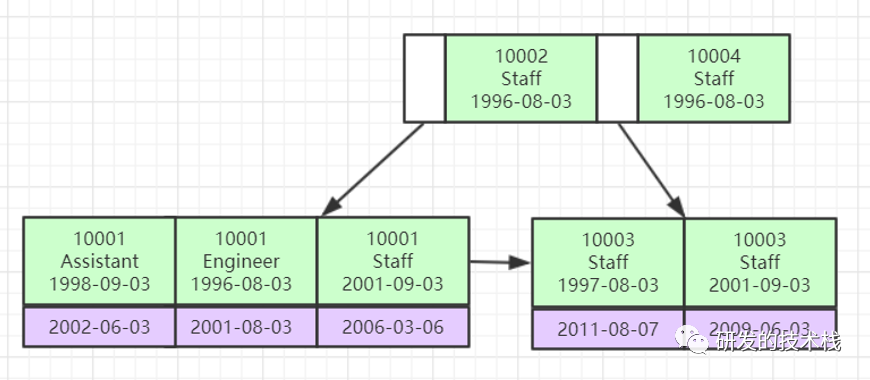
1. 例如:select * from `emp` where ename='ICLYLH' and age=100 and mgr='1', 对ename,age,mgr这三个列建了联合索引,是可以正常走索引的

2. 但如果对age进行范围查找mgr索引就会失效
a. select* from `emp` where ename='ICLYLH' and age>100 and mgr='1'
由于age用了范围查找,mgr就不能用b-tree快速查找了,只能在ename与age的结果集轮询查找了

2.3 覆盖索引
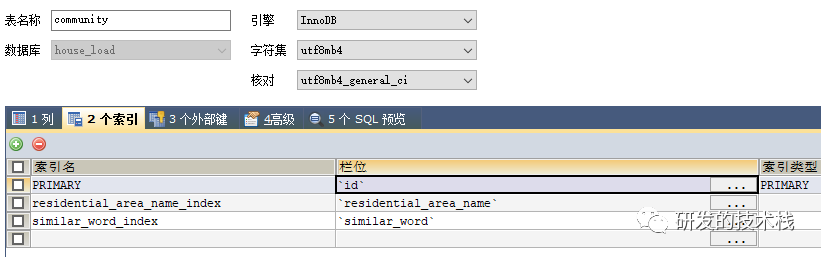
1. 索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引,MySQL只能使用B-Tree索引做覆盖索引(简单说就是在二级索引文件中查找字段)

2. 带where条件的sql语句,where条件后的字段索引一定要包含返回字段索引,例如:
a. 建了两个索引
b. 正确用法:在similar_word_index索引中查找similar_word
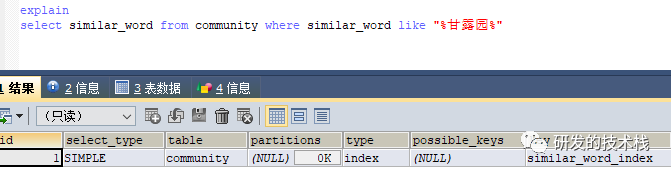
c. 错误用法:在similar_word_index索引中找residential_area_name_index索引中的值
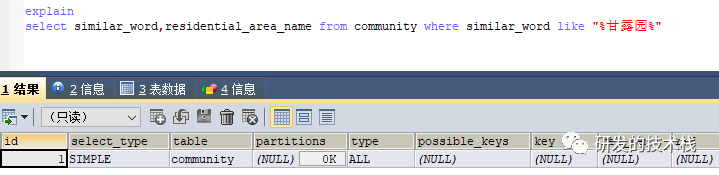
3. Extra:usingindex(覆盖索引的标志)
4. 尽量只访问带有索引列的查询,不用`select *`语句不走索引查询
//优化实例sqlselect * from community cinner join (select id from community where residential_area_name like concat("%甘露园%") and city_id=110100 andbusiness_type=2unionselect id from community where similar_word like concat("%甘露园%") and city_id=110100 andbusiness_type=2) cy on c.id = cy.id limit 10
· 执行计划

2.4 索引失效情况
前提:ename建立了索引
1. mysql使用不等于!=的时候不走索引
2. sql使用了is null,is not null不走索引
3. like通配符%放前面,不走索引
4. 字符串不加单引号查询,索引失效
a. (原因是底层做了一次转换,相当于函数操作了也不会走索引)
5. 少用or做范围查询,用它连接时会索引失效
3、SQL索引优化实战
分页查询优化
1. 问题:数据量越大,越往后查越慢
a. 例如: select * from emp limit 2900000,10
2. 优化方案
a. 根据自增且连续的主键排序分页查询,优化方案:select * from employee where id>90000 limit 5;走了主键索引
缺点是情况很局限,中间有删除数据,结果集显示不准确
b. 用覆盖索引,排序字段尽可能少,然后inner join表,改造:select * from emp e innerjoin (select id from emp limit 2900000,10) em on e.id=em.id,解析先走索引using index查询10条数据,在走主键索引回查emp表
select* from emp e inner join (select id from emp limit 2900000,10) em on e.id=em.id 运行0.542s左
join关联查询优化
1. 案例: t1和t2表字段一致,t1表1w条数据,t2表100条数据,执行sql:
a. select * from t1 inner join t2 on t1.a=t2.a
b. mysql的执行顺序
i. 执行顺序是先查t2表,后查t1表, 原因是mysql会根据小表驱动大表自动优化
ii. 整个过程t2表扫描100行,遍历出每行字段a,走索引去扫描t1表字段a对应也执行100次,因此一共扫描了200行
c. 优化建议:尽量不要mysql去优化,而是尽量自己把小表提前关联后面的大表, 省去mysql优化器自己判断的时间
2.互联网公司不推荐用太多表关联,最多两三张表,后端报表系统查询除外为了方便,大多数关联是拆成多个sql语句放在java程序里执行运算,因为很多大表关联很难优化
in和exsits优化
优化原理:小表驱动大表,即小的数据集驱动大的数据集
1. 举例: a表数据集合b表数据集进行交集查询
a. 当b表数据集小于a表数据集,in优于exists
select* from A where id in (select id from B)
b. 当a表数据集小于b表数据集,exists优于in
exists一般先查询A后查询B进行对比
select* from A where exists (select 1 from B where B.id=Aid)
count()不同写法查速度对比
1. count(id)扫描主键索引,但会取主键id和data数据,所以速度一般,但mysql5.7之后count(id),也不走主键索引,也会自动走二级索引
2. count(comm),comm字段没加索引速度最慢
3. count(ename),ename字段加普通索引,则为二级索引扫描,会比主键索引快,因为主键索引查到id在加上data数据速度对比二级索引只查询到主键id相比会更慢些
4. count(1)会自动走二级索引,但不同的是不会取索引值,直接返回计数,所以比count(name)加索引更快些
5. count(*)和count(ename)一样,拿二级索引的一个字段加数量
结论: 推荐使用count(1)就可以了,count(id),count(ename),count(*)速度差不多, 一定不要使用count非索引字段计数量
