




引言
在互联网中,攻击者通过传播僵尸程序感染大量主机,这些被感染的主机通过一个信道被攻击者操控,进而形成僵尸网络。在这个过程中,攻击者常常会使用域名将恶意程序连接至C&C服务器,从而达到操控受害者机器的目的。其中攻击者通常采用DGA(域名生成算法),通过输入种子随机生成大量的恶意域名,以此逃避域名黑名单检测的技术手段。
僵尸网络的攻击者一般采用fast-flux和domain-flux两种DNS技术以隐藏其真实的C&C服务器,而僵尸网络通过域名生成算法与C&C服务器建立连接。
例如,如果我们的进程尝试对一个由Cryptolocker创建的DGA生成域建立连接,那么就会导致我们的机器有感染勒索病毒的风险。所以在内网安全体系建设中,及时检测出DGA恶意域名将会在一定程度上降低内网安全风险。
目前主流的恶意域名检测方法分为主动分析和被动分析,前者通过DNS检测、网页内容分析来识别恶意域名,后者一般采用黑白名单规则匹配,或机器学习、图论等方法。而规则匹配无法解决DGA域名快速生成的特性和算法种类的多样性带来的困难,采用机器学习方式学习恶意域名的潜在规律,可以有效的检测恶意域名。
本文首先采用SVM和LightGBM算法实现DGA域名的检测,然后采用深度学习算法LSTM对恶意域名进行检测。
数据探索
数据收集
分别从Alexa-top、360netlab中分别获取各包含50万条域名的数据集用作机器学习模型训练验证使用,其中Alexa-top数据集为正常域名,360netlab数据集为DGA恶意域名。从公司DNS日志中获取当日约1600万域名记录作为检测使用。
数据分析
DGA域名由恶意软件以伪随机字符串的形式生成,字符组成和分布杂乱无章,正常的域名一般具有一定的语义信息,可读性较强。
特征工程
特征分析
DGA域名与正常域名的差异主要有:字符组成方面、字符分布方面。
主要特征
域名长度
恶意域名的长度相对偏长,且同一家族的DGA算法生成的域名长度分布更集中。正常域名长度更趋向于正态分布。
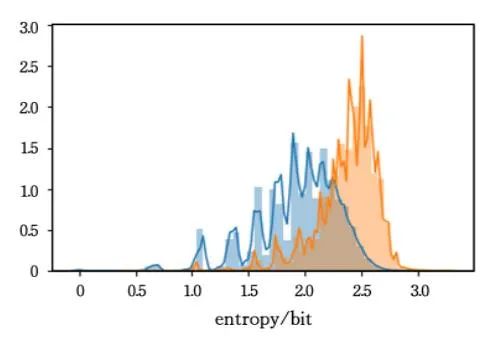
域名的熵值
熵可以反应域名的随机性,域名字符分布越随机无序,其所表达的信息系统越混乱,熵值则越高。DGA算法生成的域名相对随机,其字符分布复杂繁多无规律,相比正常域名,熵值更大。熵公式如下:
其中,表示给定字符出现的概率。
域名组成中元音字母比例
正常域名一般易于朗读和记忆,其包含的元音字母比例占比较高。而英文字母中元音字母所占比例远低于辅音字母,由于恶意域名具有一定的随机性,其元音字母比例较正常域名会低。
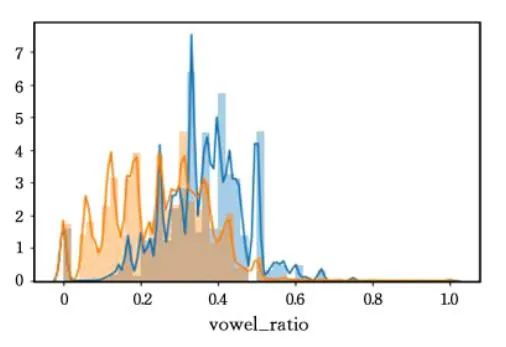
正常域名与DGA域名中元音字母比例分布
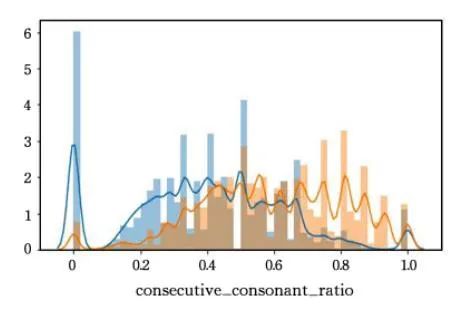
域名组成中连续辅音字母比例
同域名组成中元音字母比例。通常情况下,由于连续的辅音字母会导致域名不易读,正常域名的连续辅音字母比例低于恶意域名。
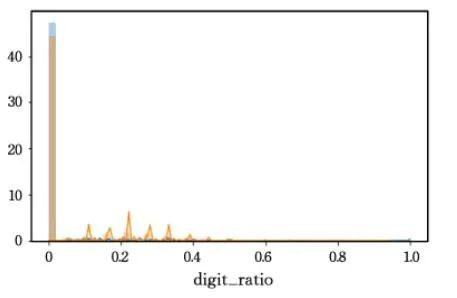
域名组成中的数字比例
正常域名数字比例一般较低。
域名Gibberish
gibberish detection可以用来量化域名能否被真实发音。
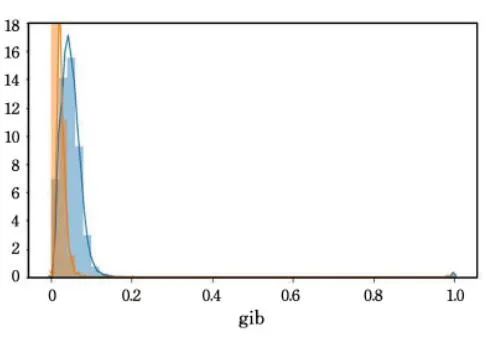
域名n-gram系数
字符串文本的n-gram通常提供重要的特征信息。
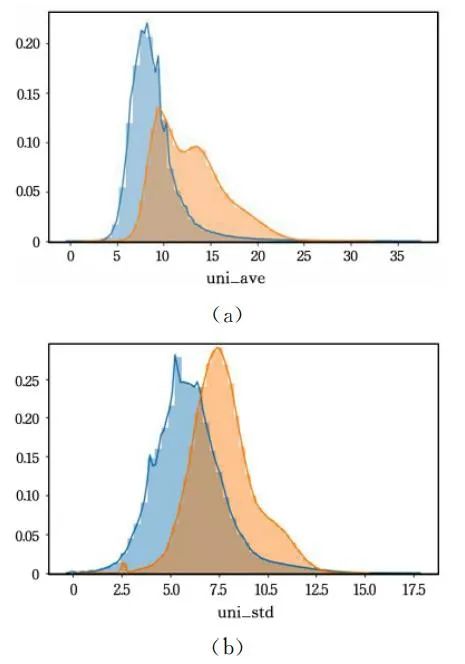
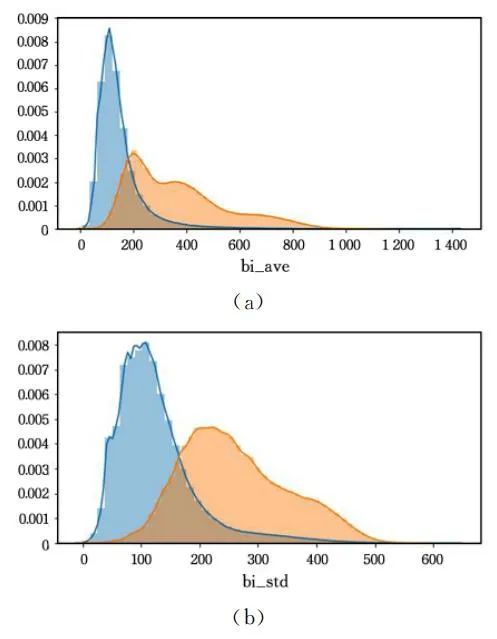
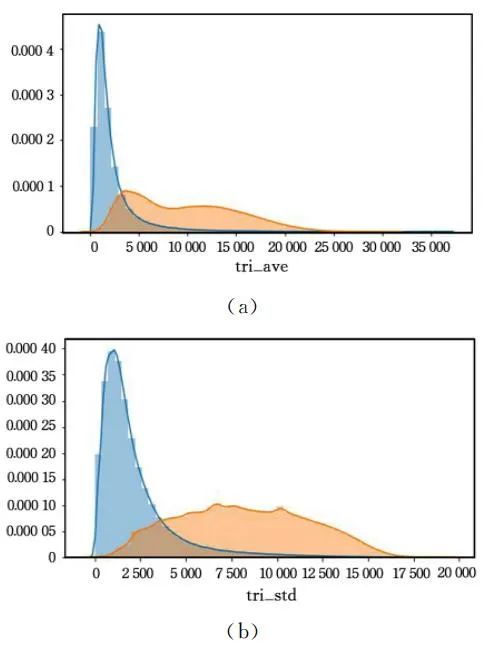
域名HMM转移概率
HMM(隐马尔可夫模型)为时序的概率模型,其描述了在包含隐藏未知参数情况下的一个不可观测的状态随机序列,随机生成的可观测序列的过程。
隐藏的马尔可夫链随机生成的状态的序列,称为状态序列,每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列。
假设为隐藏状态集合,为观测状态集合,即:
其中,为可能的隐藏状态数,为可能的观察状态数。
对于长度为的序列,为其状态序列,为其观察序列,即:
其中,任意一个隐藏状态,任意一个观察状态。
为状态转移概率矩阵:
其中,
为观测概率矩阵:
其中,
为初始状态概率向量:
其中,
是时刻处于状态的概率。
HMM模型可由隐藏状态初始概率分布, 状态转移概率矩阵和观测状态概率矩阵决定。决定状态序列,决定观测序列,即模型可表示为。
隐马尔可夫模型假设隐藏的马尔可夫链在任意时刻的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻无关,即:
域名由字符组合而成,可以看作一个序列,因此可以使用隐马尔可夫模型计算域名出现的概率。首先, 取所有正常域名的样本,计算双字间的转移概率矩阵;然后,当给定一个新的域名 时,根据转移矩阵计算域名的隐含马尔可夫概率。

模型训练
从数据集集中分别各取1万个正常域名和恶意域名样本作为训练集,对样本做特征提取后,采用SVM、LightGBM等算法进行训练。
模型验证
从数据集中取5千个域名样本作为测试集进行五折交叉验证。模型准确率为90%~92%。
LSTM
在各种自然语言处理任务中,循环神经网络(Recursive Neural Networks,RNNs)常常被用来捕捉序列中有意义的短时关系。其中,LSTM是一种常见的循环神经网络,其使用时间反向传播训练,解决了一般RNNs的梯度消失问题。LSTM可以用来创建更大、更深的循环神经网络,以解决复杂的序列问题。由于LSTM的学习方式非常适合处理文本、语音和语言方面的任务,所以对DGA域名检测尝试使用LSTM算法。
首先采用Embedding Layer对域名进行One-Hot编码,并保证统一长度,长度不够的域名采用Padding进行填充。网络层采用是包含128个LSTM存储单元的网络层,用于提取域名序列的高级特征。
核心代码
model = Sequential()
model.add(Embedding(max_features, output_dim=256, input_length=20))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation(’sigmoid’))
model.compile(loss=’binary_crossentropy’, optimizer=’rmsprop’)
X_train=sequence.pad_sequences(X_train, maxlen=75)
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=1)复制
模型验证
从100万样本的数据集中取80%作为训练集,20%作为测试集,采用多层LSTM和Bi-LSTM分别进行训练和测试,在算法进行约15次迭代后,模型的测试集正确率达到最高,为98%~99%。
从公司DNS日志中获取当日约1600万域名数据,采用3层LSTM模型进行检测,去重后人工检查误报率约为1%,并识别出如下所示一个恶意域名。
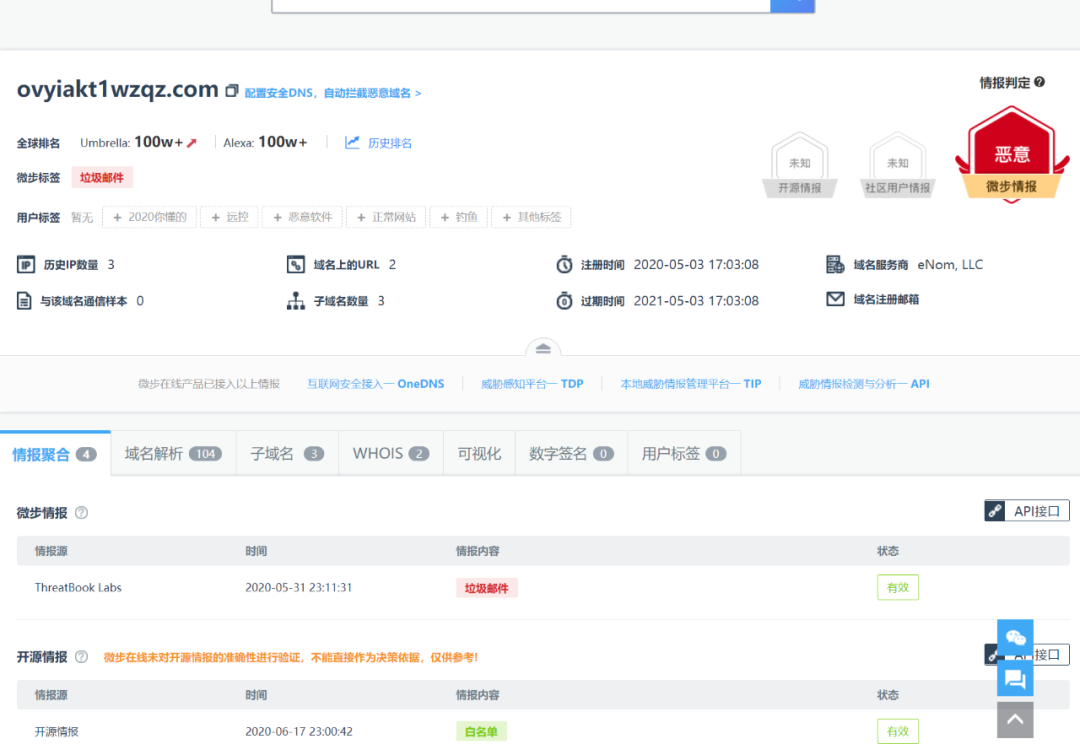
训练数据集样本可以做扩增,如DGArchive上收集了4000多万DGA恶意域名。 可以采用其他深度神经网络模型进行对比。 由于DGA域名在访问行为上也会有一定的相似性,可以增加聚类分析操作,通过域名字符特征与访问行为特征对域名进行聚类,对疑似域名进一步分析。
参考文献
Woodbridge J, Anderson H S, Ahuja A, et al. Predicting domain generation algorithms with long short-term memory networks[J]. arXiv preprint arXiv:1611.00791, 2016. 胡鹏程、刁力力、叶桦、仰燕兰. 基于人工特征与深度特征的DGA域名检测算法[J]. 计算机科学, 2020, v.47(09):317-323. 赵珂雨,陈婉莹.一种基于stacking集成学习的DGA域名检测方法[J].数据通信,2020(06):19-24.
评论

 0 点赞
0 点赞