




Greenplum: A Hybrid Database for Transactional and Analytical.pdf
免费下载

Greenplum: A Hybrid Database for Transactional and Analytical
Workloads
ZHENGHUA LYU, HUAN HUBERT ZHANG, GANG XIONG, HAOZHOU WANG, GANG
GUO, JINBAO CHEN, ASIM PRAVEEN, YU YANG, XIAOMING GAO, ASHWIN AGRAWAL,
ALEXANDRA WANG, WEN LIN, JUNFENG YANG, HAO WU, XIAOLIANG LI, FENG GUO,
JIANG WU, JESSE ZHANG, VENKATESH RAGHAVAN, VMware
Demand for enterprise data warehouse solutions to support real-time Online Transaction Processing (OLTP) queries as well
as long-running Online Analytical Processing (OLAP) workloads is growing. Greenplum database is traditionally known
as an OLAP data warehouse system with limited ability to process OLTP workloads. In this paper, we augment Greenplum
into a hybrid system to serve both OLTP and OLAP workloads. The challenge we address here is to achieve this goal
while maintaining the ACID properties with minimal performance overhead. In this eort, we identify the engineering and
performance bottlenecks such as the under-performing restrictive locking and the two-phase commit protocol. Next we
solve the resource contention issues between transactional and analytical queries. We propose a global deadlock detector to
increase the concurrency of query processing. When transactions that update data are guaranteed to reside on exactly one
segment we introduce one-phase commit to speed up query processing. Our resource group model introduces the capability
to separate OLAP and OLTP workloads into more suitable query processing mode. Our experimental evaluation on the TPC-B
and CH-benCHmark benchmarks demonstrates the eectiveness of our approach in boosting the OLTP performance without
sacricing the OLAP performance.
Additional Key Words and Phrases: Database, Hybrid Transaction and Analytical Process
1 INTRODUCTION
Greenplum is an established large scale data-warehouse system with both enterprise and open-source deployments.
The massively parallel processing (MPP) architecture of Greenplum splits the data into disjoint parts that are stored
across individual worker segments. This is similar to the large scale data-warehouse systems such as Oracle
Exadata [
5
], Teradata [
1
,
7
], and Vertica [
13
], including DWaaS systems such as AWS Redshift [
10
], AnalyticDB
[
27
], and BigQuery [
24
]. These data warehouse systems are able to eciently manage and query petabytes of data
in a distributed fashion. In contrast, distributed relational databases such as CockroachDB [
23
], and Amazon RDS
[
2
] have focused their eorts on providing a scalable solution for storing terabytes of data and fast processing of
transactional queries.
Greenplum users interact with the system through a coordinator node, and the underlying distributed archi-
tecture is transparent to the users. For a given query, the coordinator optimizes it for parallel processing and
dispatches the generated plan to the segments. Each segment executes the plan in parallel, and when needed
shues tuples among segments. This approach achieves signicant speedup for long running analytical queries.
Results are gathered by the coordinator and are then relayed to clients. DML operations can be used to modify data
hosted in the worker segments. Atomicity is ensured via a two-phase commit protocol. Concurrent transactions
are isolated from each other using distributed snapshots. Greenplum supports append-optimized column-oriented
tables with a variety of compression algorithms. These tables are well suited for bulk write and read operations
which are typical in OLAP workloads.
Figure 1 shows a typical data processing workow which involves operational databases managing hot (most
valuable) transactional data for a short period of time. This data is then periodically transformed, using Extract
Author’s address: Zhenghua Lyu, Huan Hubert Zhang, Gang Xiong, Haozhou Wang, Gang Guo, Jinbao Chen, Asim Praveen, Yu Yang,
Xiaoming Gao, Ashwin Agrawal, Alexandra Wang, Wen Lin, Junfeng Yang, Hao Wu, Xiaoliang Li, Feng Guo, Jiang Wu, Jesse Zhang, Venkatesh
Raghavan, VMware.
arXiv:2103.11080v3 [cs.DB] 14 May 2021

2 • Zhenghua Lyu, Huan Hubert Zhang and Gang Xiong, et al.
Fig. 1. A Typical Enterprise Data Processing Workflow
Transform and Load (ETL) tools, and loaded into a data warehouse for further analysis. There is a growing desire
to reduce the complexity of maintaining disparate systems [
19
]. In this vein, users would prefer to have a single
system that can cater to both OLAP and OLTP workloads. In other words, such a system needs to be highly
responsive for point queries as well as scalable for long running analytical queries. This desire is well established
in literature and termed as a hybrid transactional and analytical processing (HTAP) system [11, 19, 20, 25].
To meet the need for Greenplum’s enterprise users we propose augmenting Greenplum into an HTAP system.
In this work, we focus on the following areas, namely, 1) improving the data loading into a parallel system with
ACID guarantees, 2) reducing response time for servicing point queries prevalent in OLTP workloads, and 3)
Resource Group, which is able to isolate the resource among dierent kinds of workloads or user groups.
Greenplum was designed with OLAP queries as the rst class citizen while OLTP workloads were not the
primary focus. The two-phase commit poses a performance penalty for transactions that update only a few
tuples. The heavy locking imposed by the coordinator, intended to prevent distributed deadlocks, proves overly
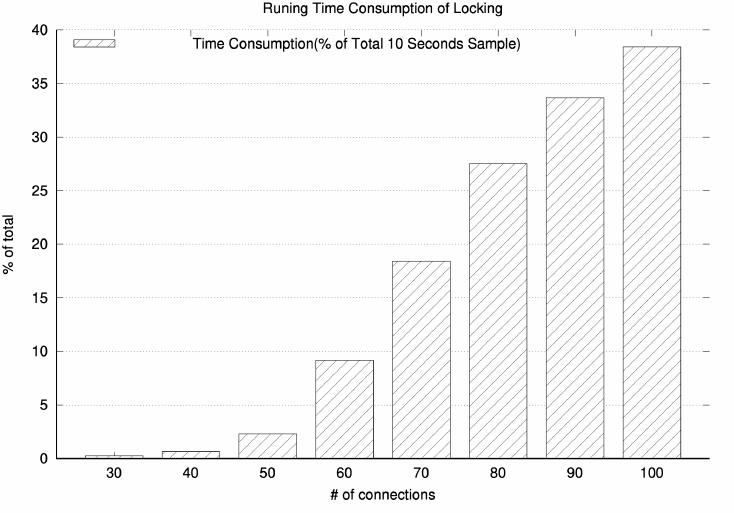
restrictive. This penalty disproportionately aects short running queries. As illustrated in Figure2, the locking
takes more than 25% query running time on a 10-second sample with a small number of connections. When the
amount of concurrences exceeds 100, the locking time becomes unacceptable.
Our key contributions in augmenting Greenplum into an HTAP systems can be summarized as follows:
• We identify challenges in transforming an OLAP database system into an HTAP database system.
•
We propose a global deadlock detector to reduce the locking overhead and increase the OLTP response
time without sacricing performance for OLAP workloads.
•
We speedup transactions that are guaranteed to update only data resident on an exactly one segment by
switching to a one-phase commit protocol.
•
We develop a new resource isolation component to manage OLTP and OLAP workloads, which can avoid
resource conicts in high concurrence scenarios.
•
We conduct a comprehensive performance evaluation on multiple benchmark data sets. The results demon-
strate that the HTAP version of Greenplum performs on-par with traditional OLTP databases while still
oering the capacity of real time computing on highly concurrent and mixed workloads.
Organisation
. In Section 2 we review of related work followed by a detailed description of Greenplum’s MPP
architecture and concepts in Section 3. Section 4 details the design and implementation of the global deadlock
detection. Section 5 demonstrates distributed transaction management in Greenplum and the related optimization
to improve OLTP performance. Section 6 presents our methodology to alleviate the performance degradation
Greenplum: A Hybrid Database for Transactional and Analytical Workloads • 3
Fig. 2. Example of Greenplum locking benchmark
caused by resource competition in a high concurrent, mix workload environment. Lastly, in Section 7 we present
our experimental methodology and analysis.
2 RELATED WORK
Hybrid transactional and analytical processing (HTAP) system.
An HTAP system [
6
,
11
,
26
] brings several
benets compared with an OLAP or OLTP system. First, HTAP can reduce the waiting time of new data analysis
tasks signicantly, as there is no ETL transferring delay. It makes real-time data analysis achievable without
extra components or external systems. Second, HTAP systems can also reduce the overall business cost in terms
of hardware and administration. There are many widely-used commercial OLTP DBMS [
23
,
25
,
26
] that have
been shifting to HTAP-like DBMS. However, the support for OLTP workloads in commercial OLAP DBMS is
still untouched. As the concept of HTAP is becoming popular, more database systems try to support HTAP
capabilities. Özcan et al
. [19]
have dissected HTAP databases into two categories: single systems for OLTP &
OLAP and separate OLTP & OLAP systems. In the rest of this section, we will discuss the dierent evolution
paths of HTAP databases.
From OLTP to HTAP Databases
OLTP databases are designed to support transactional processing with
high concurrency and low latency. Oracle Exadata [
5
] is designed to run OLTP workloads simultaneously with
analytical processing. Exadata introduces a smart scale-out storage, RDMA and inniBand networking, and
NVMe ash to improve the HTAP performance. Recently, it supports features like column-level checksum with
in-memory column cache and smart OLTP caching, which reduce the impact of ash disk failure or replacement.
Amazon Aurora [
25
] is a cloud OLTP database for AWS. It follows the idea that logs are the database, and it
ooads the heavy log processing to the storage layer. To support OLAP workloads, Aurora features parallel
of 27
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。

下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
7
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

文档被以下合辑收录
相关文档
评论