




局部驱动的神经语言模型.pdf
100墨值下载
Topically Driven Neural Language Model
Jey Han Lau
1,2
Timothy Baldwin
2
Trevor Cohn
2
1
IBM Research
2
School of Computing and Information Systems,
The University of Melbourne
jeyhan.lau@gmail.com, tb@ldwin.net, t.cohn@unimelb.edu.au
Abstract
Language models are typically applied at
the sentence level, without access to the
broader document context. We present a
neural language model that incorporates
document context in the form of a topic
model-like architecture, thus providing
a succinct representation of the broader
document context outside of the current
sentence. Experiments over a range of
datasets demonstrate that our model out-
performs a pure sentence-based model in
terms of language model perplexity, and
leads to topics that are potentially more co-
herent than those produced by a standard
LDA topic model. Our model also has the
ability to generate related sentences for a
topic, providing another way to interpret
topics.
1 Introduction
Topic models provide a powerful tool for extract-
ing the macro-level content structure of a docu-
ment collection in the form of the latent topics
(usually in the form of multinomial distributions
over terms), with a plethora of applications in NLP
(Hall et al., 2008; Newman et al., 2010a; Wang
and McCallum, 2006). A myriad of variants of
the classical LDA method (Blei et al., 2003) have
been proposed, including recent work on neural
topic models (Cao et al., 2015; Wan et al., 2012;
Larochelle and Lauly, 2012; Hinton and Salakhut-
dinov, 2009).
Separately, language models have long been a
foundational component of any NLP task involv-
ing generation or textual normalisation of a noisy
input (including speech, OCR and the processing
of social media text). The primary purpose of a
language model is to predict the probability of a
span of text, traditionally at the sentence level, un-
der the assumption that sentences are independent
of one another, although recent work has started
using broader local context such as the preceding
sentences (Wang and Cho, 2016; Ji et al., 2016).
In this paper, we combine the benefits of a
topic model and language model in proposing
a topically-driven language model, whereby we
jointly learn topics and word sequence informa-
tion. This allows us to both sensitise the predic-
tions of the language model to the larger docu-
ment narrative using topics, and to generate topics
which are better sensitised to local context and are
hence more coherent and interpretable.
Our model has two components: a language
model and a topic model. We implement both
components using neural networks, and train them
jointly by treating each component as a sub-task
in a multi-task learning setting. We show that our
model is superior to other language models that
leverage additional context, and that the generated
topics are potentially more coherent than LDA
topics. The architecture of the model provides
an extra dimensionality of topic interpretability,
in supporting the generation of sentences from a
topic (or mix of topics). It is also highly flex-
ible, in its ability to be supervised and incor-
porate side information, which we show to fur-
ther improve language model performance. An
open source implementation of our model is avail-
able at: https://github.com/jhlau/
topically-driven-language-model.
2 Related Work
Griffiths et al. (2004) propose a model that learns
topics and word dependencies using a Bayesian
framework. Word generation is driven by either
LDA or an HMM. For LDA, a word is generated
based on a sampled topic in the document. For the
arXiv:1704.08012v2 [cs.CL] 2 May 2017
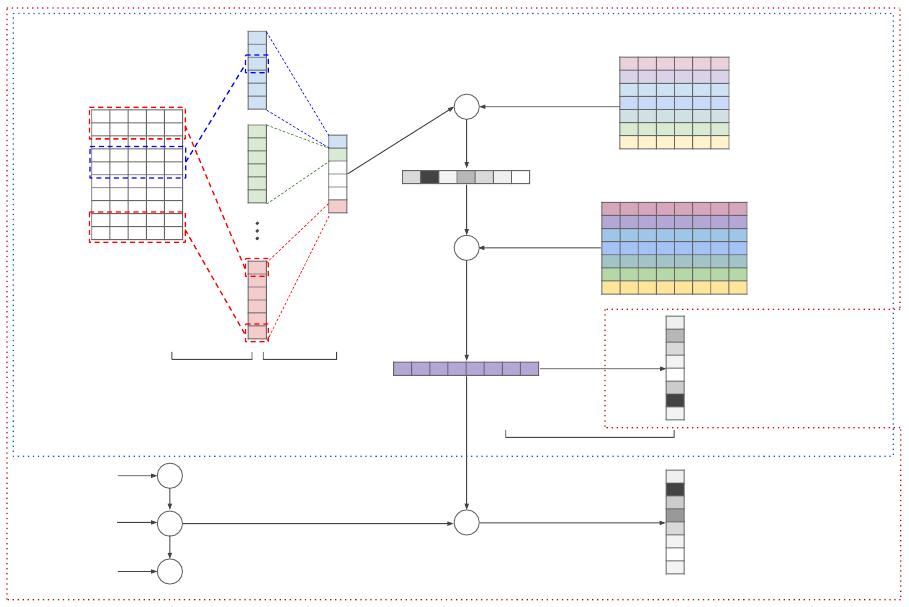
Document context
(n x e)
Topic input A
(k x a)
Topic output B
(k x b)
Softmax
Convolutional Max-over-time
pooling
Fully connected with softmax output
Attention distribution p
Topic model output
Document-topic
representation s
neural
Language model output
Modern
network
approach
network
Language model
Topic model
x
g
lstm
lstm
lstm
Neural
Networks
are
a
computational
approach
which
is
based
on
Document vector d
Figure 1: Architecture of tdlm. Scope of the models are denoted by dotted lines: blue line denotes the
scope of the topic model, red the language model.
HMM, a word is conditioned on previous words.
A key difference over our model is that their lan-
guage model is driven by an HMM, which uses a
fixed window and is therefore unable to track long-
range dependencies.
Cao et al. (2015) relate the topic model view
of documents and words — documents having
a multinomial distribution over topics and top-
ics having a multinomial distributional over words
— from a neural network perspective by embed-
ding these relationships in differentiable functions.
With that, the model lost the stochasticity and
Bayesian inference of LDA but gained non-linear
complex representations. The authors further pro-
pose extensions to the model to do supervised
learning where document labels are given.
Wang and Cho (2016) and Ji et al. (2016) re-
lax the sentence independence assumption in lan-
guage modelling, and use preceeding sentences as
additional context. By treating words in preceed-
ing sentences as a bag of words, Wang and Cho
(2016) use an attentional mechanism to focus on
these words when predicting the next word. The
authors show that the incorporation of additional
context helps language models.
3 Architecture
The architecture of the proposed topically-driven
language model (henceforth “tdlm”) is illustrated
in Figure 1. There are two components in tdlm: a
language model and a topic model. The language
model is designed to capture word relations in sen-
tences, while the topic model learns topical infor-
mation in documents. The topic model works like
an auto-encoder, where it is given the document
words as input and optimised to predict them.
The topic model takes in word embeddings of
a document and generates a document vector us-
ing a convolutional network. Given the document
vector, we associate it with the topics via an atten-
tion scheme to compute a weighted mean of topic
vectors, which is then used to predict a word in the
document.
The language model is a standard LSTM lan-
guage model (Hochreiter and Schmidhuber, 1997;
Mikolov et al., 2010), but it incorporates the
weighted topic vector generated by the topic
model to predict succeeding words.
of 11
100墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论