

1



图解MySQL _ [原理解析] Adaptive Hash Index 是如何建立的 - 爱可生开源社区 - OSCHINA - 中文开源技术交流社区.pdf
5墨值下载
图解MySQL | [原理解析] Adaptive Hash Index 是如何建立的
- 爱可生开源社区 - OSCHINA
转载自公众号:图解MySQL
Adaptive Hash Index(以下简称 AHI)估计是 MySQL 的各大特性中,大家都知道名字但最说不清原理的一
个特性。本期图解我们为大家解析一下 AHI 是如何构建的。
首先我们思考一下 AHI 是为了解决什么问题:
随着 MySQL 单表数据量增大,(尽管 B+ 树算法极好地控制了树的层数)索引 B+ 树的层数会逐渐增多;
随着索引树层数增多,检索某一个数据页需要沿着 B+ 树从上往下逐层定位,时间成本就会上升;
为解决检索成本问题,MySQL 就想到使用某一种缓存结构:根据某个检索条件,直接查询到对应的数据
页,跳过逐层定位的步骤。这种缓存结构就是 AHI。
AHI 在实现上就是一个哈希表:从某个检索条件到某个数据页的哈希表,仿佛并不复杂,但其中的关窍在于哈
希表不能太大(哈希表维护本身就有成本,哈希表太大则成本会高于收益),又不能太小(太小则缓存命中率
太低,没有任何收益)。
这就是 AHI(中文名:自适应哈希索引)中"自适应"的用途:建立一个"不大不小刚刚好"的哈希表。
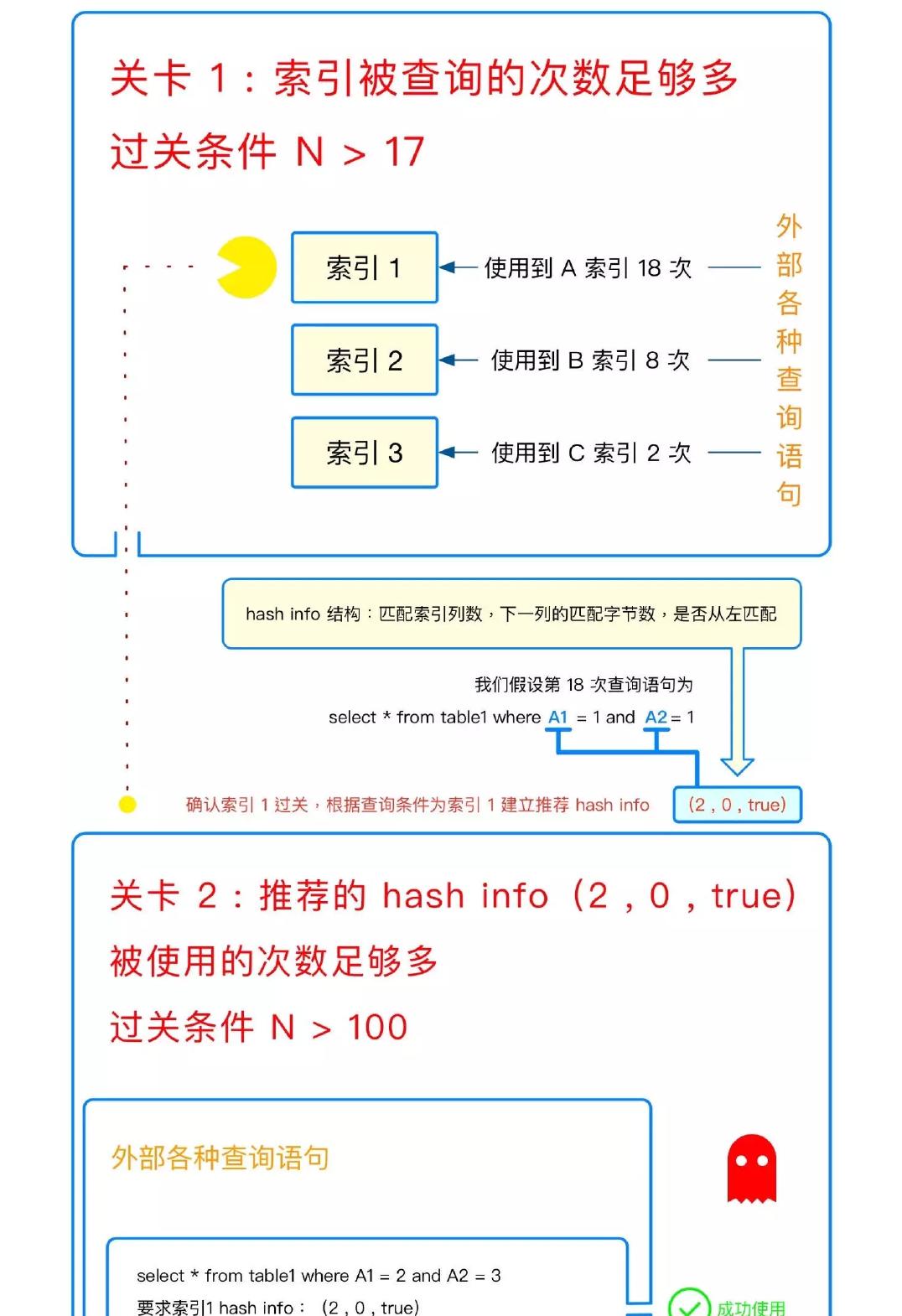
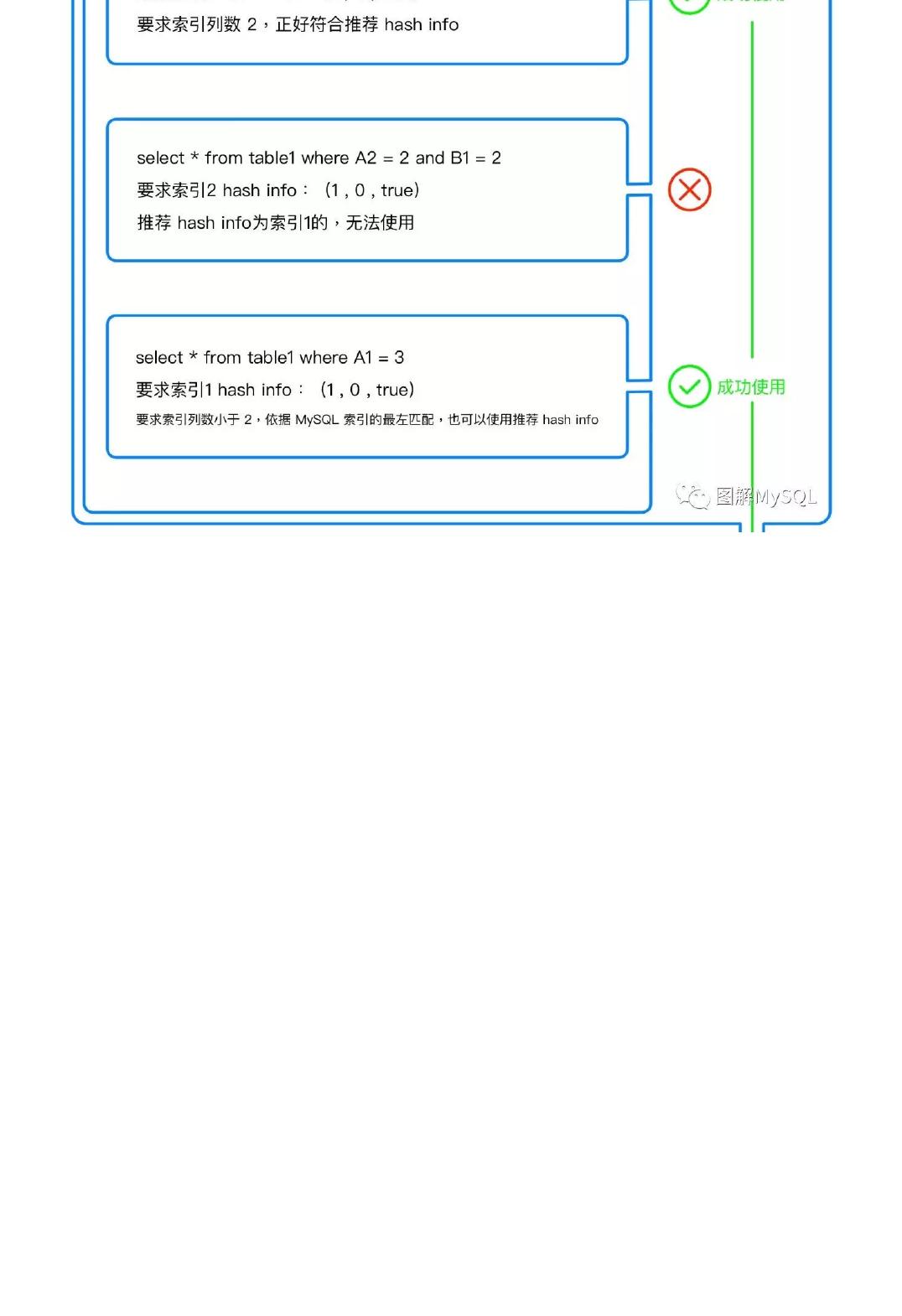
本文主要讨论 MySQL 是如何建立起一个"刚刚好"的 AHI 的,如图 1 所示:需要经历三个关卡,才能为某
个数据页建立 AHI,之后的查询才能使用到该 AHI。
of 8
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
最新上传

相关文档
评论