




The World of Graph Databases from An Industry.pdf
免费下载
The World of Graph Databases from An Industry
Perspective
Yuanyuan Tian
Gray Systems Lab, Microsoft
yuanyuantian@microsoft.com
ABSTRACT
Rapidly growing social networks and other graph data
have created a high demand for graph technologies in
the market. A plethora of graph databases, systems, and
solutions have emerged, as a result. On the other hand,
graph has long been a well studied area in the database
research community. Despite the numerous surveys on
various graph research topics, there is a lack of sur-
vey on graph technologies from an industry perspective.
The purpose of this paper is to provide the research
community with an industrial perspective on the graph
database landscape, so that graph researcher can better
understand the industry trend and the challenges that
the industry is facing, and work on solutions to help
address these problems.
1. INTRODUCTION
Rapidly growing social networks and other graph data
have created a high demand for graph technologies. No
wonder Gartner ranked graph technologies among the
top 10 data and analytics trends in 2021 [40]. According
to Gartner, up to 50% of their client inquiries around the
topic of AI involve a discussion about the use of graph
technology [40], and by 2025, graph technologies will
be used in 80% of data and analytics innovations [12].
Inkwood Research projected that the global market for
graph databases will grow at 21.7% from 2019 to 2027,
and reach $4.6 billion by 2027 [30]. The industry has re-
sponded to the high demand of graph technologies with
a boom of graph companies, systems, and solutions, as
depicted in [45]. The venture capital investment has also
been very active in graphs in the last couple of years.
Not only new startups, like Katana graph ($28.5 mil-
lion in Series A), but even seasoned graph database
companies, like Neo4j and TigerGraph, received a lot
of funding (Neo4j raised $325 million in Series F and
TigerGraph received $105 million in Series C).
On the research side, graph has long been a well stud-
ied area in the database research community. In his
VLDB 2019 keynote [58], Professor
¨
Ozsu provided a
good summary of the various subareas of graph research.
Professor Boncz delivered a keynote in EDBT 2022 about
the state of graph database systems [17], touching on
graph models, graph languages, the common pitfalls in
designing graph database systems, and the blueprint of
a competent graph database system. Professor Fan’s
keynote in VLDB 2022 [23] discussed the challenges
and progress made on processing big graphs, includ-
ing parallel scalability, incremental computation, and
semantic joins between relations and graphs. There have
also been numerous research surveys on topics such as
graph database models [16], graph query languages [15],
graph stream algorithms [37], knowledge graphs [29],
distributed graph pattern matching [18], large-scale graph
processing [57], etc. Back in 2014, Professor Deshpande
blogged his views on graph data management and pointed
out some open problems [13]. The VLDB 2018 best pa-
per [42] and its extension [43] conducted a comprehen-
sive user survey about how graphs are used in prac-
tice, and revealed many interesting insights, including
the ubiquity of large graphs, variety of entities repre-
sented by graphs, the scalability challenges faced by
many graph systems, the importance of visualization
tools, and the continued popularity of RDBMSs in man-
aging and processing graphs. The recent community pub-
lication [44] painted a picture of what the next-decade
big-graph processing systems look like in the aspects
of abstractions, ecosystems, and performance. However,
none of the above work discussed in detail the solution
space or architecture of existing graph databases in the
market. Despite the recent surge in graph technology
innovation in the industry, there is still a lack of survey
on graph technologies from an industry perspective.
The database research community, as a whole, has
been having very strong ties to and impact on the in-
dustry, witnessed by the fleet of database products (e.g.
PostgreSQL and Flink) and startups (e.g. Vertica and
Databricks) originated from research. In the area of graph
databases, the research community has also influenced
heavily on graph benchmarking [10] and graph query
languages [2]. But still, some of the major problems
that the graph database industry cares about are not
well known to the research community. The purpose of
this paper is to provide the research community with
an industrial perspective on the graph database land-
scape, in the hope of helping researchers better under-
stand the current industry status quo and the challenges
they are facing, and ultimately increasing the impact of
the graph database research community.
2. USE CASES AND WORKLOADS
In terms of customer use cases, graph databases have
been used in many vertical industries, including finance,
arXiv:2211.13170v1 [cs.DB] 23 Nov 2022
insurance, healthcare, retail, energy, power, manufactur-
ing, government, marketing, supply chain, transporta-
tion, etc. This diverse and wide applicability of graphs
in many domains is also observed in [42]. Some of the
concrete use cases of graph databases have been pro-
vided in [51, 39, 48, 46]. Perhaps, the most common
example of graph database usage is fraud detection.
For example, [47] demonstrated a detailed example sce-
nario of traversing through a graph containing insurance
claims information and patients medical records to de-
tect fraudulent claims.
Similar to the different types of workloads in rela-
tional databases, there are also two different types of
graph database workloads. The first type focuses on
low-latency graph traversal and pattern matching. They
are often called graph queries. These queries only touch
small local regions of a graph, for example, finding 2-
hop neighbors of a vertex, or the shortest path between
two vertices. Due to the low-latency requirement and
the interactive nature of the graph queries, people also
call them graph OLTP. Graph OLTP is often used in
exploratory analysis and case studies. The second type
of graph workload is graph algorithms, which usually
involve iterative, long running processing on the entire
graph. Good examples are Pagerank and community de-
tection algorithms. Graph algorithms are often used for
BI-ish applications. Because of this reason, people also
call them graph OLAP. Recently, a new trend emerges
that combines graph and machine learning together,
called graph ML. For example, graph embedding or ver-
tex embedding are used to transform graph structures
into vector space which are then included as features
for ML model training. Graph neural network (GNN) is
another example of graph ML. Quite often graph ML is
lumped together with the graph OLAP workload.
3. GRAPH MODELS
Patient 1
Disease 1
Disease 2
isa
diagnosedWith
64572345
hasID
Diabetes
hasName
64572326
hasID
Type 2
Diabetes
hasName
198076
hasID
Alice Brown
hasName
Diagnosis 1
03/24/2020
happensOn
hasDiagnosis
(a) RDF Model
Properties:
ID = 198076
name = “Alice Brown”
Label: diagnosedWith
Properties:
time = “03/24/2020”
Properties:
ID = 64572326
name = “Type 2 diabetes”
Properties:
ID = 64572345
name = “Diabetes”
Label: isa
Label: disease
Label: disease
Label: patient
(b) Property Graph Model
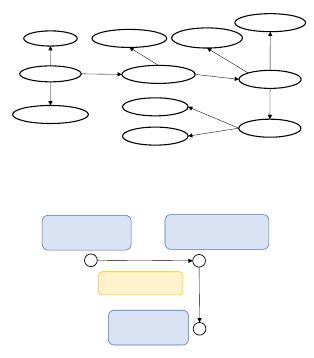
Figure 1: RDF and property graph models
Whenever talking about a graph database, we need
to first talk about the graph model(s) that it supports.
The two prominent graph models supported by most
commercial graph databases are the RDF model and
the property graph model.
RDF Model. RDF is among the suite of W3C stan-
dards to support Linked Data and Knowledge Graphs [52].
An RDF graph is a directed edge-labeled graph, rep-
resented by the subject–predicate–object triples. Fig-
ure 1(a) shows an example graph represented in the
RDF model. This graph captures the following infor-
mation: A patient, named Alice Brown, with patient ID
19806, is diagnosed with Type 2 Diabetes which has
disease ID 64572326 on March 24, 2020; and Type 2
Diabetes is sub-type of Diabetes which has disease ID
6472345. For example, in the (Patient 1) −[hasName]→
(Alice Brown) triple, Patient 1 is the subject, hasName
is the predicate, and Alice Brown is the object. The
RDF model is often used in knowledge representation
and inference as well as sematic web applications. For
example, DBPedia [21] and YAGO [56] both utilize RDF
to represent their knowledge graphs and support queries
on the knowledge bases using SPARQL [53].
Property Graph Mo del. In comparison, a property
graph is a direct graph where each vertex and edge
can have arbitrary number of properties. Vertices/edges
can also be tagged with labels to distinguish the dif-
ferent types of objects/relationships in the graph. Fig-
ure 1(b) shows how the same information captured in
the RDF graph in Figure 1(a) is represented in the prop-
erty graph model. Here, instead of representing the ID
and the name of a patient or disease as separate nodes,
the property graph model can fold them in as the prop-
erties of the patient and the disease nodes. Similarly,
the diagnosis time can be represented as a property of
the diagnosedWith edge, eliminating the need to cre-
ate a separate diagnosis node and its connecting edges
to the patient and disease nodes. In general, the prop-
erty graph model can capture the same information with
fewer nodes and edges than the RDF model, as illus-
trated by this example. This is because a piece of in-
formation can only be represented either as a node or
an edge in the RDF model, whereas the property graph
model can also define it as an attribute of an existing
node or edge, thus leading to fewer number of nodes
and edges in the graph. The property graph model is
often used for applications that require graph traversal,
pattern matching, path and graph analysis.
Today, although both models are supported in the
graph database industry, as we will show in Section 5,
the property graph model has overwhelming endorse-
ment, despite the fact that RDF is a much older model.
All the major offerings we surveyed in the paper sup-
port the property graph model, and two of them also
support the RDF model. In [27], Hartig proposed a
formal transformations between the RDF and property
graph models, in the hope to reconcile both models.
4. GRAPH QUERY LANGUAGES
On the graph OLTP side, for RDF graphs, there is
the standard SPARQL query language [53]. For prop-
erty graphs, there are many languages being used and
proposed, but no clear winner. One of the top con-
tenders is Tinkerpop Gremlin [1] which is supported
of 8
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论