

1



PostgreSQL PG 创建 INDEX 和并行原理.pdf
免费下载
PostgreSQL PG 创建 INDEX 和并行原理
原创 carol11 AustinDatabases
收录于话题
#postgresql 34
#DATABASE 34
It's a long long story, 从 PG 8.3 引入了Heap-Only-Tuple, 主要的作用在用于减少更新所需的I/O数量,基于
postgreql 的原理行的更新等于插入新的tuple,基于多版本控制MVCC, Postgres中的更新包括查找要更新的
行,并将该行的新版本插入数据库,引入的问题就是显而易见的,索引,这就需要更多的I/O,数据要重新插入
到表上的每个索引中。在插入的过程中需要先读取每个相关的索引,新版本行的物理位置与旧版本的物理位置
不同。那一个表中有的索引越多,更改的数据量越大,牵扯的索引的消耗就越大。
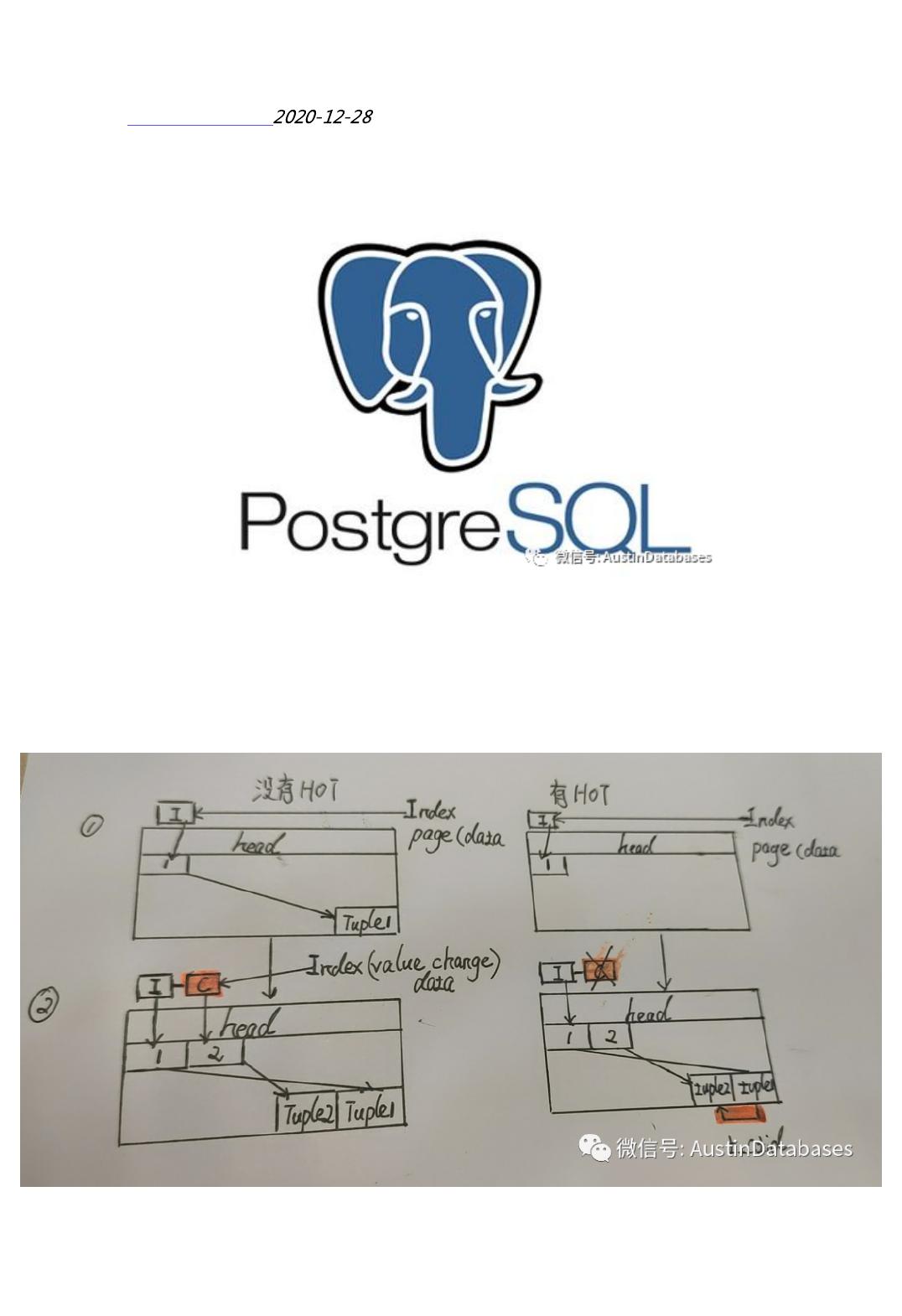
从上图可以看,如果没有HOT ,则索引页面在更新后,需要另一个指针指向修改后的INDEX 数据, 如果有了
HOT 则不需要通过另外的指针 C 去指向修改后的索引,仅仅通过原有的指针,在原有的索引tuple1 上通过
t_cid来指向新的index的数据即可。在数据结构中的样子参看下图

HOT的效率虽然高,但需要达到某些需求,才可以实现,从上图看
1 数据必须(tuple)必须在一个页面
2 更新的数据中不能包含 INDEX 本身的数据
下面我们开始做相关的实验,看看HOT 在实践中是怎样的
create table test (id int, name varchar(200), age float, datetime timestamp);
insert into test select generate_series(1,10), random()*100, random()*1, now();
create index idx_test_name on test (name);
create index idx_test_age on test (age);
create index idx_test_datetime on test (datetime);
通过 pageinspect 来对当前的index 页面进行一个细节观测
of 8
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论