




阿里云_VLDB-2024-Sub-trajectory clustering with deep reinforcement learning.pdf
免费下载

The VLDB Journal
https://doi.org/10.1007/s00778-023-00833-w
REGULAR PAPER
Sub-trajectory clustering with deep reinforcement learning
Anqi Liang
1
· Bin Y ao
1,3
· Bo Wang
1
· Yinpei Liu
2
· Zhida Chen
2
· Jiong X ie
2
· Feifei Li
2
Received: 8 May 2023 / Revised: 4 December 2023 / Accepted: 10 December 2023
© The Author(s), under exclusive licence to Springer-Verlag GmbH Germany, part of Springer Nature 2024
Abstract
Sub-trajectory clustering is a fundamental problem in many trajectory applications. Existing approaches usually divide the
clustering procedure into two phases: segmenting trajectories into sub-trajectories and then clustering these sub-trajectories.
However, researchers need to develop complex human-crafted segmentation rules for s pecific applications, making the clus-
tering results sensitive to the segmentation rules and lacking in generality. To solve this problem, we propose a novel algorithm
using the clustering results to guide the segmentation, which is based on reinforcement learning (RL). The novelty is that the
segmentation and clustering components cooperate closely and improve each other continuously to yield better clustering
results. To devise our RL-based algorithm, we model the procedure of trajectory segmentation as a Markov decision process
(MDP). We apply Deep-Q-Network (DQN) learning to train an RL model for the segmentation and achieve excellent cluster-
ing results. Experimental results on real datasets demonstrate the superior performance of the proposed RL-based approach
over s tate-of-the-art methods.
Keywords Sub-trajectory clustering · Spatio-temporal similarity · Reinforcement learning · Deep learning
1 Introduction
With the proliferation ofGPS-equipped devices and location-
based services, a vast amount of trajectory data is generated
at an unprecedented rate. Trajectory data capture the move-
ments of moving objects and are highly valuable for various
B
Bin Yao
yaobin@cs.sjtu.edu.cn
Anqi Liang
lianganqi@sjtu.edu.cn
Bo Wang
Wangbo324@sjtu.edu.cn
Yinpei Liu
yinpei.lyp@alibaba-inc.com
Zhida Chen
zhida.chen@alibaba-inc.com
Jiong Xie
xiejiong.xj@alibaba-inc.com
Feifei Li
lifeifei@alibaba-inc.com
1
Shanghai Jiao Tong University, Shanghai, China
2
Alibaba Group, Hangzhou, China
3
Hangzhou Institute of Advanced Technology, Hangzhou,
China
applications such as site selection, green transport, tourism
planning, and traffic monitoring [19, 29, 35, 36]. In recent
years, sub-trajectory clustering has attracted much atten-
tion. The sub-trajectory clustering task is to segment the
trajectories into sub-trajectories based on certain principles
and then cluster them w.r.t a given distance metric. Cluster-
ing the whole trajectories poses a challenge in discovering
local similarities among trajectories since they vary in length
and time range, leading to the loss of valuable information.
As illustrated in Fig. 1, the four trajectories share similar
sub-trajectories in the box, indicating the existence of a
common pattern among them. However, clustering these
trajectories as a whole will make the pattern unobservable
because they are dissimilar and will be put into different clus-
ters. Sub-trajectory clustering is helpful in many real-world
applications, particularly for analyzing the correlations or
common patterns among portions of different trajectories in
regions of interest. For example, in hurricane forecasting,
given the historical hurricane trajectories, researchers focus
on the common patterns of sub-trajectories near the coastline
because they can predict the locations of hurricane landfall
by analyzing the patterns. Therefore, discovering the com-
mon patterns of sub-trajectories can improve the accuracy
of hurricane forecasting and reduce damages caused by the
hurricane.
123
Content courtesy of Springer Nature, terms of use apply. Rights reserved.
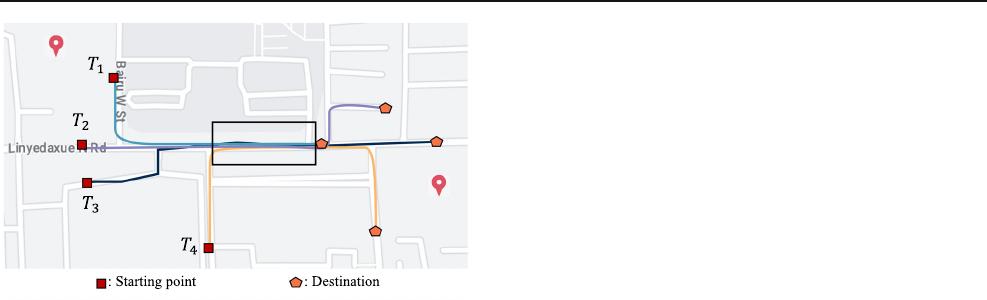
A. Liang et al.
Fig. 1 Four dissimilar trajectories with a similar portion (the part in the
black box)
Existing solutions to the sub-trajectory clustering problem
follow the first-segment-then-cluster paradigm. The effec-
tiveness of the clustering result heavily depends on the
segmentation step, which is a crucial diff erence from the
trajectory clustering problem. Existing solutions can be clas-
sified into two categories. The first one regards segmentation
and clustering as two independent procedures. It segments
the t rajectories into sub-trajectories according to spatial fea-
tures and then clusters these sub-trajectories. For instance,
Lee et al. [18] proposed TRACLUS, which segments trajec-
tories into line segments based on the minimum description
length principle and then clusters line segments by applying
DBSCAN. The second one segments trajectories by taking
the clustering quality into account. For example, Pelekis et
al. [25] segment trajectories based on the local density cri-
terion and then conduct clustering according to the density.
These methods usually rely on complicated hand-crafted seg-
mentation rules tailored to specific applications, making the
clustering result sensitive to these rules and limiting t heir
generality.
To address these issues, we consider utilizing the clus-
tering quality to guide the segmentation in a data-driven
manner instead of using hand-crafted segmentation rules.
A straightforward approach is enumerating all segmentation
schemes and choosing the one with the best clustering qual-
ity. However, this method is computationally expensive and
is thus impractical for real-world applications. Therefore,
we propose an efficient and effective reinforcement learn-
ing (RL)-based framework that leverages clustering quality
to guide segmentation. It allows segmentation and clustering
components to cooperate closely, mutually enhancing each
other and achieving superior clustering results.
Specifically, we treat the segmentation procedure as a
sequential decision process, i.e., it sequentially scans the
trajectory points and decides whether to segment at that
point, which can be modeled as a Markov decision process
(MDP) [26]. The crucial challenge of the MDP formulation
is to define the state and reward, which significantly affect
the performance of the learned model, i.e., the RL agent.
Regarding the design of the state, the intuitive idea is to
include more features to reflect the environment. However,
experimental results indicate that such an approach may lead
to much longer training time without noticeable improve-
ments i n the model’s performance. To solve this problem, we
propose a representative set of features that can effectively
summarize the sub-trajectory clustering characteristics while
maintaining acceptable training time. Designing an appropri-
ate reward is vital to the training process as it encourages the
RL agent to choose good actions to boost performance. We
define the reward based on the evaluation metrics of clus-
tering quality, which allows us to leverage the clustering
quality to guide the trajectory segmentation, thus achiev-
ing the data-driven trajectory segmentation. We employ the
Deep-Q-Network (DQN) method [24] to learn the policy for
the MDP in our trajectory segmentation problem. Based on
the learned policy, we propose a RL-based Sub-Trajectory
Clustering algorithm called RLSTC. Our algorithm is data-
driven and can adapt to different dynamics of the underlying
trajectories. Moreover, it is a general solution that can be
applied to various trajectory similarity measurements and
application scenarios.
To further improve efficiency, we propose several opti-
mizations to decrease the cost of trajectory distance computa-
tion. First, we implement a preprocessing step that simplifies
trajectories by reserving only the critical points. Second, we
apply an approximate method to compute trajectory similar-
ity in linear time. Finally, we utilize an incremental similarity
computation strategy to avoid recomputing the distance from
scratch.
In summary, our main contributions are as follows:
• We propose a novel RL-based framework for the sub-
trajectory clustering problem, which is the first RL-based
solution to the best of our knowledge.
• We creatively model the procedure of trajectory seg-
mentation as an MDP, especially defining the state and
reward of MDP by considering the distinct features
of the sub-trajectory clustering. This method achieves
data-driven trajectory segmentation without relying on
complex hand-crafted rules.
• We have developed several optimizations to enhance the
efficiency of our solution.
• We conduct extensive experiments on various real-world
trajectory datasets. The experimental results demonstrate
that our RL-based algorithm outperforms state-of-the-art
methods in terms of both effectiveness and efficiency.
The remainder of the paper is as follows: In Sect. 2,we
present preliminaries and our problem statement. Section 3
discusses the preprocessing algorithm. In Sect. 4, we detail
123
Content courtesy of Springer Nature, terms of use apply. Rights reserved.
of 19
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论