




阿里云_VLDB-2024-Towards Millions of Database Transmission Services in the Cloud.pdf
免费下载

Towards Millions of Database Transmission Services in the Cloud
[Industrial Track]
Hua Fan*, Dachao Fu*, Xu Wang, Jiachi Zhang, Chaoji Zuo, Zhengyi Wu, Miao Zhang,
Kang Yuan, Xizi Ni, Guocheng Huo, Wenchao Zhou, Feifei Li, Jingren Zhou
Alibaba Group
Hangzhou, China
{guanming.fh,qianzhen.fdc,wx105683,zhangjiachi.zjc,zuochaoji.zcj,wuzhengyi.wzy,yanmen.zm}@alibaba-inc.com
{yuankang.yk,xizi.nxz,guocheng.hgc,zwc231487,lifeifei,jingren.zhou}@alibaba-inc.com
Abstract
Alibaba relies on its robust database infrastructure to facilitate real-
time data access and ensure business continuity despite regional
disruptions. To address these operational imperatives, Alibaba de-
veloped the Data Transmission Service (DTS), which has become
critical for internal applications and public cloud services alike.
This paper presents a comprehensive study of the architectural
innovations, resource scheduling mechanisms, and performance
optimization strategies that have been implemented within DTS to
tackle the signicant challenges of cross-network, heterogeneous
data transmission in a cost-eective manner. We explore the novel
Any-to-Any (A2A) architecture, which simplies the complexity
of data paths between diverse databases and mitigates network
connectivity issues, thereby signicantly reducing development
overhead. Additionally, we examine a dynamic network bandwidth
scheduling algorithm that eectively maintains Service-Level Ob-
jectives (SLOs), complemented by a serverless mechanism that
ensures ecient resource utilization. Furthermore, DTS utilizes
advanced strategies such as transaction dependency tracking, hot
data consolidation, and batching to enhance synchronization per-
formance and eciency. DTS has distilled the lessons learned from
years of serving our customer base and currently supports nearly
1 million public cloud instances annually. Our evaluation results
show that DTS can eectively and eciently handle real-time data
transmission in both experimental and production environments.
1 Introduction
Alibaba operates a vast digital commerce service, anchored by its
resilient database services, which store essential business data. This
requires two key functions: First is real-time access to database
information, critical for applications like advertising and search,
prompting the need for services that can parse real-time database
logs to satisfy the many business units demanding instant data
from primary databases [
22
,
28
,
41
]. Secondly, business continuity
against regional disruptions — such as power outages or natural dis-
asters — is pivotal, demanding real-time database synchronization
to secondary regions for swift operation transfer [
32
]. These neces-
sities drove Alibaba to create its own Data Transmission Service
(DTS) [
20
] in 2011, focusing on synchronization between databases
(e.g., MySQL to MySQL).
*Both authors contributed equally to this research.
As Alibaba Cloud Computing expanded, it began oering a vari-
ety of database services to the public cloud, triggering a need for
migrating more than 24 dierent types of databases from local data
centers or other cloud providers. This diversity led to a surplus of
potential data transmission pathways, heavily complicating the pro-
cess and increasing the development workload. Network connectiv-
ity issues further exacerbated this complexity, potentially requiring
specialized programs to access private intranets, culminating in a
signicant challenge: developing numerous cross-network,
heterogeneous data transmission services cost-eectively.
Managing a high volume of DTS instances poses the challenge
of resource scheduling. This complexity arises from the need to
balance and allocate network and computational resources eec-
tively such as bandwidth, CPU, and memory among a multitude
of services. Insucient resource allocation can lead to violations
of Service Level Objectives (SLOs), adversely aecting customer
business operations. As the demand for real-time access to data
grows, ensuring ecient resource scheduling becomes critical for
maintaining service quality and reliability in DTS operations.
The third challenge that emerges is related to synchroniza-
tion performance issues. This concerns the need for near-zero
delay in real-time data synchronization, which is highly sought
after by our customers. However, synchronization latency can be
signicantly aected by the performance of the target database,
particularly under high-frequency updates. Factors contributing
to this delay include lower concurrency in database replication
compared to the source [
28
], performance discrepancies in updates
between heterogeneous databases [
18
], and ineciencies in writing
to the target database.
To conquer these challenges while meeting customer and busi-
ness needs, DTS was architected with several key design consid-
erations. In this paper, we outline the architecture aimed at reduc-
ing development complexity, resource scheduling mechanisms for
enhancing user experience and eciency, and optimizations for
performance of update operations. The specics are as follows.
•
DTS employs an Any-to-Any (A2A) architecture, which is a
strategic design choice that allows for universal compatibility
and exibility in data transmission. This A2A approach enables
DTS to interconnect any source database with any target data-
base, transforming and translating data formats as needed. By
adopting this architecture, DTS can reduce the number of poten-
tial data transmission pathways from a factorial of M source-to-N
target links to a M+N conguration. On each link, DTS encap-
sulates network connectivity issues into predened scenarios
within the DTS framework. Users can thus select their scenario
without the need for additional network programming to achieve
connectivity.
•
Using the optimization-based scheduling algorithm for network
ow, DTS can intelligently manage and allocate bandwidth across
dierent data transmission links. This algorithm takes into ac-
count the current network conditions, transmission priorities,
and the overall demand on the system to dynamically adjust the
ow of data. By doing so, it minimizes the risk of SLO viola-
tions and ensures fair distribution of network resources among
all active transmissions. Moreover, DTS serverless dynamically
alters resource allocation for each service according to the cur-
rent workload and performance metrics. This adaptive resource
management ensures that computational resources are allocated
eciently in real-time.
•
DTS employs a series of strategies that collectively enhance
performance and eciency. These strategies include the opti-
mization of transaction execution by tracking dependencies to
maximize concurrency, the consolidation of frequently accessed
data (hot data) to reduce the volume of writes, and the use of
batching techniques to enhance the transfer and processing of
data. These enhancements are particularly crucial in real-time
synchronization scenarios, where delays can have signicant
downstream impacts on business operations.
In summary, this paper makes the following contributions:
(1)
The adoption of an A2A architecture, when paired with prede-
ned network connectivity scenarios, eectively simplies the
development complexity associated with DTS.
(2)
Our demonstration highlighted the eectiveness of the DTS’s
optimization-based scheduling algorithm in managing network
ow, alongside its dynamic resource allocation mechanism that
enables real-time adaptation to uctuating workloads.
(3)
DTS enhances performance and eciency through an approach
that encompasses tracking transaction dependencies, consoli-
dating hot data, and implementing batching techniques, while
upholding user-dened consistency standards.
(4)
We showcase the real-world deployment of DTS, which sup-
ports nearly one million public cloud instances annually, thereby
arming its practicality and scalability in an industrial setting.
The remainder of this paper is structured as follows: Section 2
oers an overview of data transmission, detailing the complexi-
ties and challenges involved in managing a vast number of DTS
instances. In Section 3, we delve into the architectural design, in-
troducing the A2A architecture, and the mechanisms it utilizes for
establishing network connectivity. Section 4 explores the resource
scheduling solutions including the bandwidth allocation algorithm
and the DTS serverless mechanism, while Section 5 delves into the
optimization strategies for ecient data writing to target databases.
Lastly, Section 6 evaluates DTS’s performance improvements for
individual instances and the collective benets within a datacenter.
2 Background and Motivation
In this section, we introduce background knowledge of data trans-
mission (Section 2.1) and three major challenges as motivations of
this paper (Section 2.2).
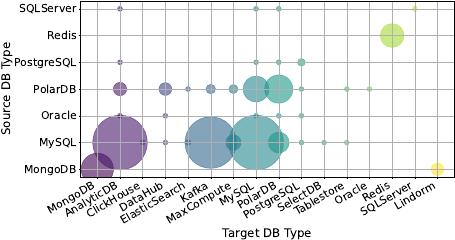
Figure 1: Diversity of Databases in DTS Instances within a
Region (Circle Sizes Represent Trac Volume)
2.1 Data Transmission
In the domain of database research, a typical data transmission
scenario entails data replication of two dierent databases, namely
source database and target database. Based on the transmission
medium, replication can be categorized into two types: physical
replication, which involves the direct duplication of raw database
les, and logical replication, which replays Data Manipulation Lan-
guage (DML) statements on the target database. Physical replication
can be readily implemented utilizing inherent features provided by
database management systems, such as MySQL’s Multi-threaded
Replication mechanism [
12
]. However, its application is constrained
due to its requirement for identical source and target database types.
Therefore, data transmission services, such as AWS Data Migration
Service (DMS) [
2
], Oracle’s GoldenGate [
13
], and Fivetran [
8
], fa-
vor logical replication because they accommodate heterogeneous
database types.
The heterogeneity of databases also compels data transmission
providers to implement logical replication outside of database en-
gines. Taking AWS DMS as an example, a transmission task consists
of a source endpoint that fetches data from the source database
and a target endpoint that is responsible for writing to the target
database. Data transmission tasks are typically categorized, based
on the fetched data, into full transmission tasks that transfer entire
tables at once and Changed Data Capture (CDC) transmission tasks
that replay DML statements from write-ahead logs (WALs) in real-
time [
30
]. Despite being a mature eld, the growing scale of data
transmission continues to bring forth novel challenges.
2.2 Challenges
In this section, we introduce three major challenges that emerge as a
result of the escalating scale of data transmission. These challenges
are examined along three dimensions of scale: database and network
diversity, task quantity, and transmission velocity.
2.2.1 Databases and Network Diversity. First, the source and target
databases may encompass a wide variety of database types. As
reported by DB-Engines [
6
], as of March 2024, there have been hun-
dreds of cataloged database systems. Furthermore, Alibaba Cloud
oers a suite of standard cloud services encompassing 24 distinct
database types [
1
]. Various databases dier signicantly in terms of
their connection protocols, syntax conventions, and underlying data
models, such as relational, key-value (KV), or document-oriented.
Therefore, a universal data transmission tool does not exist.
2
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论