




VLDB2024_GaussDB: A Cloud-Native Multi-Master Database with Compute-Memory-Storage Disaggregation_华为.pdf
免费下载

GaussDB: A Cloud-Native Multi-Primary Database with
Compute-Memor y-Storage Disaggregation
Guoliang Li
Tsinghua University
liguoliang@tsinghua.edu.cn
Wengang Tian
Huawei Company
tianwengang@huawei.com
Jinyu Zhang
Huawei Company
zhangjinyu.zhang@huawei.com
Ronen Grosman
Huawei Company
ronen.grosman@huawei.com
Zongchao Liu
Huawei Company
liuzongchao@huawei.com
Sihao Li
Huawei Company
sean.lisihao@huawei.com
ABSTRACT
Cloud-native databases have been widely deployed due to high
elasticity, high availability and low cost. However, most existing
cloud-native databases do not support multiple writers and thus
have limitations on write throughput and scalability. To alleviate
this limitation, there is a need for multi-primary databases which
provide high write throughput and high scalability.
In this paper, we present a cloud-native multi-primary database,
GaussDB
, which adopts a three layer (compute-memory-storage)
disaggregation framework, where the compute layer is in charge of
transaction processing, the memory layer is responsible for global
buer management and global lock management, and the storage
layer is used for page and log persistence. To provide multi-primary
capabilities,
GaussDB
logically partitions the pages to dierent com-
pute nodes and then assigns the ownership of each page to a com-
pute node. For each transaction posed to a compute node, if the
compute node owns all relevant pages of this query, the compute
node can process the query locally; otherwise,
GaussDB
transfers
the ownership of relevant pages to this node. To capture data anity
and reduce page transmission costs,
GaussDB
designs a novel page
placement and query routing method. To improve recovery perfor-
mance,
GaussDB
employs a two-tier (memory-storage) checkpoint
recovery method which uses memory checkpoints combined with
on-demand page recovery to signicantly improve recovery per-
formance. We have implemented and deployed
GaussDB
internally
at Huawei and with customers, and the results show that
GaussDB
achieves higher throughput, lower latency, and faster recovery than
state-of-the-art baselines.
PVLDB Reference Format:
Guoliang Li, Wengang Tian, Jinyu Zhang, Ronen Grosman, Zongchao Liu,
and Sihao Li. GaussDB: A Cloud-Native Multi-Primary Database with
Compute-Memory-Storage Disaggregation. PVLDB, 17(12): 3786 - 3798,
2024.
doi:10.14778/3685800.3685806
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 17, No. 12 ISSN 2150-8097.
doi:10.14778/3685800.3685806
1 INTRODUCTION
Cloud-native databases have attracted signicant attention from
both industry and academia due to their high elasticity, high avail-
ability, and low cost. Many cloud databases have been launched,
e.g. Amazon Aurora [
29
], Google AlloyDB [
12
], Microsoft Azure
SQL Database [
2
,
22
], Huawei Taurus [
9
], and Alibaba PolarDB [
5
].
Many customers have moved their on-premise databases to cloud
databases [
1
–
5
,
8
,
9
,
12
,
14
,
14
,
15
,
17
–
21
,
23
,
23
,
26
,
27
,
29
,
32
,
34
–
36, 36–38].
Most existing cloud-native databases adopt a primary-standby
architecture where only the primary node supports writes and all
other standby nodes can only perform reads (i.e., single writer,
multiple readers). Obviously, this primary-standby architecture
has limitations on write throughput, scale-out and scale-in, and
continuous availability. Thus, there is a need for multi-primary
(a.k.a. multi-writer) databases, where each node can write and read,
thus providing high write scalability and enhanced availability.
Although Aurora [
30
], Taurus [
10
] and PolarDB[
31
] oer the multi-
primary capabilities, they have some limitations. Aurora [
30
] uses
the logs and optimistic concurrency control to detect write conicts,
and thus has high abort rates and lower performance. Taurus [
10
]
adopts pessimistic concurrency control for cache coherence, but it
suers from high concurrency control overhead. PolarDB [
31
] uses
a stateful memory layer for transaction/buer/lock fusion where
each compute node interacts with the memory layer for transaction
processing, but it is inecient to recover the memory layer.
Generally, there are two classes of multi-primary architectures,
shared-nothing architecture and shared-storage architecture. The
former physically partitions the data into dierent shards (e.g. hash,
range, list partitions), and it uses two-phase locking to support
single shard transactions and two-phase commit to support cross-
shard transactions. The example systems include Spanner [
6
,
11
,
33
],
CockroachDB [
28
], and TiDB [
13
]. These systems involve two-
phase commit that may lead to low performance and high latency
for cross-shard transactions. Moreover, they require specifying the
sharding keys (i.e. partition columns and functions) to partition
the data into dierent nodes, but it is dicult to nd appropri-
ate sharding keys especially for complex workloads (e.g. ERP or
CRM), and those sharding keys may only be optimal for a subset of
queries. On the other hand, shared-storage architectures logically
partition pages onto dierent writers, relying on conict detection
and cache coherence mechanisms. The example systems include
Oracle RAC [
25
] and IBM Db2 PureScale [
24
]. They do not disaggre-
gate compute-memory-storage, and have limitations on scale-out
3786
and scale-in abilities [
10
]. We adopt the shared-storage architecture
and extend it to build a cloud-native multi-primary database.
The big challenge for multi-primaryarchitectures is high perfor-
mance transaction management from multiple nodes (detecting the
transaction conicts, guaranteeing consistency, and achieving fast
failure recovery). To address this challenge, we propose a three layer
(compute-memory-storage) disaggregation system
GaussDB
with
ecient and elastic multiple writer capabilities, as shown in Fig-
ure 1. Three-layer disaggregation can make
GaussDB
more elastic
by independently scaling compute, memory and storage resources.
GaussDB
logically partitions the pages into dierent compute nodes,
and each compute node owns a subset of pages. The compute layer
is in charge of SQL optimization and execution, transaction man-
agement, and recovery. For each transaction issued to a compute
node, if all the relevant pages of this transaction are owned by this
compute node, then the compute node can directly process the
transaction; otherwise, the compute node obtains the ownership of
all relevant pages and then processes the transaction. To capture
data anity and reduce page transmission costs,
GaussDB
designs
an eective page placement and query routing method. The mem-
ory layer is in charge of page ownership management (maintaining
a page ownership directory, i.e. the ownership of each page), global
buer management (i.e. warm pages that cannot be maintained
in compute nodes), and global lock management (e.g. the holding
and waiting on global locks). The memory layer is stateless and
can be rebuilt from the compute node state. Most importantly, the
memory layer allows near instant compute elasticity by separating
compute growth and page ownership growth. The storage layer is
responsible for page persistence, log persistence, and failure recov-
ery.
GaussDB
utilizes two-tier failure recovery over both memory
and storage checkpoints. If a compute node is down,
GaussDB
rst
uses a memory checkpoint to recover the node; if the memory layer
fails, then
GaussDB
uses a storage checkpoint. Each compute node
has a log stream and
GaussDB
only utilizes the logs of the failed
compute node and does not need to access the logs of other nodes. If
multiple nodes fail,
GaussDB
employs an ecient parallel recovery
method to simultaneously recover dierent nodes.
In summary,
GaussDB
has several advantages. First,
GaussDB
achieves higher transaction throughput and lower latency with
much fewer aborts compared to storage-layer log transaction con-
ict detection. Second,
GaussDB
achieves much faster recovery.
Third, GaussDB has better scale-out and scale-in ability.
To summarize, we make the following contributions.
(1) We propose a cloud-native multi-primary database system,
GaussDB
, which uses a three layer (compute-memory-storage) dis-
aggregation framework to support multiple writers.
(2) We devise a two-tier (memory checkpoint and storage check-
point) recovery algorithm for fast recovery.
(3) We design a smart page placement method that judiciously
assigns pages to dierent compute nodes and smartly routes queries
to appropriate compute nodes in order to capture data anity.
(4) We have deployed
GaussDB
internally at Huawei and with
customers. The results show that GaussDB achieves higher perfor-
mance and faster recovery, outperforming state-of-the-art baselines.
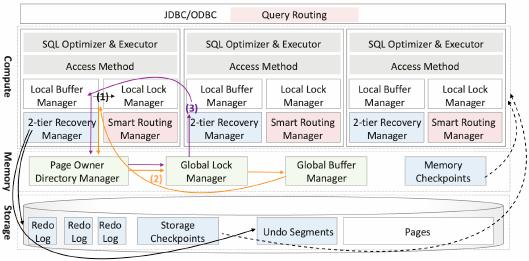
Figure 1: GaussDB Architecture
2 GAUSSDB ARCHITECTURE
GaussDB
has three disaggregated layers: compute, memory and
storage as shown in Figure 1. The compute layer logically and dy-
namically assigns page ownership to dierent compute nodes, and
each compute node manages the pages assigned to the node; the
memory layer provides global shared memory, and holds page own-
ership meta data; and the storage layer provides a globally shared
storage. Compute nodes are in charge of SQL optimization, execu-
tion, and transaction processing. For each transaction on a compute
node, the compute node gets the ownership of all the related pages
and processes them on this node. Memory nodes provide unied
shared memory which maintains global page ownership (i.e. which
compute node owns which page), global buers (i.e. data and index
pages), global locks, and memory checkpoints.
GaussDB
can use
memory checkpoints to accelerate failure recovery. Storage nodes
are responsible for page and log persistence via a POSIX interface
with the shared-storage le system. Storage nodes maintain storage
checkpoints, which are used for failure recovery. The dierence
between a memory checkpoint and a storage checkpoint is that
the former uses the pages in the shared memory and the memory
checkpoint to recover while the latter uses the pages in storage
nodes and the storage checkpoint to recover. Obviously, the for-
mer has faster recovery performance. If memory recovery fails,
GaussDB
uses storage checkpoints to continuously recover. Next
we introduce the GaussDB modules as shown in Figure 2.
Compute Layer. Compute nodes are in charge of transaction pro-
cessing. To support multiple writers, each compute node can modify
any page once it acquires the page ownership. As with standard
write-ahead logging it writes its changes to a redo log stream. To
avoid page conicts, each compute node manages a subset of pages,
that is, each page has an owner node, and only the owner node has
write privileges for this page. If a non-owner node wants to access
a page, the node must get the write/read privilege from the owner
node of this page. Thus, the compute node has a
local buffer
manager
for maintaining the pages it owns in its local buer pool
and a
local lock manager
for access control to these pages. Given
a transaction posed to a compute node, if the node owns all the rele-
vant pages for this transaction (i.e. they all reside in its local buer),
GaussDB
directly processes the transaction using its local buers
and local locks; if the node does not own all the pages, the compute
node needs to nd the pages (via the page ownership directory at
the memory layer) and acquire ownership of these pages.
For recovery, the compute node has a
write-ahead log manager
and a
undo segment manager
for atomicity and durability. Note
3787
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论