




Database · 最佳实践 · 内存索引指南.pdf
免费下载
Database · 最佳实践 · 内存索引指南
背景
如何选择内存索引结构是设计和优化数据库时的一个关键问题。因为无论是内存数据库还是磁盘数据库,内存
索引都是一个至关重要的部分,极大地影响了数据库的性能表现。对于内存数据库,内存索引是读写路径上的
核心结构,而对于磁盘数据库,在服务器内存足以缓存绝大部分热数据的场景下,内存索引可以大幅加速热数
据的读写。
然而,选择合适的内存索引结构并不是一件简单的事情。首先,一直以来内存索引的设计在学术界和工业界都
是一个万家争鸣的局面,内存索引结构的种类非常多,并且没有哪一种索引能在各个方面都实现领先,因此在
选择时就需要根据不同的场景进行权衡。其次,一些内存索引的论文中使用的工作负载与实际应用场景存在一
些差距,或者数据量较小,或者索引键的组成较为简单,仅使用整型或者反转的email地址,因此这些论文中的
评估对索引结构选择的参考价值不大。另外,不同内存索引的实验评估中使用的硬件系统环境和工作负载都不
同,甚至存在较大差异,难以比较它们之间的性能优劣。
因此,给各类内存索引一个“同场竞技”的机会是非常必要的。一方面,在相同的硬件环境和工作负载下对内
存索引进行评估,可以给内存索引的选择提供参考。另一方面,对内存索引的评估也有助于更深入的理解不同
内存索引的设计理念对性能的影响,为设计新的内存索引提供一些启发和借鉴。
在本文中,我们根据一定标准选择了五种内存索引,评估了它们在不同场景下的性能表现。由于内存索引结构
种类很多,对所有的内存索引进行评估显然不可行,因此我们根据如下的标准来选择进行评估的内存索引:
支持数据库的通用语义:随机写入,点查询,范围查询
具有代表性:同一类的内存索引可能有很多变体,比如字典树就有Patricia Trie、ART、HOT等等,我们仅
选择同一类中具有代表性的内存索引结构
已经集成进数据库系统:一些内存索引虽然性能优异,但是存在诸多限制,难以在数据库系统中应用
根据这样的标准,我们选择了Skiplist,BwTree,BTree,Masstree和ART这五种内存索引。我们将它们集成进
了PolarDB X-Engine的MemTable中,使用db_bench评估了它们在不同数据量,不同索引键长度下的随机写
入、点查询、范围查询这几方面的性能表现。
实验评估
实验环境
Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz, 32core 64threads, 2Socket.
L1-Cache:32KB Data Cache,32KB Instruction Cache
L2 Cache:256KB
L3 Cache:32MB
RAM:512GB,2133 MHz DDR4
实验设计
关于我们评估的五种内存索引,其中Skiplist是PolarDB X-Engine的MemTable使用的无锁实现,BwTree是
OpenBwTree这篇paper中的开源实现,In-memory BTree是基于Logical and Physical Versioning的无锁
BTree,Masstree也是论文中的开源实现,ART是我们根据论文实现的。
我们分别使用db_bench的fillrandom,readrandom,seekrandom来评估内存索引的性能,通过系统参数控
制不发生SwitchMemTable和Flush,使用32线程压测一个ColumnFamily。db_bench原有的索引键生成方式
是在64位整型后补ASCII字符0,我们修改了索引键的生成方式,使较长的索引键和数据库中复合索引的键模式
接近,而较短的索引键和数据库中整型索引键一致。
实验结果
点查询
改变数据量
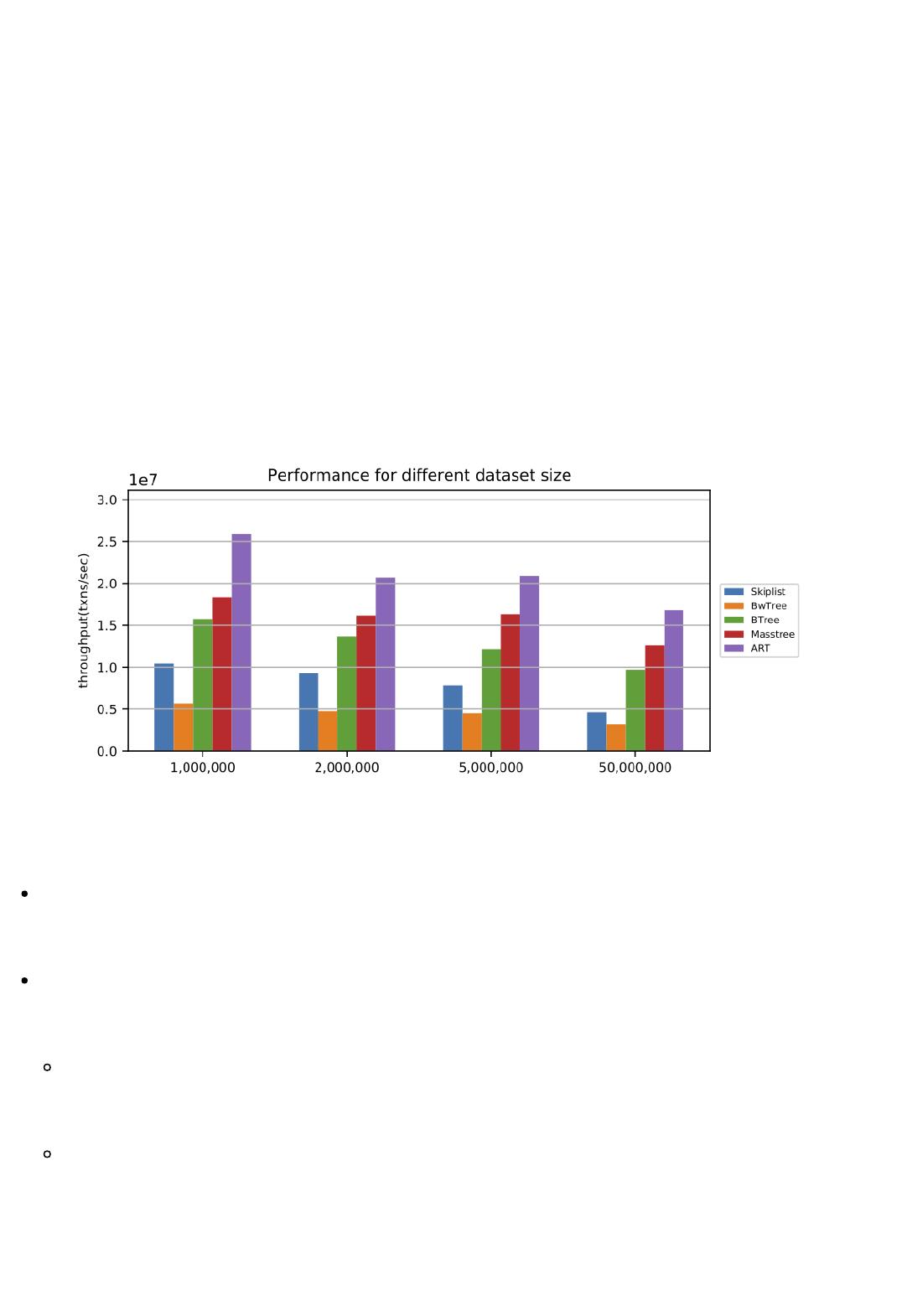
我们使用长度为64Bytes的字符串类型的key和128Bytes的value,测试了五种内存索引在不同数据量大小的场
景下的点查询吞吐(200M-10G,对应1million-50million的键值对)。实验结果显示,五种内存索引中In-
memory BTree,Masstree和ART都能达到千万级别的吞吐,其中ART在不同数据量的场景下性能表现都是最
佳的。
从结果中我们观察到,在我们的测试场景下,ART的点查询性能显著地高于其他的树形索引,我们为此深入研究
了ART的实现,并结合测试负载的特点,认为ART性能突出的原因主要有两点:
数据结构自身查找性能的差距。字典树的查找开销是常量级O(k),而搜索树的查找开销是对数级O(LlogN)。
在较为理想的情况下,一个朴素的字典树,每一层对应key中一个位置的字节,考虑每个节点的扇出最高是
256,最少只需要搜索4层即可覆盖超过40亿个key的索引空间,无论是计算开销还是访存开销都很低。
使用自适应的节点格式,并在不同的节点格式中使用不同的查找方式。字典树中不同的节点可能有不同的扇
出,ART共有四种不同的节点格式:Node4、Node16、Node48和Node256,分别存储不同扇出的节点。
采用这样的设计有两个好处:
提高缓存效率。针对扇出较小的节点,如果统一使用包含256个指针的节点,可能会有较多的空闲空间,
如果使用变长的节点形式,内存分配过程中可能会产生大量的内存碎片。采用不同格式的节点,并预分配
固定的空间,可以在节省内存的同时降低写入时内存分配的开销、减少内存碎片。
可以根据不同格式的节点选择最优的查询方式。除了Node256可以直接通过下标找到子节点的指针外,
其他节点的查询都需要额外开销,这里针对不同格式的节点,选择了合适的查询方式。对于Node4,节点
中最多存储4个字符和4个指针,因为数据量小,只需要顺序遍历即可。对于Node16,节点中最多存储16
个字符和16个指针,可以使用SIMD指令集,在几个CPU cycle内并行比较节点包含的所有字符,找出子
节点的指针。对于Node48,节点中使用一个长度256的uint8数组和最多存储48个指针,uint8数组作为
一个hashmap,将字符映射到指针数组中的对应位置。
of 7
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论