




ClickHouse和他的朋友们(5)存储引擎技术进化与MergeTree.pdf
免费下载

ClickHouse和他的朋友们(5)存储引擎技术进化与
MergeTree
21 世纪的第二个 10 年,虎哥已经在存储引擎一线奋战近 10 年,由于强大的兴趣驱动,这么多年来几乎不放过
arXiv 上与存储相关的每一篇 paper。尤其是看到带有 draft 的 paper 时,有一种乞丐听到“叮当”响时的愉
悦。看paper这玩意就像鉴宝,多数是“赝品”,需要你有“鉴真”的本领,否则今天是张三的算法超越xx,明
儿又是王二的硬件提升了yy,让你永远跟不上节奏zz,湮灭在这些没有营养的技术垃圾中,浪费大好青春。
言归正传,接下来的3篇,跟 ClickHouse 的 MergeTree 引擎有关: 上篇介绍存储引擎的技术演进史,从"远
古"的 B-tree 出发推演到目前主流的技术架构。 中篇会从存储结构介绍 MergeTree 原理,对 ClickHouse
MergeTree 有一个深入的认识,如何合理设计来进行科学加速。 下篇会从MergeTree代码出发,看看
ClickHouse MergeTree 如何实现读、写。
本文为上篇,先来个热身,相信本篇大部分内容对大家来说都比较陌生,很少人写过。
地位
存储引擎(事务型)在一个数据库(DBMS)中的地位如何呢?
MySQL 的商业成功可以说大部分来自于 InnoDB 引擎,Oracle 收购 InnoDB 比 MySQL 早好几年呢!20年
前,能亲手撸一套 ARIES (Algorithms for Recovery and Isolation Exploiting Semantics) 规范引擎,实力还
是相当震撼的,相信 Oracle 收购的不仅是 InnoDB 这个引擎,更重要的是人, InnoDB 作者在哪里,在干什
么?!Fork 出来的 MariaDB 这么多年一直找不到自己的灵魂,在 Server 层磨磨蹭蹭可谓是江河日下,只能四
处收购碰碰运气,当年 TokuDB 战斗过的 commit 依在,但这些已经是历史了。另,WiredTiger 被
MongoDB 收购并使用,对整个生态所起的作用也是无可估量的,这些发动机引擎对于一辆汽车是非常重要
的。
有人问道,都已经 2020 年了,开发一个存储引擎还这么难吗?不难,但是造出来的未必有 RocksDB 好用?!
如大家所见,很多的分布式存储引擎都是基于 RocksDB 研发,可谓短期内还算明智的选择。从工程角度来看,
一个 ACID 引擎要打磨的东西非常之多,到处充斥着人力、钱力、耐心的消耗,一种可能是写到一半就停滞了
(如 nessDB),还有一种可能是写着写着发现跟xx很像,沃茨法克。当然,这里并不是鼓励大家都去基于
RocksDB 去构建自己的产品,而是要根据自己的情况去做选择。
B-tree
首先要尊称一声大爷,这个大爷年方 50,目前支撑着数据库产业的半壁江山。
50 年来不变而且人们还没有改变它的意向,这个大爷厉害的很!鉴定一个算法的优劣,有一个学派叫 IO复杂度
分析,简单推演真假便知。下面就用此法分析下 B-tree(traditional b-tree) 的 IO 复杂度,对读、写 IO 一目了
然,真正明白读为什么快,写为什么慢,如何优化。为了可以愉快的阅读,本文不会做任何公式推导,复杂度
分析怎么可能没有公式呢!
读IO分析
这里有一个 3-level 的 B-tree,每个方块代表一个 page,数字代表 page ID。
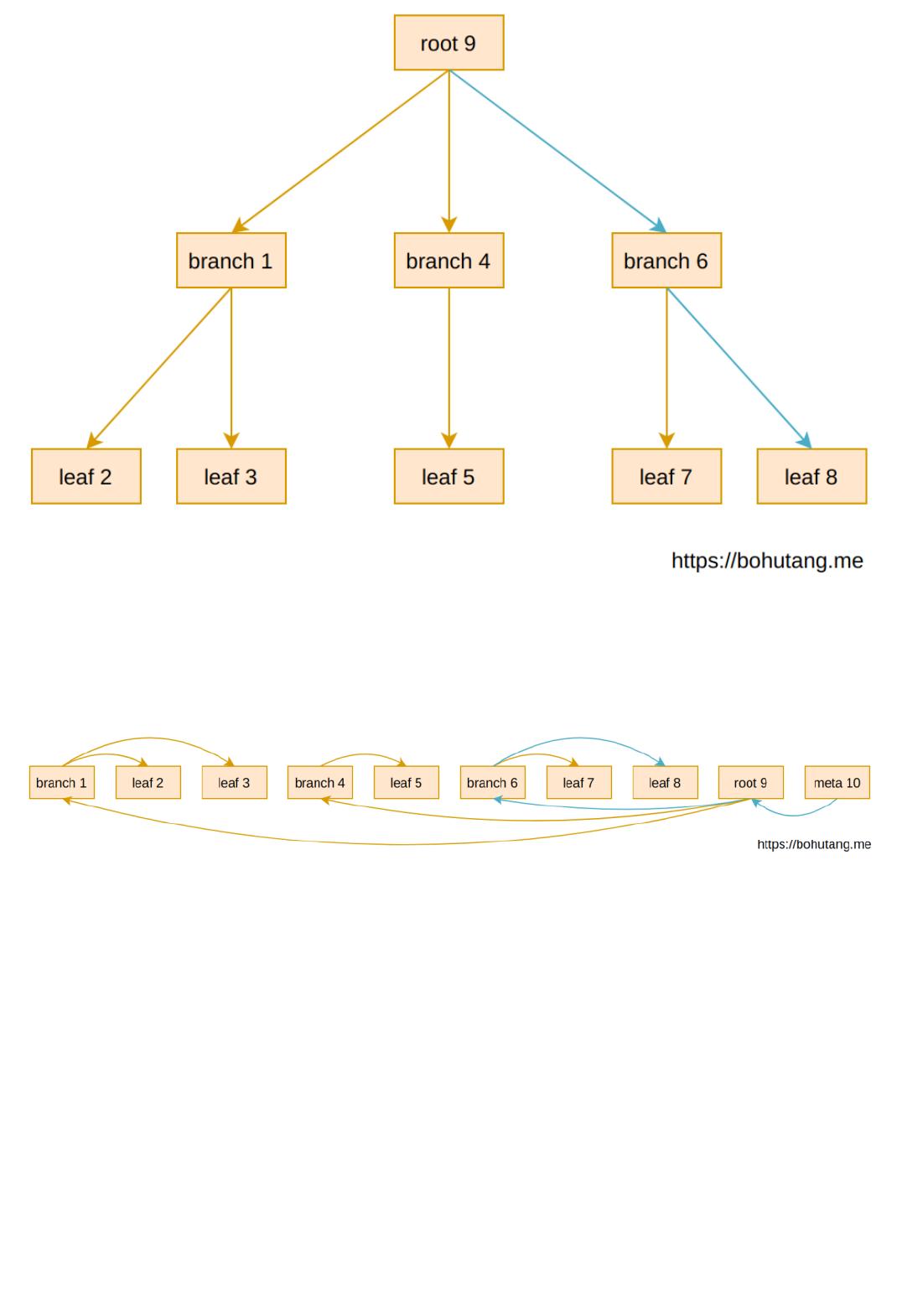
上图 B-tree 结构是内存的一个表现形式,如果我们要读取的记录在 leaf-8上,read-path 如蓝色箭头所示:
root-9 --> branch-6 --> leaf-8
下图是 B-tree 在磁盘上的存储形式,meta page 是起点:
这样读取的随机 IO (假设内存里没有 page 缓存且 page 存储是随机的)总数就是(蓝色箭头):
1(meta-10)IO + 1(root-9)IO + 1(branch-6)IO + 1(leaf-8)IO = 4次 IO,这里忽略一直缓存的 meta 和 root,
就是 2 次随机 IO。如果磁盘 seek 是 1ms,读取延迟就是 2ms。
通过推演就会发现,B-tree 是一种读优化(Read-Optimized)的数据结构,无论 LSM-tree 还是 Fractal-tree 等
在读上只能比它慢,因为读放大(Read Amplification)问题。存储引擎算法可谓日新月异,但是大部分都是在跟
写优化(Write-Optimized)做斗争,那怕是一个常数项的优化那就是突破,自从 Fractal-tree 突破后再无来者
了!
写IO分析
现在写一条记录到 leaf-8。
of 8
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论