




巧用Python对SQL Server数据库批量人员信息数据清洗攻略.docx
免费下载
巧用 Python 对 SQL Server 数据库批
量人员信息数据清洗攻略
一、前置准备:Python 与 SQL Server 数据库的连接
在使用 Python 对 SQL Server 数据库进行批量人员信息数据清洗之前,我们需要安装一些必要的 Python
库,这些库能帮助我们顺利地与数据库建立连接并进行后续的数据处理操作。
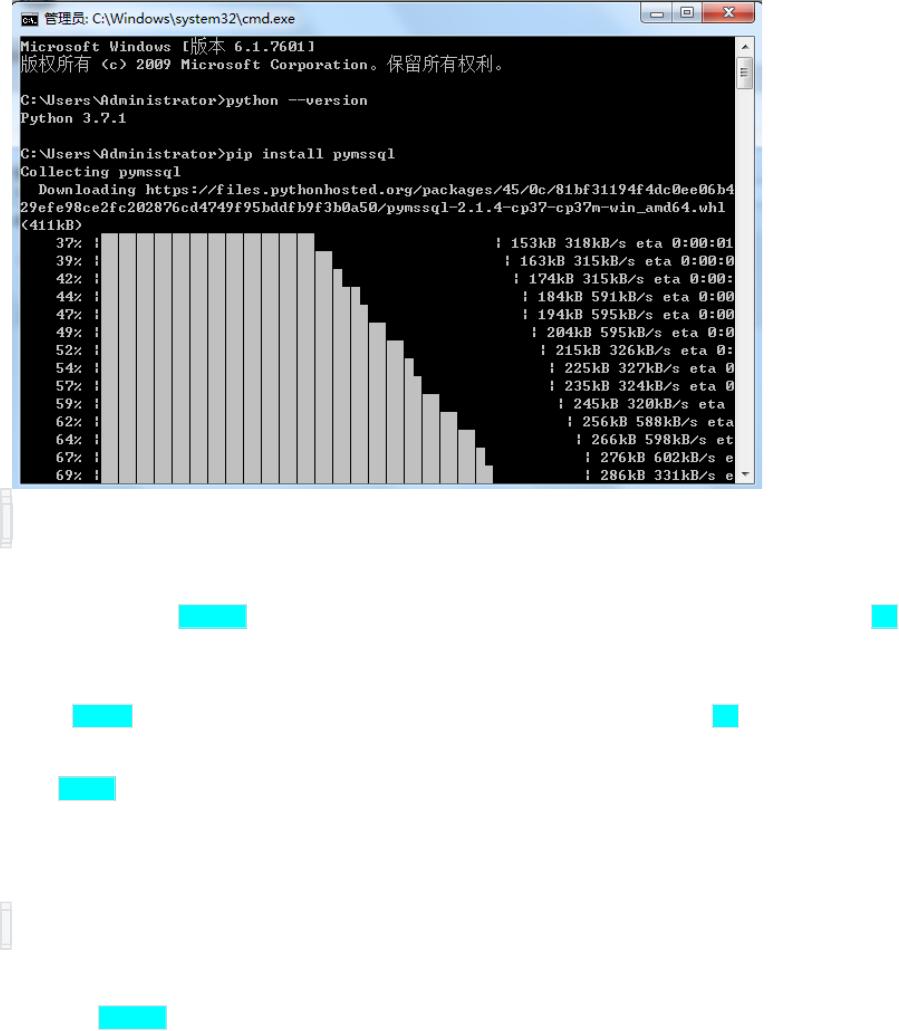
首先,要介绍的是 pymssql 库,它是 Python 连接 SQL Server 数据库常用的库之一。我们可以通过 pip
命令来进行安装,在命令行中输入以下命令即可:
pip install pymssql
另外,pyodbc 库也非常实用,它是 Python 连接各种数据库的通用库,同样使用 pip 命令安装:
pip install pyodbc
还有 pandas 库,它在数据处理和分析方面表现出色,能让我们更方便地对从数据库中获取到的数据进
行清洗等操作,安装命令如下:
pip install pandas
安装好这些库后,我们就为后续连接数据库以及进行数据清洗工作奠定了基础。
在确保所需的库都安装完成后,接下来要创建数据库连接对象,以便能够访问 SQL Server 数据库中的
人员信息数据。
如果使用 pymssql 库来建立连接,示例代码如下:
import pymssql
# 配置服务器名称、数据库名称、用户名和密码等必要连接信息,这里需替换成你实际的信息
server_name = '你的服务器名称'
database_name = '你的数据库名称'
user_name = '你的用户名'
password = '你的密码'
# 创建数据库连接对象
conn = pymssql.connect(server=server_name, user=user_name, password=password, database=database_name)
if conn:
print("连接成功!")
而要是选择 pyodbc 库来连接数据库,代码示例则是这样的:
import pyodbc
# 配置连接信息,同样要替换成实际的服务器、数据库、用户名和密码等
server_name = '你的服务器名称'
database_name = '你的数据库名称'
user_name = '你的用户名'
password = '你的密码'
# 创建连接对象,注意这里的连接字符串格式
conn = pyodbc.connect('DRIVER={SQL Server};SERVER=' + server_name + ';DATABASE=' +
database_name + ';UID=' + user_name + ';PWD=' + password)
if conn:
print("连接成功!")
通过上述代码,依据你选用的库以及正确配置相关的连接信息,就能成功建立起与 SQL Server 数据库
的连接,后续便可以对其中的人员信息数据开展批量数据清洗工作了。
二、数据清洗场景及 Python 实现
(一)删除指定列、重命名列操作
在实际的数据库操作中,有时某些列的数据对于我们后续的分析或应用来说是冗余的,比如一些临时记
录的辅助列、已经过期失去意义的列等,这时候就需要将其删除。在 Python 中,我们可以使用 pandas
库中的 df.drop() 函数来实现删除指定列的操作。以下是示例代码:
import pandas as pd
# 假设我们已经从 SQL Server 数据库中获取到数据并存储在 DataFrame 中,这里模拟一个简单的
DataFrame 示例
data = {'col1': [1, 2, 3], 'col2': ['a', 'b', 'c'], 'col3': [4, 5, 6]}
df = pd.DataFrame(data)
# 使用 df.drop()函数删除列,axis=1 表示操作的是列(axis=0 表示行),inplace=True 表示直接在原
DataFrame 上修改,若为 False 则返回一个修改后的新 DataFrame 副本
df.drop(columns=['col3'], axis=1, inplace=True)
print(df)
在上述代码中,columns 参数指定了要删除的列名列表,我们可以根据实际需求填入想要删除的列名,
从而轻松实现删除指定列的操作,让数据更加精简,便于后续处理。
重命名列在数据处理中也有着重要意义,比如原始数据库中的列名可能是一些缩写或者不够直观清晰的
命名,当我们要进行数据分析或者展示时,将列名修改为更易理解的名称会方便很多。在 Python 里,
利用 df.rename() 函数就可以进行列重命名操作。示例代码如下:
import pandas as pd
# 同样模拟一个简单的 DataFrame 示例
data = {'old_col1': [1, 2, 3], 'old_col2': ['a', 'b', 'c']}
df = pd.DataFrame(data)
# 使用 df.rename()函数进行列重命名,columns 参数传入一个字典,键为原列名,值为新列名
new_column_names = {'old_col1': 'new_col1', 'old_col2': 'new_col2'}
df.rename(columns=new_column_names, inplace=True)
print(df)
通过这样的方式,我们可以按照业务需求灵活地更改列名,使得数据结构在后续的处理和分析中更加清
晰明了。
(二)重复值、缺失值处理
在很多业务场景中,比如人员信息录入时可能因为误操作、系统故障等原因会出现重复记录人员数据的
情况,像重复录入同一个员工的多条相同基本信息等。这时就需要对重复值进行处理。在 Python 中,
我们可以使用 df.drop_duplicates() 函数来去除重复值。以下是示例代码:
import pandas as pd
# 模拟含有重复值的人员信息 DataFrame 示例,这里假设有姓名、年龄、部门三列,其中有重复的人员
记录
data = {'name': ['张三', '李四', '张三', '王五'], 'age': [25, 30, 25, 35], 'department': ['研发', '市场', '研发', '财务']}
df = pd.DataFrame(data)
# 使用 df.drop_duplicates()函数去除重复行,默认会根据所有列来判断重复,可通过 subset 参数指定依据
某些列判断重复
df.drop_duplicates(inplace=True)
print(df)
需要注意的是,使用这个函数时,如果指定了 subset 参数,它会按照指定的列来判断重复情况,并且
默认保留第一次出现的行,删除后面重复的行。根据实际的数据情况合理设置参数,就能准确地去除重
复值了。
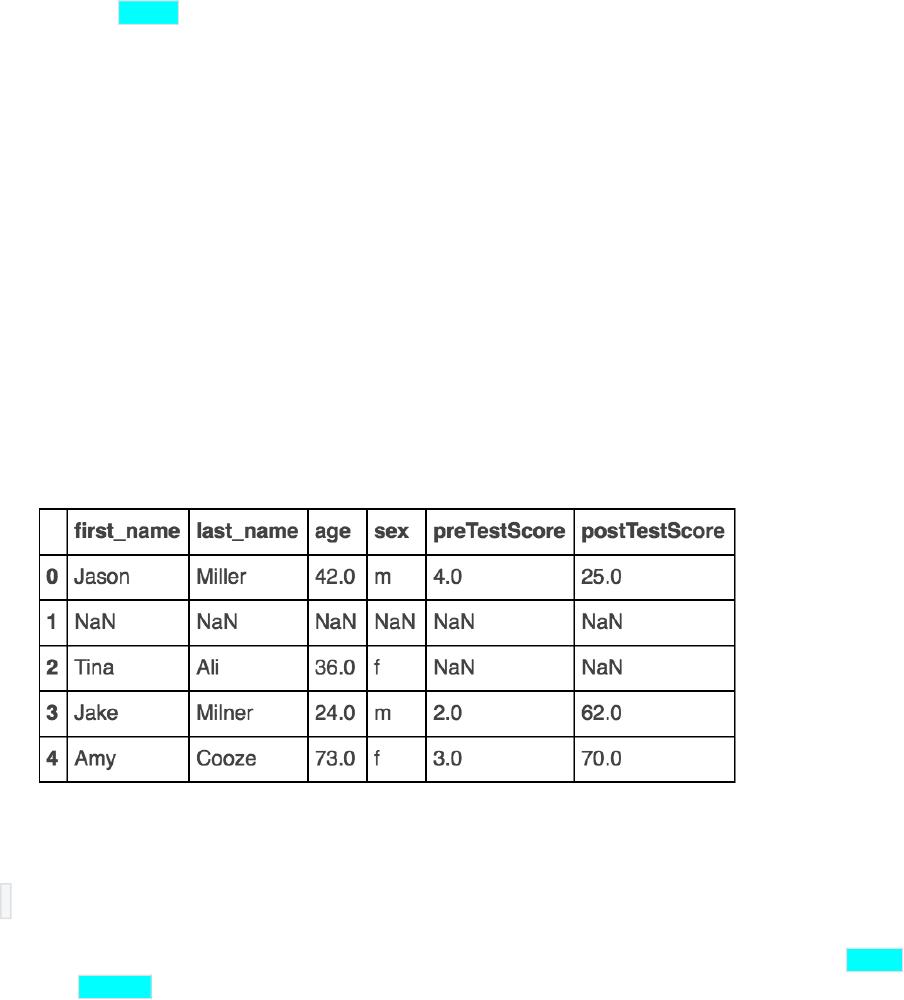
数据库中的人员信息数据可能由于各种原因产生缺失值,比如部分信息未填写完整、数据传输过程中出
现丢失等,而这些缺失值如果不处理,可能会影响后续的数据分析结果准确性,像在计算平均年龄等统
计指标时会出现偏差。在 Python 中,我们可以使用 df.fillna() 等函数来填充缺失值。示例代码如下:
import pandas as pd
# 模拟含有缺失值的人员信息 DataFrame 示例,比如年龄列有部分缺失
data = {'name': ['张三', '李四', '王五'], 'age': [25, None, 35], 'department': ['研发', '市场', '财务']}
df = pd.DataFrame(data)
# 使用 df.fillna()函数填充缺失值,这里以填充固定值为例,将年龄列的缺失值填充为 0,可根据实际情
of 11
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。

文档被以下合辑收录
相关文档
评论