

3



数据库架构高可用性评估.pdf
10墨值下载

数据库基本架构的⾼可⽤性评估
导引
⻢尔可夫模型表示⼀系列随机事件,其中每个事件转换的概率仅取决于前⼀个事件达到的状态。因此,除了前⼀个
事件之外,没有 “记忆”。连续事件的链条称为⻢尔可夫过程 ,如果转换可以随时发⽣,则它是连续的,如果转换只
能在固定时间发⽣,则它是离散的。
在⾼可⽤性系统中,⻢尔可夫模型通常被⽤来分析系统从⼀个状态到另⼀个状态的转变概率,例如从健康状态到故
障状态,或从恢复状态到稳定运⾏状态。不同的数据库架构设计适⽤于不同的业务需求和场景,,例如包括存算分
离、主从复制、多主复制、级联复制、分布式数据库、集群架构、混合架构。
⾼可⽤性(High Availability, HA)是⼀个复杂的系统属性,数据库⾼可⽤性受到多种因素的影响,包括硬件、软
件、⽹络、运维策略等。⽬前,并没有⼀种“通⽤公式”可以完美评估适⽤于各种场景的数据库架构⾼可⽤性,但可
以结合⻢尔可夫模型等理论和⽅法,构建⼀个综合的⾼可⽤性评估模型。⽤于计算系统的稳态可⽤性(Steady-
State Availability, SSA),也可作为⾼可⽤性评估的通⽤公式:
可⽤状态
=
其中 :P**i(∞) 是系统在稳态时处于可⽤状态 i 的概率;MTBF:平均⽆故障时间,MTTR:平均修复时间。对于⼀
个包含多个组件的系统,可以使⽤⻢尔可夫链的状态转移矩阵来计算系统的稳态概率分布,进⽽评估系统的可⽤
性。
!
1.存算分离架构 <4^9
存算分离架构将存储和计算资源解耦,⽀持独⽴扩展和弹性伸缩 。其SSA由存储层和计算层的可⽤性共同决定,
典型架构
计算节点:负责处理业务逻辑和数据计算,通过⽹络访问存储层的数据。
存储节点:独⽴于计算节点,提供⾼可⽤性和持久化能⼒。
架构图说明,下同。
箭头:表示数据流向或通信路径。
节点:代表不同的计算或存储单元。
括号中的内容:表示节点的主要功能或存储的数据类型。
+----------------+ ! ! ! +----------------+
| ! ! ! ! ! ! ! | ! ! ! | ! ! ! ! ! ! ! |
| Compute Node |<----->| Storage Node |
| (Compute) ! ! | ! ! ! | (Storage) ! ! |
| ! ! ! ! ! ! ! | ! ! ! | ! ! ! ! ! ! ! |
+----------------+ ! ! ! +----------------+
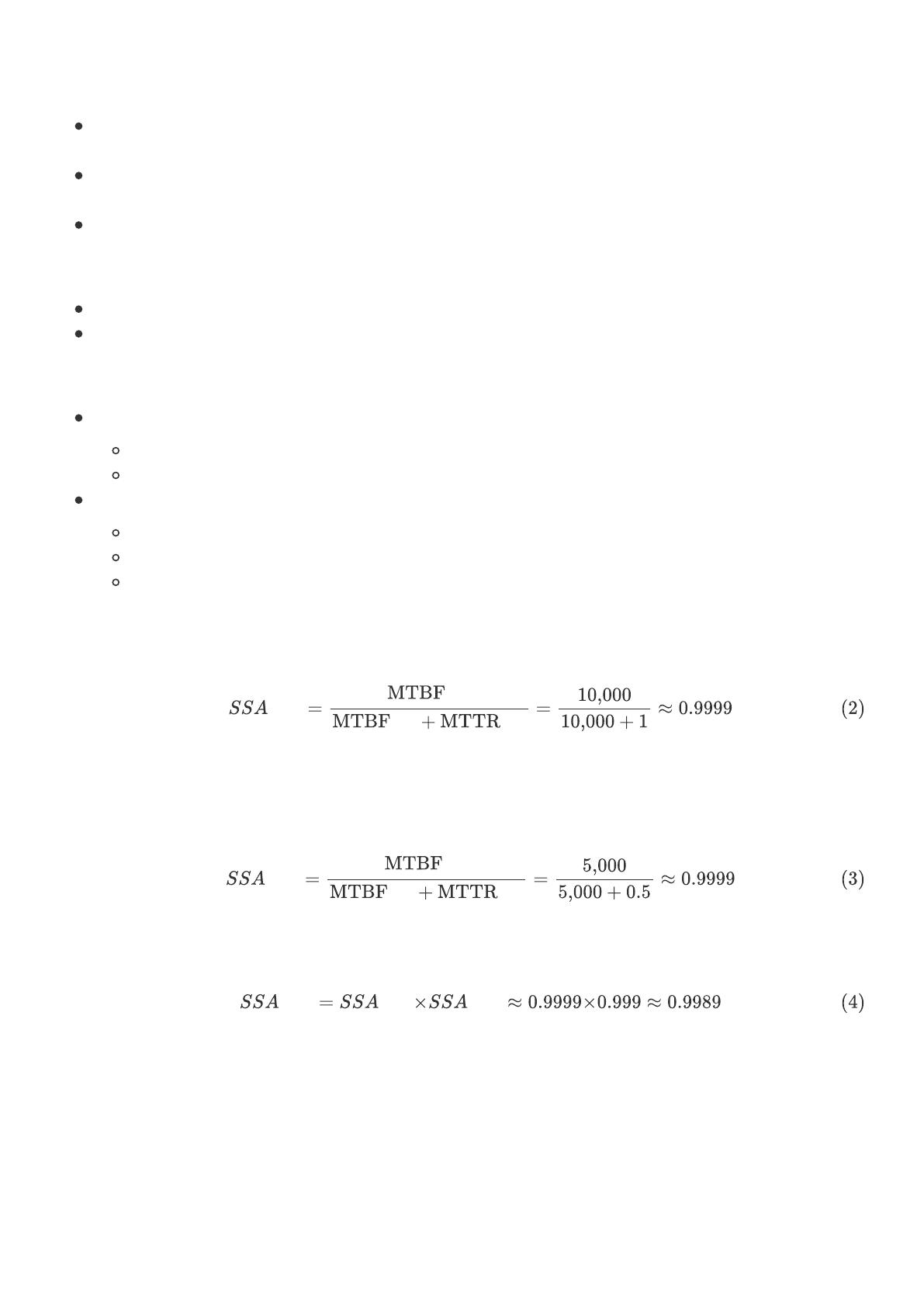
架构特点
存储资源(如分布式⽂件系统、对象存储)独⽴于计算资源,通常部署在专⻔的存储节点上,⽀持多副本存
储和⾃动故障恢复。
计算资源(如数据库实例、计算节点)独⽴于存储资源,可以灵活扩展,计算节点故障时,可以快速重新分
配计算任务到其他节点
存储和计算资源可以独⽴扩展,根据实际需求灵活配置,⽀持按需分配资源,提⾼资源利⽤率和成本效益。
适⽤场景
适⽤于云原⽣环境和⼤数据处理场景。
适⽤于需要⾼可⽤性和弹性伸缩的场景。
稳态⾼可⽤性(SSA)计算
存储层:
使⽤分布式⽂件系统(如HDFS、CEPH)或对象存储(如S3)。
存储节点的MTBF为10,000⼩时,MTTR为1⼩时。
计算层:
使⽤⽆状态计算节点,⽀持动态扩展。
计算节点的MTBF为5,000⼩时,MTTR为0.5⼩时。
计算节点通过⽹络访问存储层的数据,⽀持负载均衡和故障转移。
假设存储层和计算层的故障是独⽴的,系统的整体可⽤性可以表示为存储层和计算层可⽤性的乘积。
1. 存储层的SSA:
存储
存储
存储 存储
!
2. 计算层的SSA:
!
存储
存储
存储 存储
!
3. 系统的整体SSA:
系统 存储 计算
!
!
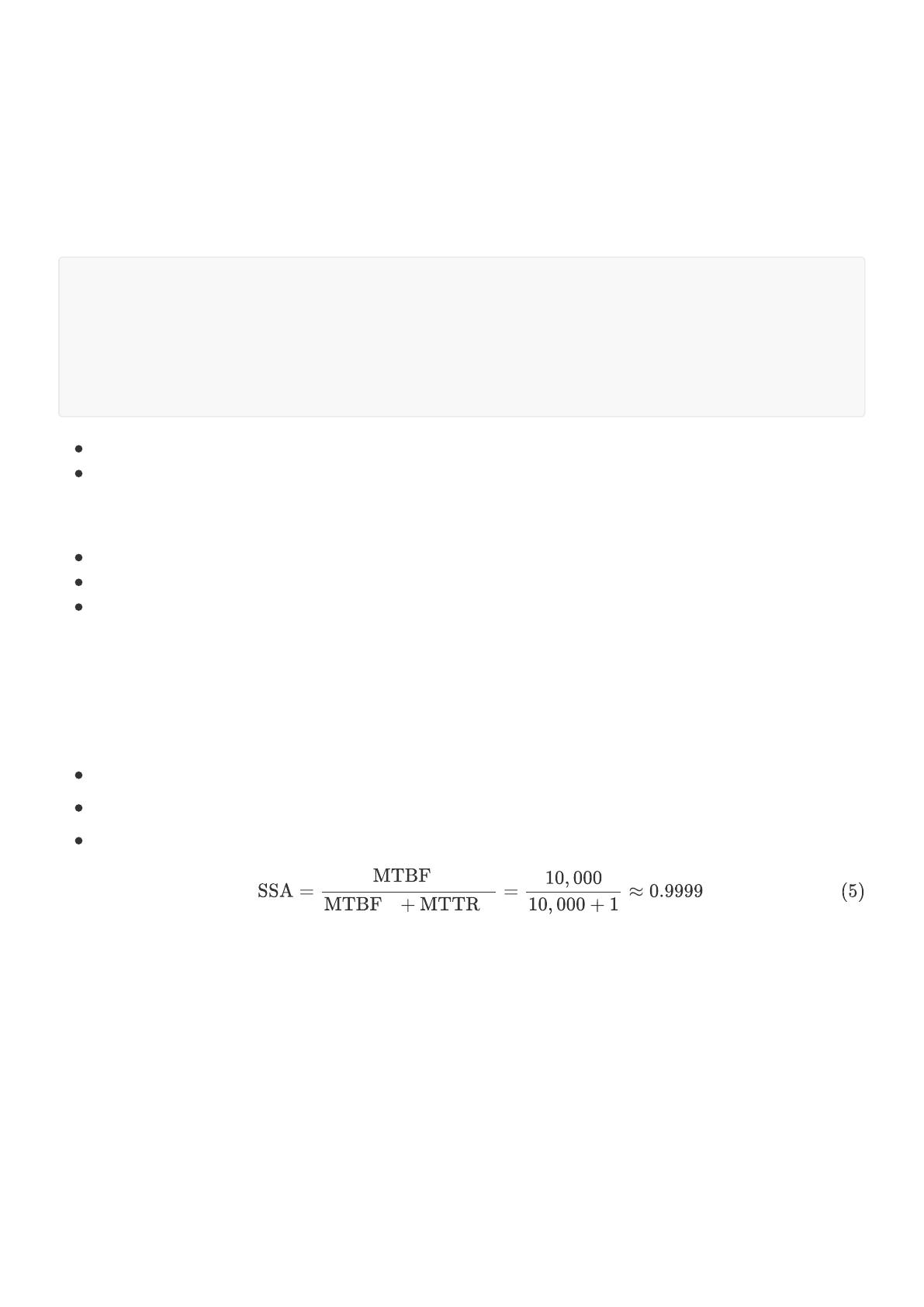
2. 主从复制架构~4^9
主从复制架构是最基本的⾼可⽤性设计,包含⼀个主节点负责所有写操作和部分读操作,以及⼀个或多个从节点通
过异步或同步复制接收数据。这种架构简单易实现,适⽤于读多写少的场景,但写操作的可⽤性依赖于主节点的稳
定性。其稳态⾼可⽤性(SSA)主要由主节点的MTBF和MTTR决定。
典型架构
主节点:负责所有写操作和部分读操作。
从节点:通过异步或同步复制从主节点接收数据,⽤于分担负载和提供故障转移能⼒。
架构特点
⼀个主节点(Master)负责处理所有写操作和部分读操作。
⼀个或多个从节点(Slave)通过异步或同步复制从主节点接收数据,⽤于分担负载和提供故障转移能⼒。
主节点故障时,从节点可以接管服务。
适⽤场景
适⽤于对数据⼀致性要求较⾼的场景,但写操作的可⽤性依赖于主节点。
稳态⾼可⽤性(SSA)计算
MTBF:主节点MTBF为10,000⼩时,从节点MTBF为5,000⼩时。
MTTR:主节点MTTR为1⼩时,从节点MTTR为0.5⼩时。
SSA:假设主节点故障时,从节点可以⽴即接管,系统的SSA主要由主节点的MTBF和MTTR决定。
主
主 主
!
3. 多主复制架构~6^9
多主复制架构允许多个主节点,每个节点都可以独⽴处理写操作,数据通过逻辑复制在节点间同步。这种架构⽀持
多活部署,适⽤于跨地域或多数据中⼼的分布式环境,能够显著提⾼系统的可⽤性和容错能⼒,任⼀主节点的故障
不会导致整个系统故障。
+----------------+ ! ! ! +----------------+
| ! ! ! ! ! ! ! | ! ! ! | ! ! ! ! ! ! ! |
| Master Node ! |<------| Slave Node ! |
| (Write) ! ! ! | ! ! ! | (Read) ! ! ! |
| ! ! ! ! ! ! ! | ! ! ! | ! ! ! ! ! ! ! |
+----------------+ ! ! ! +----------------+
of 9
10墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
神州飞象 PM
最新上传
下载排行榜
1
2
白鳝-DBAIOPS:国产化替换浪潮进行时,信创数据库该如何选型?.pdf
3
centos7下oracle11.2.0.4 rac安装详细图文(虚拟机模拟多路径).docx
4
PostgreSQL 缓存命中率低?可以这么做.doc
5
李飞-AI 引领的企业级智能分析架构演进与行业实践.pdf
6
达梦数据2024年年度报告.pdf
7
刘杰-江苏广电:从Oracle+Hadoop到TiDB,数据中台、实时数仓运维0负担.pdf
8
Sunny duan-大模型安全挑战与实践:构建 AI 时代的安全防线.pdf
9
Agent 元年,关于知识管理的新思考.pdf
10
AI 开发工具的过去现在和将来-施乔.pdf

文档被以下合辑收录
相关文档
评论