




计算机行业定期报告:Deepseek发布全新注意力机制NSA.pdf
免费下载
证
券
研
究
报
告
计算机
2025
年
02
月
23
日
诚信专业 发现价值
1
请务必阅读报告末页的声明
计算机
Deepseek 发布全新注意力机制 NSA
投资要点:
Deepseek 发布全新注意力机制 NSA
NSA(硬件优化稀疏注意力机制)由 Deepseek、北京大学和华盛顿大
学联合提出,旨在解决传统注意力机制在长上下文、多轮对话等场景下的
性能瓶颈。其创新性在于通过**三并行分支架构**(Token 压缩、Token 选
择、滑动窗口)结合可学习门控机制,动态平衡全局与局部注意力:压缩
分支粗粒度捕捉全局信息,选择分支筛选关键稀疏单元以减少计算量,滑
动窗口则保留局部语法与语义连贯性;硬件层面基于 Triton 框架优化内存
访问,通过组共享 KV 数据、高带宽 HBM 与片上 SRAM 协同计算,显著
提升稀疏计算效率。该技术实现了推理速度与精度的平衡,适用于大语言
模型加速、长文档理解等需要高效长程依赖建模的场景。
本周 AI 数据更新:
海外应用看,20250214-20250220 期间,Chatgpt 下载量逐步回升,
Gemini、Perplexity 和 Claude 整体保持稳定。
国内应用看,20250214-20250220 期间,Deepseek 下载量稍有回落,
Kimi、通义、星火、文心一言整体保持稳定,腾讯元宝接入 Deepseek 后下
载量显著提升,现已超过 30 万次/日。
风险提示
市场需求不及预期,人工智能技术发展不及预期,政策发布不及预期
等。
强于大市
(维持评级)
一年内行业相对大盘走势
团队成员
分析师:
钱劲宇
(S0210524040006)
QJY3773@hfzq.com.cn
相关报告
1、美 AI 禁令或将升级——2025.01.13
2、把握 2025 年两大核心主线——2025 年计算机
行业投资策略报告——2025.01.07
3、通用汽车退出 Robotaxi 业务,特斯拉或被寄予
厚望——2024.12.15
华福证券
华福证券

诚信专业 发现价值
2
请务必阅读报告末页的声明
行业定期报告 | 计算机
正文目录
1 Deepseek 发布全新注意力机制 NSA .............................................................................. 3
2 AI 数据更新 ........................................................................................................................4
3 风险提示 ............................................................................................................................5
图表目录
图表 1: NSA 架构概览 ......................................................................................................3
图表 2: NSA 内核设计 ......................................................................................................4
图表 3: 海外应用本周下载量 ...........................................................................................4
图表 4: 海外应用年初至今下载量 .................................................................................. 4
图表 5: 国内应用本周下载量 ...........................................................................................5
图表 6: 国内应用年初至今下载量 .................................................................................. 5
华福证券
华福证券
诚信专业 发现价值
3
请务必阅读报告末页的声明
行业定期报告 | 计算机
1 Deepseek 发布全新注意力机制 NSA
2 月 18 日,Deepseek、北京大学和华盛顿大学提出全新注意力机制 NSA。相对
于传统的注意力机制,NSA 是一种硬件优化的稀疏注意力机制,适用超长上下文、多
轮对话等场景,能够在保证性能的同时显著提升推理速度。
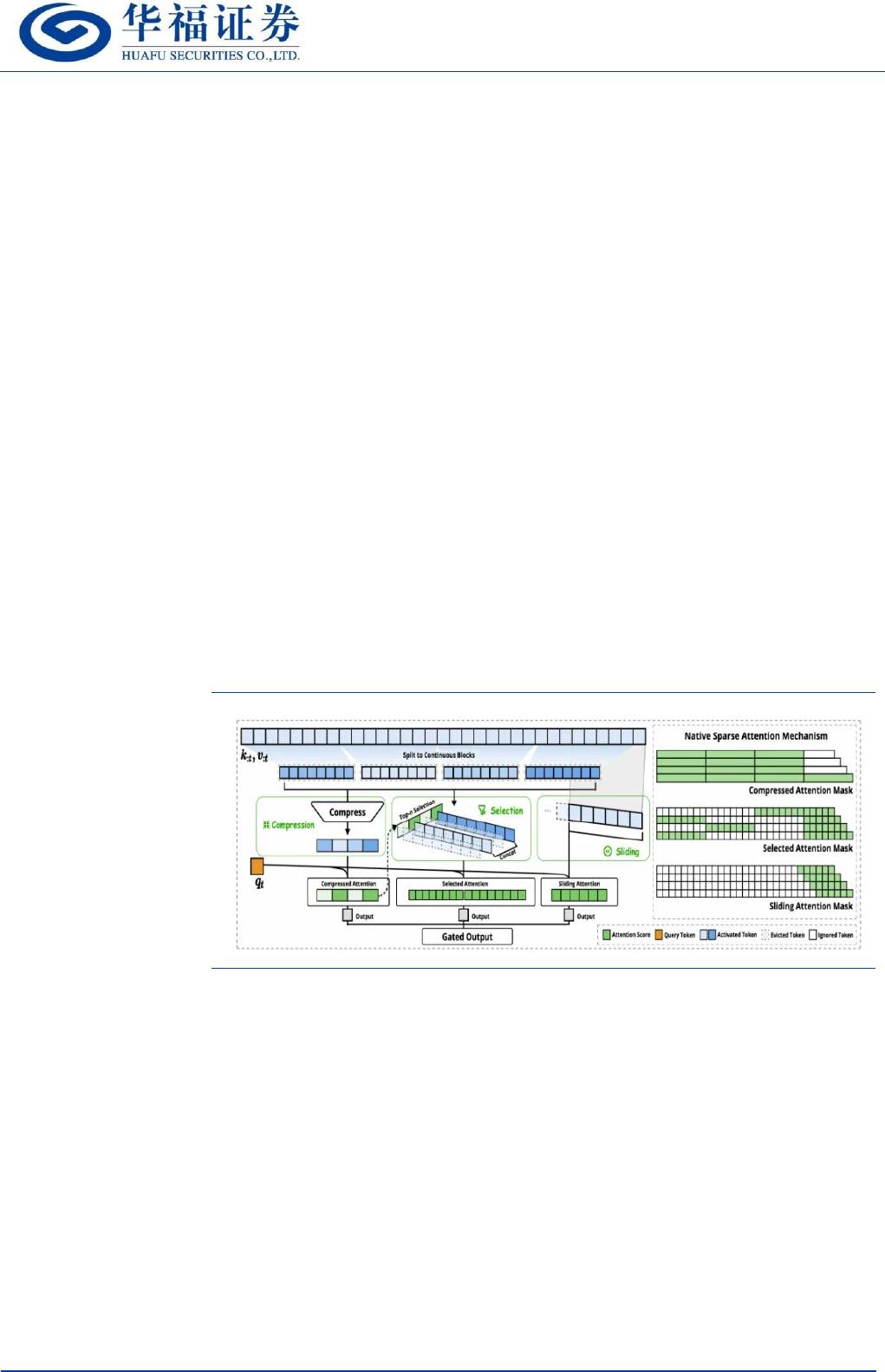
NSA 通过三个并行的注意力分支处理序列实现,包含 token 压缩、token 选择
和滑动窗口三部分。
1、 token 压缩:将连续的键或值块聚合为块级表示,得到压缩后的键和值。这
种粗粒度压缩帮助模型获取全局信息
2、 token 选择:用于识别并保留最相关的 token,同时减少计算开销。这里通
过计算压缩块的分数,从高到低排序来判断各个块级表示的重要性。在里面
选择 top-�稀疏区块中的 token 进行细粒度的 tokens 计算。
3、 滑动窗口:用于处理局部上下文信息,保障语法连贯性和语义完整性。
同时,NSA 通过可学习的门控机制,将三个注意力分支单独计算,并调整他们的
权重,进而实现全局和局部注意力的动态平衡。
图表 1:NSA 架构概览
来源:新智元,华福证券研究所
硬件层面上通过 Triton 实现了硬件对齐的稀疏注意力内核。内核设计上采用了
以下策略:
1、 查询加载(Grid Loop):内核按组策略加载 Queries。每个 GQA 组共享 KV。
这种方法减少了冗余的键值传输,提高了内存访问效率。
2、 键值获取(Inner Loop):在每个查询加载后,内核提取相应的稀疏 KV 块。
这些 KV 块存储在高带宽内存(HBM)中。在计算时传输到片上静态随机存取
存储器(SRAM)中。
3、 注意力计算:内核在 SRAM 中执行注意力计算。绿色块表示存储在 SRAM 中的
数据,蓝色块表示存储在 HBM 中的数据。这种内存层次结构优化了数据传输
华福证券
华福证券
of 6
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。

相关文档
评论